
包阅导读总结
1. `GPT-4o mini`、`OpenAI`、`成本效益`、`安全措施`、`模型评估`
2. OpenAI 于 7 月 18 日推出 GPT-4o mini 模型,它具有成本效益,在多项评估中表现出色,内置安全措施,并将逐步向各类用户开放。
3.
– GPT-4o mini 推出
– 7 月 18 日发布,是具成本效益的小型模型。
– 免费、Plus 和团队用户即日起可访问,企业用户下周开始访问。
– 性能与优势
– MMLU 评估得分 82%,聊天偏好优于 GPT-4 早期版本。
– 定价低于前沿模型和 GPT-3.5 Turbo。
– 支持多种任务,上下文窗口为 128K token,知识截止至 2023 年 10 月。
– 分词器处理非英语文本更高效,未来将支持多模态输入输出。
– 模型评估
– 在学术基准测试中超越 GPT-3.5 Turbo 等,在推理、数学编码、多模态推理等方面表现出色。
– 函数调用表现好,但执行影响用户操作前建议建立确认流程。
– 安全措施
– 预训练和后训练阶段采取措施,经过自动化和人类评估。
– 新技术改进安全性,将持续监控使用情况。
思维导图: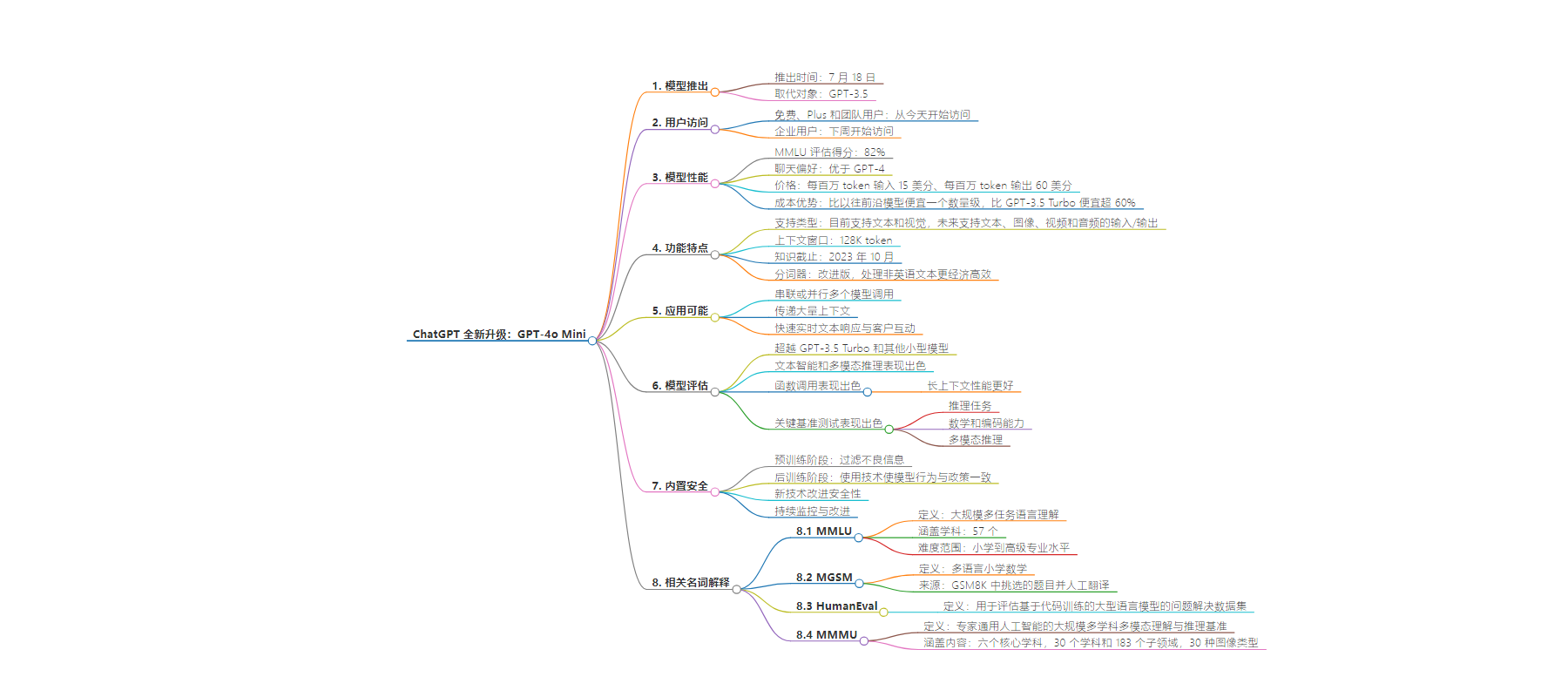
文章地址:https://mp.weixin.qq.com/s/BKFhHAFHfUtSm2AoFk2lKw
文章来源:mp.weixin.qq.com
作者:lencx
发布时间:2024/7/18 22:03
语言:中文
总字数:2877字
预计阅读时间:12分钟
评分:91分
标签:GPT-4o mini,OpenAI,多模态模型,成本效益,模型升级
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
OpenAI 致力于使人工智能广泛可及(OpenAI 生态布局:GPT-4o 免费或许只是一个开始…),7月 18 日宣布推出其最具成本效益的小型模型—— GPT-4o mini[1]。在 ChatGPT 中,免费、Plus 和团队用户将从今天开始可以访问 GPT-4o mini,取代 GPT-3.5。企业用户也将从下周开始访问。
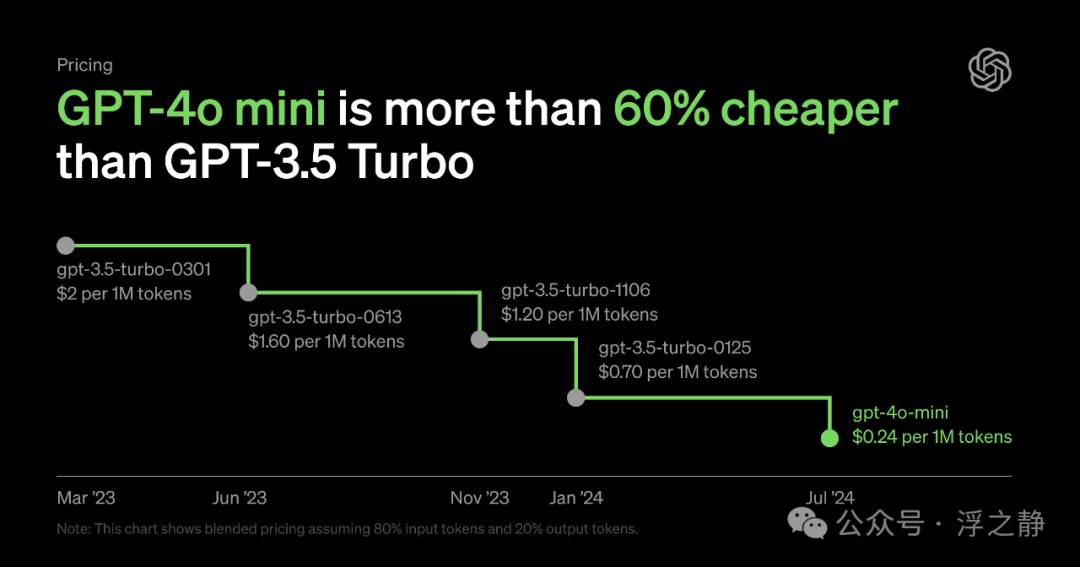
GPT-4o mini 在 MMLU 评估中得分为 82%,并在 LMSYS 排行榜[2]上的聊天偏好中优于 GPT-4(截至 2024 年 7 月 18 日,早期版本的 GPT-4o mini 在性能上优于 GPT-4T 01-25)。其定价为每百万 token 输入 15 美分、每百万 token 输出 60 美分(大约相当于标准书籍中的 2500 页),比以往的前沿模型便宜一个数量级,且比 GPT-3.5 Turbo 便宜超过 60 %。这一价格使得开发者可以更经济实惠地构建和扩展其 AI 应用。
📌
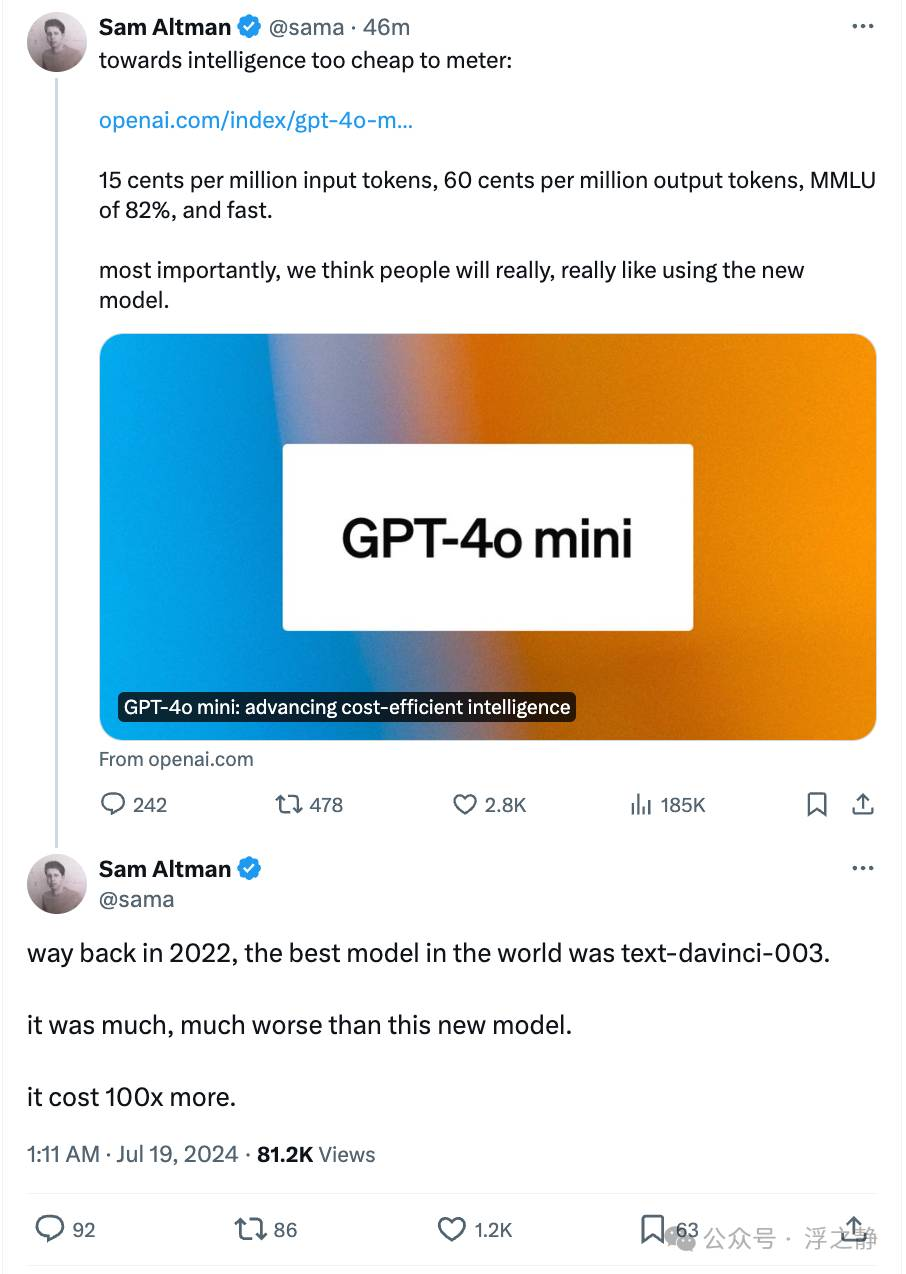
在 2022 年,世界上最好的模型是 text-davinci-003。它比 GPT-4o mini 差很多,其成本是 GPT-4o mini 的 100 倍。
无限可能
GPT-4o mini 凭借其低成本和低延迟,使一系列广泛的任务成为可能,例如串联或并行多个模型调用(如调用多个 API),向模型传递大量上下文(如完整的代码库或对话历史),或通过快速、实时的文本响应与客户互动(如机器人客服)。
目前,GPT-4o mini API 支持文本和视觉,在未来将支持文本、图像、视频和音频的输入/输出。该模型的上下文窗口为 128K token,知识截止至 2023 年 10 月。得益于与 GPT-4o 共享的改进版分词器(tokenizer),在处理非英语文本时更加经济高效。
📌 tiktoken
tiktoken[3] 是 OpenAI 开源的一个快速分词器。当给定一个文本字符串(如
“tiktoken is great!”)和一种编码方式(如“cl100k_base”),分词器可以将文本字符串拆分为一系列 token(如[“t”,“ik”,“token”,“ is”,“ great”,“!”])。将文本字符串拆分为 token 是有用的,因为 GPT 模型以 token 的形式查看文本。知道一个文本字符串中有多少 token 可以告诉你:
查看示例,了解更多 How to count tokens with tiktoken[4]
模型评估
GPT-4o mini 在学术基准测试中超越了 GPT-3.5 Turbo 和其他小型模型,在文本智能和多模态推理方面表现出色,并支持与 GPT-4o 相同范围的语言。它在函数调用(Function calling[5])方面表现出色,让开发者可以构建出从外部系统获取数据或执行操作的应用。与 GPT-3.5 Turbo 相比,在长上下文也具有更好的性能。
📌 函数调用
是指将大型语言模型连接到外部工具。在 API 调用中,可以描述函数,让模型智能地选择输出包含调用函数所需参数的 JSON 对象。最新的模型(如 gpt-4o、gpt-4-turbo 和 gpt-4o-mini)已经被训练为能够检测何时需要调用函数,并生成符合函数签名的 JSON。由于这种能力带来的潜在风险,建议在执行影响用户的操作(如发送邮件、发布内容或进行购买)之前,建立用户确认流程。
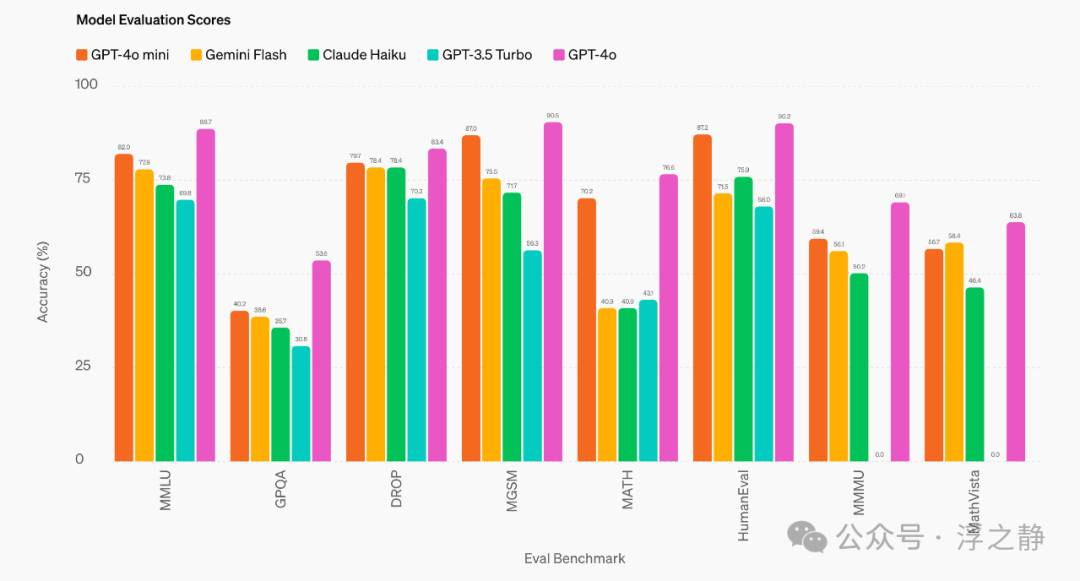
GPT-4o mini 在几个关键基准测试中表现出色:
-
•推理任务:GPT-4o mini 在涉及文本和视觉的推理任务中优于其他小型模型,在文本智能和推理基准 MMLU 中得分为 82.0%,相比之下,Gemini Flash 为 77.9%,Claude Haiku 为 73.8%。
-
•数学和编码能力:GPT-4o mini 在数学推理和编码任务中表现出色,优于之前市场上的小型模型。在衡量数学推理的 MGSM 中,GPT-4o mini 得分为 87.0%,相比之下,Gemini Flash 为 75.5%,Claude Haiku 为 71.7%。在衡量编码性能的 HumanEval 中,GPT-4o mini 得分为 87.2%,相比之下,Gemini Flash 为 71.5%,Claude Haiku 为 75.9%。
-
•多模态推理:GPT-4o mini 在多模态推理评估 MMMU 中也表现出色,得分为 59.4%,相比之下,Gemini Flash 为 56.1%,Claude Haiku 为 50.2%。
作为模型开发过程的一部分,OpenAI 与一些值得信赖的合作伙伴合作,以更好地了解 GPT-4o mini 的用例和限制。在与 Ramp[6] 和 Superhuman[7] 等公司合作时,他们发现 GPT-4o mini 在从收据文件中提取结构化数据或在提供线程历史时生成高质量电子邮件响应等任务中,比 GPT-3.5 Turbo 表现更好。
📌 名词解释
•MMLU[8]:(Massive Multitask Language Understanding,大规模多任务语言理解)。由 Hendrycks 等人在《Measuring Massive Multitask Language Understanding[9]》中提出的 MMLU 是一个新的基准测试,旨在通过在零样本和少样本设置中评估模型来测量预训练过程中获得的知识。这使得基准测试更具挑战性,更类似于我们评估人类的方式。该基准涵盖了 STEM、人文学科、社会科学等 57 个学科,难度从小学水平到高级专业水平不等,并测试了世界知识和问题解决能力。学科范围包括传统领域,如数学和历史,以及更专业的领域,如法律和伦理。学科的细粒度和广泛性使得该基准非常适合识别模型的盲点。
•MGSM[10]:(Multilingual Grade School Math,多语言小学数学)由 Shi 等人在《Language Models are Multilingual Chain-of-Thought Reasoners[11]》中提出的多语言小学数学基准(MGSM)是一个包含小学数学问题的基准测试。它包括从 GSM8K 中挑选的 250 道题目,这些题目由人工注释者翻译成 10 种语言。GSM8K(Grade School Math 8K)是一个包含 8.5K 道高质量、语言多样化的小学数学文字题的数据集。该数据集旨在支持需要多步骤推理的基本数学问题的问答任务。
•HumanEval[12]:由 Chen 等人在《Evaluating Large Language Models Trained on Code[13]》中提出的 HumanEval 是一个用于评估基于代码训练的大型语言模型的问题解决数据集。该评估工具用于测量从文档字符串(docstrings)合成程序的功能正确性。HumanEval 包含 164 个原创编程问题,评估语言理解、算法和简单数学能力,其中一些问题类似于简单的软件面试问题。
•MMMU[14]: (A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI,专家通用人工智能的大规模多学科多模态理解与推理基准)。这是一个新的基准,用于评估多模态模型在需要大学水平学科知识和深思熟虑推理的大规模多学科任务中的表现。MMMU 包括 11.5K 个精心收集的多模态问题,这些问题来自大学考试、测验和教材,涵盖了六个核心学科:艺术与设计、商业、科学、健康与医学、人文与社会科学、技术与工程。这些问题跨越了 30 个学科和 183 个子领域,包含 30 种高度异质的图像类型,如图表、图示、地图、表格、乐谱和化学结构。与现有基准不同,MMMU 专注于高级感知和领域特定知识的推理,挑战模型执行类似于专家面临的任务。对 14 个开源 LMM 以及专有的 GPT-4V(ision) 和 Gemini 的评估突显了 MMMU 所带来的重大挑战。即使是先进的 GPT-4V 和 Gemini Ultra 也仅分别达到了 56% 和 59% 的准确率,表明还有很大的改进空间。
内置安全
OpenAI 从一开始,就在模型中内置了安全措施,并在开发过程的每一步都进行了强化。在预训练阶段,过滤掉不希望模型学习或输出的信息,例如仇恨言论、成人内容、主要聚合个人信息的网站和垃圾邮件。在后训练阶段,使用人类反馈的强化学习(RLHF)等技术,使模型的行为与 OpenAI 的政策保持一致,以提高响应的准确性和可靠性。GPT-4o mini 具有与 GPT-4o 相同的内置安全措施,并经过自动化和人类评估,符合 OpenAI 的承诺(Moving AI governance forward[15])。超过 70 名外部专家测试了 GPT-4o,以识别潜在风险,OpenAI 已经解决了这些问题,并将在即将发布的 system card 和 Preparedness scorecard 中分享这些细节。还使用研究指导的新技术(The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions[16])改进了 GPT-4o mini 的安全性,使其更能抵御越狱、提示注入和系统提示提取。OpenAI 将继续监控 GPT-4o mini 的使用情况,并在识别到新风险时进行改进。
References
GPT-4o mini: https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence
[2]LMSYS 排行榜: https://chat.lmsys.org
[3]tiktoken: https://github.com/openai/tiktoken
[4]How to count tokens with tiktoken: https://github.com/openai/openai-cookbook/blob/main/examples/How_to_count_tokens_with_tiktoken.ipynb
[5]Function calling: https://platform.openai.com/docs/guides/function-calling/function-calling
[6]Ramp: https://ramp.com
[7]Superhuman: https://superhuman.com/plp/brand-v1
[8]MMLU: https://paperswithcode.com/dataset/mmlu
[9]Measuring Massive Multitask Language Understanding: https://arxiv.org/abs/2009.03300v3
[10]MGSM: https://paperswithcode.com/dataset/mgsm
[11]Language Models are Multilingual Chain-of-Thought Reasoners: https://arxiv.org/abs/2210.03057v1
[12]HumanEval: https://paperswithcode.com/dataset/humaneval
[13]Evaluating Large Language Models Trained on Code: https://arxiv.org/abs/2107.03374
[14]MMMU: https://paperswithcode.com/paper/mmmu-a-massive-multi-discipline-multimodal
[15]Moving AI governance forward: https://openai.com/index/moving-ai-governance-forward
[16]The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions: https://arxiv.org/abs/2404.13208