
包阅导读总结
1. 关键词:LLM 推理加速、Attention 优化、GPU、Decode 阶段、RTP-LLM
2. 总结:本文基于 RTP-LLM 实践,介绍 LLM 推理 decode 阶段 Attention 在 GPU 上的优化,包括计算流程、任务划分、性能瓶颈及应对场景,还提及了 MMHA 优化的方向,优化后的 kernel 会开源。
3. 主要内容:
– LLM 推理加速需求
– 大语言模型广泛应用,低成本构建高吞吐、低延迟推理服务成紧迫问题
– 延时优化分解及 RTP-LLM
– 延时分解为 GEMM 和 Attention 的 kernel 优化
– RTP-LLM 是大模型推理加速引擎,已广泛应用于阿里内部
– Decode 阶段 Attention 计算及优化
– 计算流程,包括 Q 与 K、V Cache 计算等
– 以 TensorRT-LLM 中 MMHA 实现为例,分析高性能实现方式
– 任务划分及每个 block 计算方式
– 性能瓶颈及应对场景
– 小 B 和长 S 场景,改变任务划分增加 occupancy
– 超长 seq 需在 seq 做切分
– GQA 场景改变资源分配
– MMHA 优化方向及开源
– 优化寄存器用量等
– 优化后的 kernel 开源在 RTP-LLM 中
思维导图: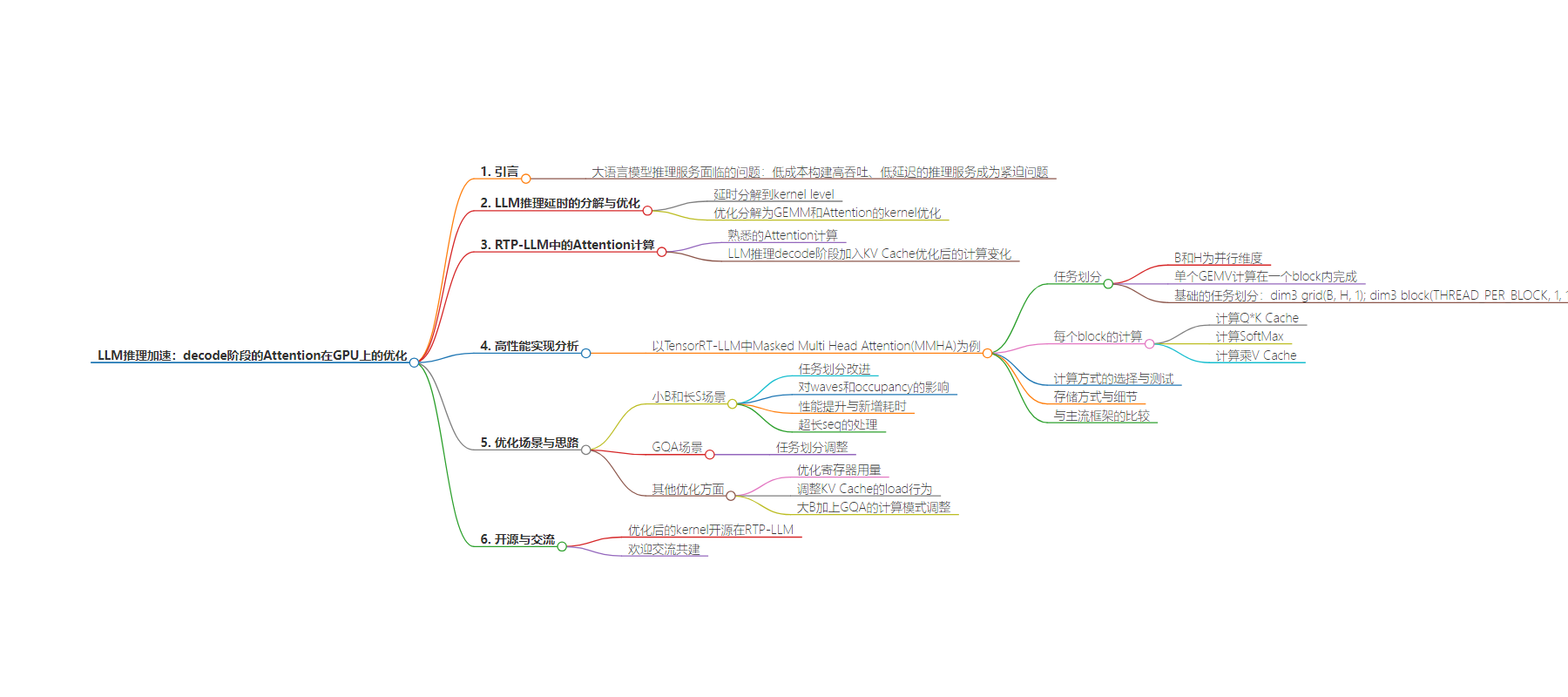
文章地址:https://mp.weixin.qq.com/s/Sek1cnmPshuk9kK-XR59iw
文章来源:mp.weixin.qq.com
作者:董纪莹
发布时间:2024/7/25 8:45
语言:中文
总字数:3647字
预计阅读时间:15分钟
评分:89分
标签:LLM推理优化,GPU并行计算,Attention机制,KV Cache,TensorRT-LLM
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

这是2024年的第53篇文章
( 本文阅读时间:15分钟 )
随着大语言模型(Large Language Models,LLMs)在各领域的广泛应用,如何以低成本构建高吞吐、低延迟的推理服务成为了一个紧迫的问题。考虑到LLM在GPU上推理时参数量和计算量较大以致于单流执行就可以充分利用GPU资源,我们可以把LLM的推理延时分解到kernel level,因此,进一步的,不考虑时间占比小的kernel计算后,LLM的延时优化也就相应的分解成GEMM和Attention的kernel优化。
RTP-LLM是阿里巴巴智能引擎团队开发的大模型推理加速引擎,作为一个高性能的大模型推理解决方案,它已被广泛应用于阿里内部。在这篇文章里,我们将基于RTP-LLM的实践,介绍decode阶段的Attention在GPU上是如何优化的。
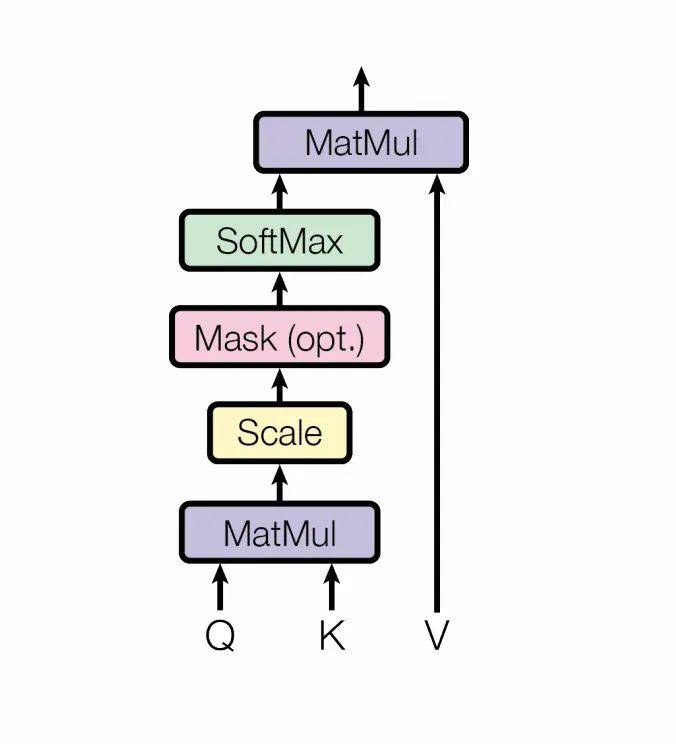
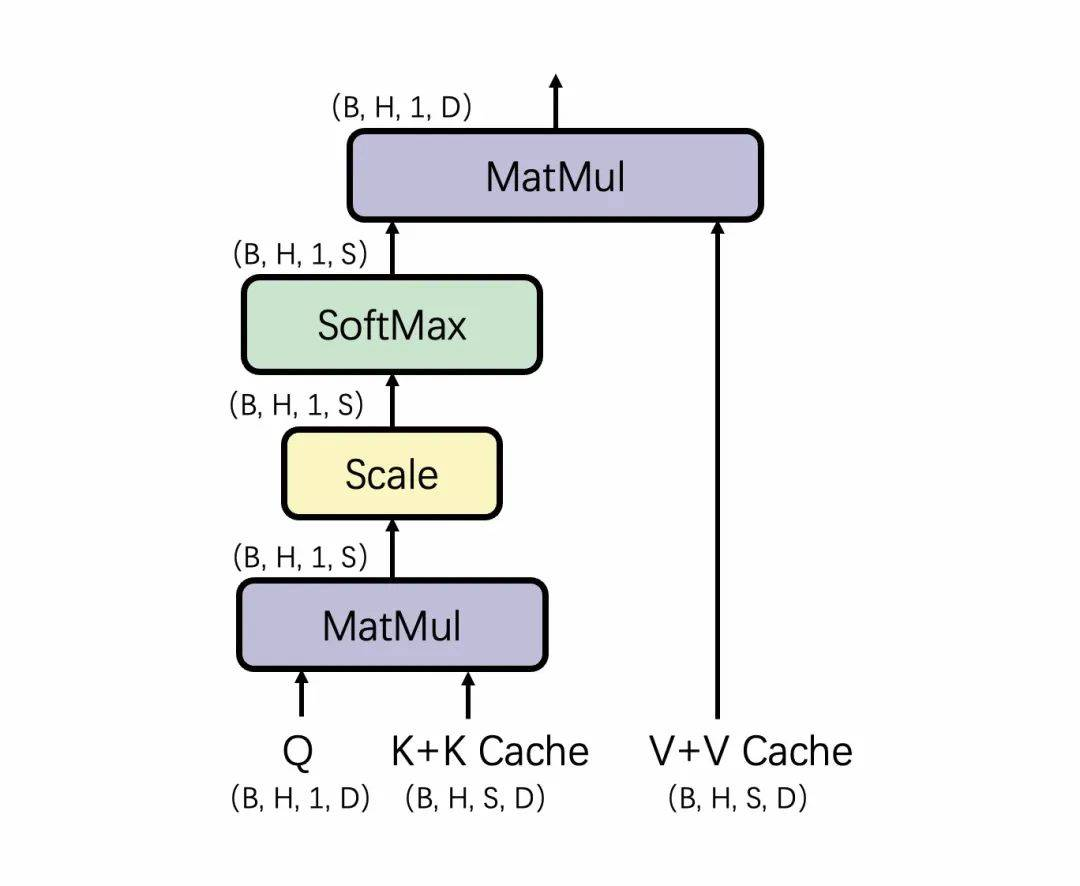
Q, K, V = add(QKV_buffer, bias)Q, K = rotary_embedding(Q, K)K, V = concat(past_KV, K, V)res = matmul(Q, K)/ sqrt(self.head_dim)res = =softmax(res, dim=-1)out = matmul(res, V)在整个计算过程中,BiasAdd、Rotary Embedding相对计算量较小,对kernel的latency影响较小,因此下文省略这一部分的分析。 我们以当前的TensorRT-LLM中Masked Multi Head Attention(MMHA)的实现为例,分析当前的MMHA是怎么实现高性能。 涉及到GPU并行计算,我们首先需要考虑的是任务划分。对于这个场景,任务划分实际上是清晰的:B和H是并行维度,在执行过程中的Q*K和QK*V,都可以理解成一个batch size = B * H的Batch GEMV。而SoftMax又是一个Reduce操作,因此单个GEMV的计算最好尽量在一个block内完成。因此,MMHA比较基础的任务划分大概是: dim3 grid(B, H, 1);dim3 block(THREAD_PER_BLOCK, 1, 1);这里的THREAD_PER_BLOCK是指每个block用多少threads来完成一个head在S上的计算。通常更多的threads会更提高每个SM的active warps以更好的利用计算资源,增加load指令以提高数据load效率,因此我们希望THREAD_PER_BLOCK越大越好(最好接近1024)。但由于kernel整体计算逻辑较为复杂,寄存器用量较大,threads可能会收到寄存器总量的限制;且在寄存器总量的限制下,我们可以简单的认为每个SM上只有一个active block。 基于这种划分,我们继续考虑每个block是如何计算。传入kernel的QKV buffer实际的layout是(B,3, H,D),在TensorRT-LLM的实现中,会先load当前step的Q和K并计算BiasAdd和ROPE,并将这一步得到的K Cache写回global buffer。完成这些计算后,因为数据还在寄存器中,会直接计算对应的QK dot。由于这些计算的耗时较短,我们略过这一部分分析,直接看看TensorRT-LLM是怎么计算Q * K Cache的。 Q乘K Cache的计算在D上累加。假设我们用half存KV Cache,用float做乘累加,为了保证load效率,每个thread会load连续的16bytes数据,也就是8个elements。对于常见的D==128来说,需要16个threads完成一个head的计算。可以认为给block中的threads进行了分组,每组16个threads负责一个head的计算,其中每个threads读8个elements,并完成这8个elements对应的乘累加,然后这组threads间通过warp内的shuffle完成当前head的计算,并将计算结果存到smem中。组和组在S上展开。
接下来计算SoftMax,由于前面的计算保证了SoftMax需要的输入都在当前block内的smem中,通过Block Reduce Max和Block Reduce Sum就可以完成SoftMax的计算。 乘V Cache的计算思路与上文乘K Cache非常类似,略有不同的是这一步计算需要在S上累加。依然将threads分组,每组16个threads负责一个head, 每个thread负责8个elements的计算。由于需要在S上累加,因此每个thread需要保存当前所计GPUsde算的8个elements的部分累加和。最后借助smem,将不同threads上的部分和累加,得到Attention的输出。
在计算过程中,qk dot除了hfma计算外,也可以调用hmma来完成单个head的计算。但由于kernel的性能瓶颈在访存上,dot用哪种计算方式对性能的影响不大;我们的测试也验证了这个结论。 上文的分析中依然省略了一些细节。具体的,比如我们现在通常用paged KV Block Array来存储KV Cache,也就是KV Cache可以在S维度上不连续,以便在S不断增长时动态的分配buffer。但paged的存储并不改变D维的连续,因此也不影响上文的分析。此外,每个thread在load KV Cache时会多load一部分存进本地的寄存器,以尽可能的将load数据与dot计算overlap。 主流框架如vllm,xformers等对MMHA的实现和优化思路都是比较类似的,仅在细节处略有差异。TensorRT-LLM在mmha外还实现了XQA以继续优化decode阶段Attention的计算,但由于代码未开源,本文也不做分析。 当然上文分析到的简单优化在实际应用中还是不那么够用的,最常见的就是小B和长S场景。 考虑到实际的GPU资源,如A100有108个SM,且每个SM上只有一个block(也就是只计算一个head),当B * H恰好占满108(或108的整数倍)个SM时,可以认为占用率是比较高的。以7B模型,或者72B模型2TP举例,H = 32,当B = 3时,占用率是88.9%;而当B = 4时,就会因必须打两轮而带来占用率的下降到59%;当B = 1时,占用率就会低到30%了。这个时候如果S比较大,我们就会发现,大部分的device资源还空闲着,也不得不一起等待部分SM完成一个时间很长的计算。 针对这种情况,我们把S也分配到grid dim上,资源分配也就改为: dim3 grid(B, H, S_tile);dim3 block(THREAD_PER_BLOCK, 1, 1);在这种任务划分下,结合上文分析,假设长seq每个SM上仅有一个active block,则waves可以计算为:
当waves越接近ceil值,意味着device occupancy会越高。在小B大S的场景下,如果在S切分,也就是S_tile > 1,有利于增加occupancy。在这种情况下,S_tile个block共同完成一个head在S上的计算,每个block负责S / S_tile的计算,block间的reduce通过开辟额外的global buffer来完成。这种模式下,新增的global读写会带来有额外的耗时,但因为增加了device occupancy,因此在小B大S的场景下有明显的性能提升。这也就是flashdecoding的思路,且在各框架均有支持。 除了性能的考虑外,超长seq也必须走进这种实现。由于Q * K的结果需要在S上做reduce,也就是smem需要存下对应大小的中间数据,根据kernel实现,输入类型是half,以float累加,可以估计算为6 * S。而根据A100每个SM实际可用smem是163KB计算,最大可支持的S在27K左右。当输入大于这个值时,我们必须在seq做切分,以保证kernel的计算。 另一种需要做不同的任务划分的场景是GQA。在GQA的计算下,每个head的KV Cache会对应于多个head的Q,为了避免KV Cache的重复load,资源分配应该改为,并基于此做计算上的调整。 dim3 grid(B, H_kv, S_tile);dim3 block(THREAD_PER_BLOCK, 1, 1);除了优化任务划分,MMHA的优化还可以在以下方面继续展开: 1)优化寄存器用量可能达到更高的占用率(可以在一个SM上launch多个block或者增大每个block的threads); 2)继续调整KV Cache的load行为,让计算和数据读取进一步overlap以缓解memory bound的场景; 3)在大B加上GQA,Attention会走到compute bound,需要调整计算模式以更好的利用tensor core加速计算等等。 我们将持续探索和实践,以更灵活、更具拓展性的优化策略来面对日益多样化和复杂的应用场景。优化后的kernel会开源在RTP-LLM中,欢迎大家交流共建。 https://github.com/NVIDIA/TensorRT-LLM [02]vllm
https://github.com/vllm-project/vllm
[03]xformers
https://github.com/facebookresearch/xformers
[04]flash decoding
https://crfm.stanford.edu/2023/10/12/flashdecoding.html
[03]RTP-LLM
https://github.com/alibaba/rtp-llm