
包阅导读总结
1. `AlphaFold 3`、`分子结构预测`、`数据库`、`模型架构`、`扩散模型`
2. 本文介绍了 AlphaFold 3 预测生命分子结构和相互作用的情况。由于建全功能数据库不可行,推出了免费工具 AlphaFold Server。为适应更广泛的生物分子,扩展训练数据,模型架构也有改变,但产生新问题,团队借助 AlphaFold 2 解决。
3.
– AlphaFold 3
– 构建面临困难:建全功能数据库不可能
– 解决方案:推出免费工具 AlphaFold Server,供科学家输入序列生成分子复合物,自 5 月推出已生成超 100 万结构
– 改进与创新
– 扩展训练数据,涵盖 DNA、RNA 等
– 模型架构变化,最终生成结构部分使用基于扩散的生成模型
– 新问题与解决
– 扩散模型对蛋白质无序区域预测不准确
– 借助 AlphaFold 2 预测的结构进行训练,让 AlphaFold 3 学会预测无序区域
思维导图: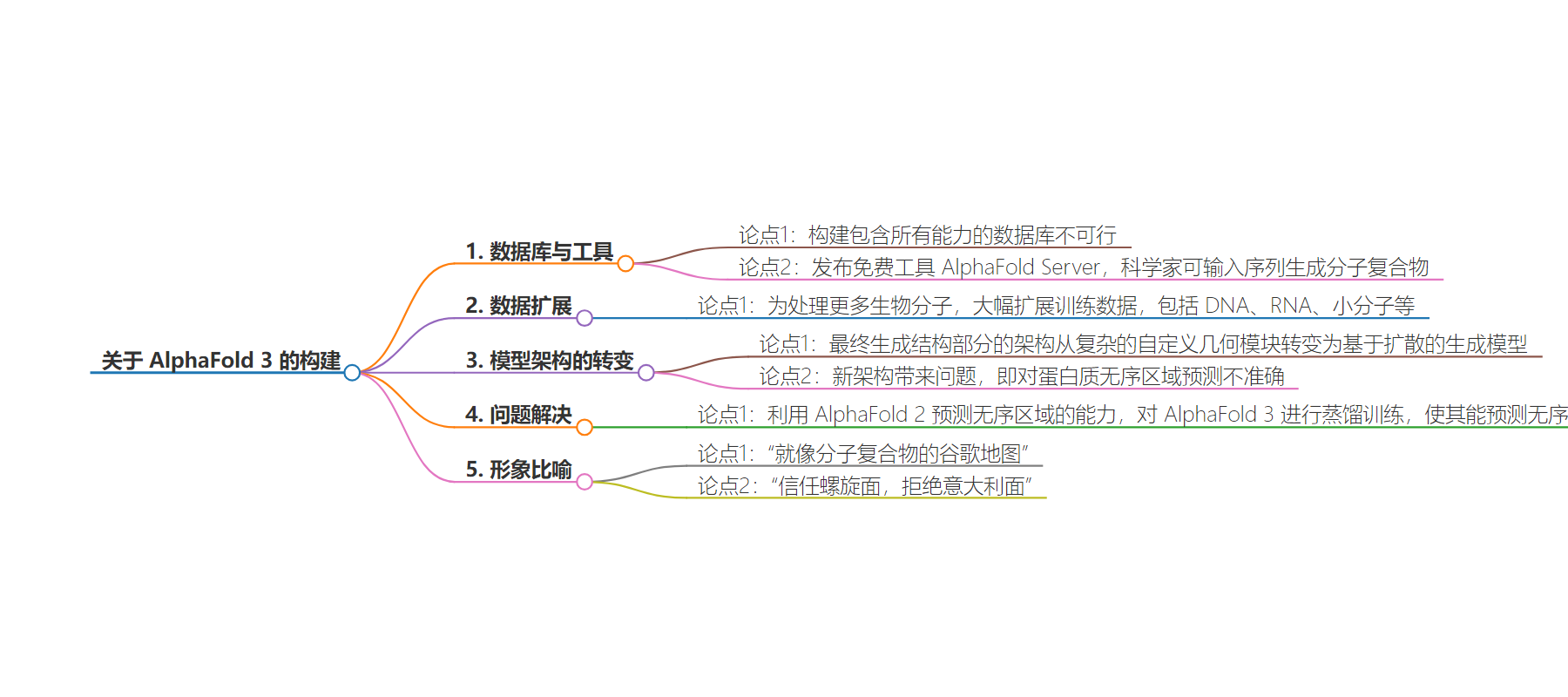
文章地址:https://blog.google/technology/ai/how-we-built-alphafold-3/
文章来源:blog.google
作者:Chaim Gartenberg
发布时间:2024/7/16 16:00
语言:英文
总字数:835字
预计阅读时间:4分钟
评分:89分
标签:阿尔法折叠,生物学中的 AI,分子结构预测,药物设计,生物分子
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
That meant making a database with all the capabilities would have been impossible. Instead, we’ve released AlphaFold Server, a free tool that lets scientists plug in their own sequences that AlphaFold can then generate molecular complexes for. Since launching in May, researchers have already used it to generate over 1 million structures.
“It’s like Google Maps for molecular complexes,” says Lindsay Willmore, research engineer at Google DeepMind. “Any user who doesn’t know how to code at all can just copy and paste the sequences of their proteins, DNA, RNA or the name of their small molecule, press a button and wait a few minutes. Their structure and the confidence metrics will come out so that they’re able to look at and evaluate their prediction.”
In order to get AlphaFold 3 to work with this much wider range of biomolecules, the team vastly expanded the data that the newer model was trained on to include DNA, RNA, small molecules and more. “We were able to say, ‘Let’s just train on everything that exists in this dataset that helped us so much with proteins and let’s see how far we can get,’” Lindsay says. “And it turns out we can get pretty far.”
Another major change in AlphaFold 3 is a shift in architecture for the final part of the model that generates the structure. Where AlphaFold 2 used a complex custom geometry-based module, AlphaFold 3 uses a generative model that’s based on diffusion — similar to our other cutting-edge image generation models, like Imagen — which greatly simplified how the model handles all the new molecule types.
That shift led to a new issue, though: Since so-called “disordered regions” of proteins weren’t included in the training data, the diffusion model would try to create an inaccurate “ordered” structure with a defined spiral shape, instead of predicting disordered regions.
So the team turned to AlphaFold 2, which is already extremely good at predicting which interactions would be disordered — which look like a pile of chaotic spaghetti — and which ones were not. “We were able to use those predicted structures from AlphaFold 2 as distillation training for AlphaFold 3, so that AlphaFold 3 could learn to predict disorder,” Lindsay says.
“We have a saying: ‘Trust the fusilli, reject the spaghetti,’” adds Jonas.