
包阅导读总结
1. 缓存算法、广告检索、性能优化、淘汰顺序、命中率
2. 本文围绕广告检索系统的性能优化展开,介绍了引入缓存解决性能长尾退化的尝试,对多种缓存算法进行测评,包括LRU、LFU等,还阐述了操作系统缓存策略和SsdEngine的缓存架构及工作流程,最后对缓存效果进行了评估。
3.
– 广告检索系统性能优化的背景
– 性能长尾影响KPI和收入,需优化成本和性能
– 基于SSD分级存储,尝试引入缓存解决性能长尾退化
– 缓存的业务必要性
– 适用于访问性能差且有显著局部性的场景
– 广告检索业务特点决定需要缓存技术
– 缓存算法
– LRU:根据最近使用情况淘汰数据,存在不足和应对方法
– LFU:根据访问频率淘汰数据,实现复杂
– Redis的近似LRU和LFU算法
– 操作系统的Double Clock算法
– SsdEngine的缓存架构
– 分层缓存:TLS缓存和中心缓存的协作
– Flying优化:减少重复拉取,降低访盘量
– ARC原理及自适应实现
– 存储对象的缓存配置和切换
– 中心缓存淘汰算法:多种实现形式
– 效果评估
– 以命中率为核心评价指标
– 评测环境和数据
– 对局部访问和轮流访问的评测
思维导图: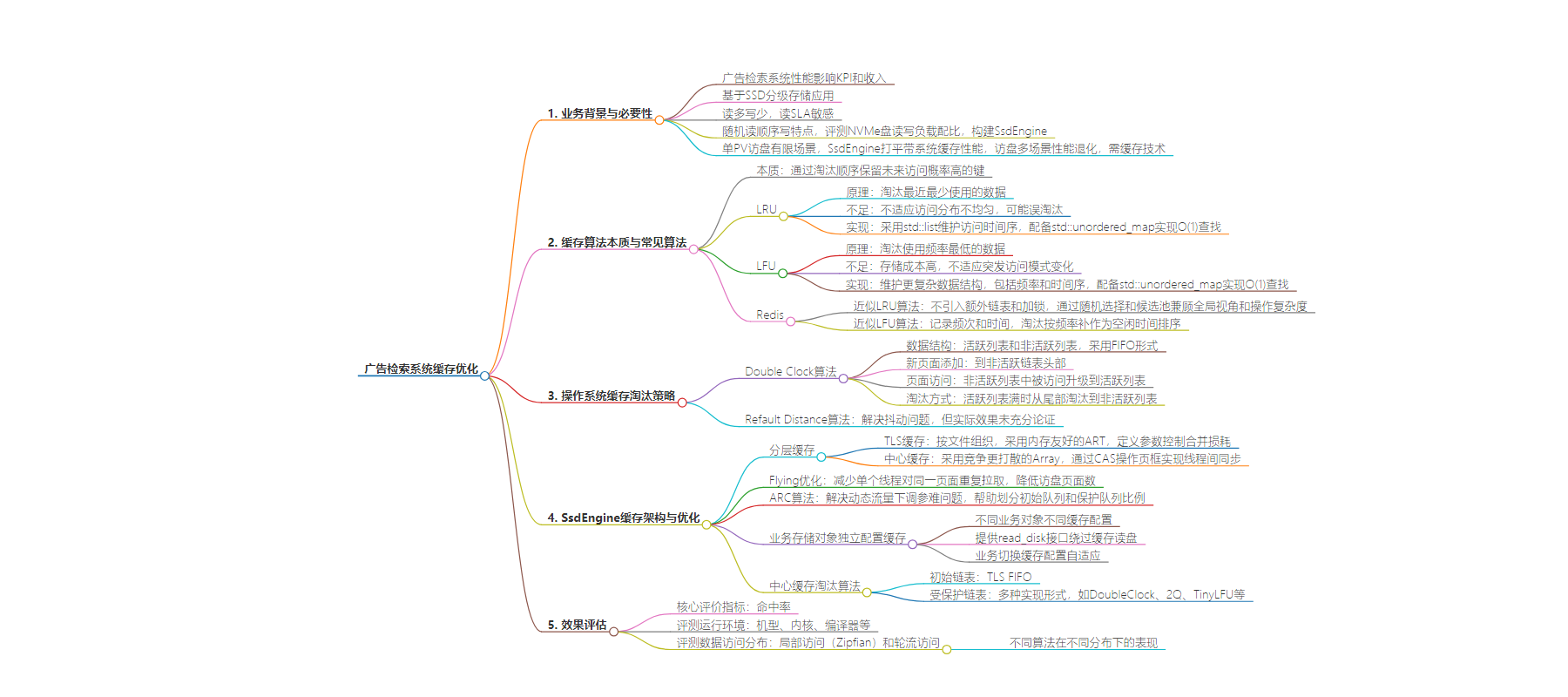
文章地址:https://mp.weixin.qq.com/s/ThynL1XxHOSWUzuAPrs3fA
文章来源:mp.weixin.qq.com
作者:欢迎关注的
发布时间:2024/8/5 7:01
语言:中文
总字数:9604字
预计阅读时间:39分钟
评分:92分
标签:缓存算法,LRU,LFU,TinyLFU,性能优化
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

缓存的业务必要性
缓存是一种系统优化的“万金油”,多被应用在数据密集场景中。当目标服务的访问性能远远差于缓存服务,且访问模式具有显著局部性时[1,2],缓存则作为一种临时存储数据的手段,通过减轻访问目标服务的频率,显著提高了数据检索速度,从而加速了业务处理过程。

△Berkery Interactive Version of Jeff Dean Latency Number
在前一篇《极致优化 SSD 并行读调度》[3],我们提到,广告检索服务因为严苛的KPI,长期以来采用内存检索,业务发展需要更大存储空间,需求量远超过内存可承受。广告检索KPI直接关系收入,检索过程引入基于NVMe SSD的分级存储,长尾控制尤其关键。然而,业界常见访盘优化手段,都以优化吞吐为目标,未能控制读长尾。过去几年持续涌现面向长尾控制的新硬件,但新硬件的引入、适配、推广周期较长。业务需求无法等待,需要先把检索池的存量NVMe用起来。广告检索业务有如下特点:读多写少,读SLA十分敏感。结合广告检索业务随机读顺序写的访盘特点,我们系统性评测了检索池占比90+%的NVMe盘,得到每种盘的最佳读写负载理论配比。并以此为理论基础构建SsdEngine。
为了规避系统缓存的干扰,我们采用DIO访盘,直接控制硬件访问,实现了长尾控制。叠加极致优化读调度,对于单PV访盘有限的场景,SsdEngine基本打平了带系统缓存性能。但访盘较多的场景,单次长尾影响较大,SsdEngine性能退化较可观,这时候就需要缓存技术,大幅降低访盘频率。
缓存算法的本质是淘汰顺序
缓存大小通常是有限的,为此,缓存应尽力保留未来访问概率最高的键,也就是淘汰未来不会访问或访问概率最低的键。可惜缓存无法预测未来,缓存通过定义淘汰顺序(或驱逐策略)来模拟/推理未来。比如假设通常访问模式不会突然发生很大变化,可能再次请求的键是最近经常请求的键,LRU甚至把它简化为最近请求的键。
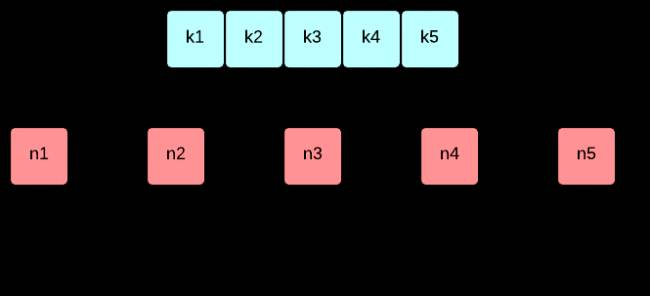
△LRU Cache示意图
get(int key) {auto list_it = ...cache_it->second;list.splice(list.begin(), list, list_it);}put(int key, int value) {if (cache_it != cache_map.end()) {...} else {if (_size >= _capacity) {list.pop_back();}list.emplace_front(...);cache_map.put(key, list.begin());}}
为了LRU能够工作,一般还会配备std::unordered_map来实现O(1)查找。在list中,每个元素是value。unordered_map用于存储每个key对应在list中的迭代器,从而实现在O(1)时间内查找和移动元素。
LRU为了记录“最近”访问的淘汰顺序,需要不断的“move_to_head”。这给高性能实现带来挑战,操作链表中间元素,会显著提升无锁链表的实现复杂度。为此一般的LRU都是通过锁保护。
△LFU Cache示意图
get(int key) {auto list_it = ...cache_it->second;frenquency = list_it->second;frenquency_bucket = list_it->parent;if (frenquency_bucket->next->freq == frenquency + 1) {...} else {...}}put(int key, int value) {if (cache_it != cache_map.end()) {...} else {if (_size >= _capacity) {pop_back(head->next);}if (head->next->freq != 1) {...}push_front(head->next, {value, 1});cache_map.put(key, head->next->begin());}}
为了LFU能够工作,也会配备std::unordered_map来实现O(1)查找。在频率桶list中,每个元素是一个std::pair,其中first存储value,second存储frequency。unordered_map用于存储每个key对应在list中的迭代器,从而实现在O(1)时间内查找和移动元素。
LFU较LRU显然更复杂,对每个频率都独立维护了List,List还会操作中间节点,这对高性能实现带来更多挑战。它的理论优势是,在较大的、没有显著局部性的动态负载下,LRU需要更多的空间来保持和LFU一样的缓存命中率。

Redis起初并没有引入缓存,当业务需要引入缓存时候,Redis慎重考量了两点:(1)缓存数据结构,带来内存容量;(2)move_to_head操作的复杂度,增加性能损耗。为此Redis采用了近似的算法[3],具体来说,Redis采用bit field的方式,从已有的对象robj腾挪出24bit空间,用于记录访问时间。当对象被访问时候,更新被访问对象的访问时间(robj.lru)。在需要淘汰对象的时候,采样若干个对象,淘汰其中空闲时间最久的。
typedef struct redisObject {unsigned type:4;unsigned encoding:4;unsigned lru:LRU_BITS;int refcount;void *ptr;} robj;
当系统需要淘汰一个键时:准备一个容量为M的“死亡候选池”,候选池按空闲时间升序排列,也就是最右侧是需要被淘汰的。遍历每个DB,对每个DB随机选择N个键,尝试按序加入“候选池”。当池子有空间时候,候选键直接加入,或者候选键大于池中键的空闲时间,才能被加入,并淘汰空闲时间最小的键。如果候选键不能被加入候选池,则说明这个候选键不被淘汰。
freeMemoryIfNeeded:struct evictionPoolEntry *pool = ...for (i = 0; i < server.dbnum; i++) {evictionPoolPopulate(i, ..., pool);}for (k = EVPOOL_SIZE-1; k >= 0; k--) {...
Redis LRU算法,没有引入额外的链表,也不需要在访问过程加锁操作。通过随机选择N和候选池M,兼顾全局视角和操作复杂度。实际上,Redis不仅实现了近似的LRU算法,还用类似的方法实现了LFU:(1)8位记录频次 counter,16位记录时间 timer,其中,timer是为了周期性地衰减,感知业务访问模式变化;(2)淘汰时候,按频率的补,作为空闲时间排序。
void updateLFU(robj *val) {unsigned long counter = LFUDecrAndReturn(val);counter = LFULogIncr(counter);val->lru = (LFUGetTimeInMinutes()<<8) | counter;}
操作系统缓存的页面淘汰策略核心是Double Clock算法[5]。数据结构由两个列表构成,分别代表活跃列表和非活跃列表,活跃列表包含了最近经常使用的页面,非活跃列表包含了最近不使用页面。它们都采用FIFO(先进先出)的形式。新页面(Freshly Faulted)添加到非活跃链表的头部,随着页面被回收,非活跃链表中间的元素逐渐向链表的尾部移动。如果页面在非活跃列表,又被访问过一次,该页面会被升级到活跃列表,并清空页面的访问标记。当活跃列表满了,需要从尾部淘汰到非活跃列表。也就是说,DoubleClock并不是严格按照时间顺序来淘汰数据,而选择了是否访问过,从而降低了操作复杂度。具体来说是一组标记<is_active, is_referenced>。

△Linux DoubleClock PageCache
显而易见,非活跃列表配额设置足够长,则给于充分时间积累访问。一个页面被首次访问时(Fresh Fault),加入到非活跃列表的尾部,如果非活跃列表的额度不足,在等到再次访问前,该页面会因为没有访问被回收掉(ReFault)。这种情况叫作抖动(thrashing)。
Linux3时加入Refault Distance算法[11],解决抖动问题。假设非活跃链表足够长,一个页面第二次访问(Refault)和首次访问(Fault)之间的页面数,叫作Refault Distance。Refault Distance可以被看成是一种衡量标准,把非活跃链表延长多少就可以避免抖动。如果它比总大小还长,那说明这个Refault是不可避免的,否则可以做策略。操作系统采用的策略是,把这个页面加入到活跃链表,避免后面持续Fault。
如在业务背景中所述,广告检索业务读SLA十分敏感,为此我们不在检索线程中规避竞争区。SsdEngine在整体设计上,结合广告检索业务的特点,通过简化的RCU的方式实现面向读者友好的数据读写安全。在已有工作的基础上引入缓存,缓存的设计也要以面向读者友好作为第一原则。
△SsdEngine整体架构
从缓存算法章节可见,缓存本质是淘汰顺序,必然涉及到数据结构的调整。然而现代CPU往往是多核的,每个核心都有自己的高速缓存(L1、L2、甚至 L3),线程同步带来损耗,无法发挥硬件优势,为此,我们整体架构上引入分层缓存。大部分情况下,检索线程从TLS缓存中获取页面,极少情况下穿透到中心缓存区。TLS和中心缓存的协作过程,概述是这样的:读盘时,优先读取TLS缓存。如果TLS缓存未命中,再去中心缓存获取,如果获取到页面,则把该页面计入TLS,并返回取得页面。如果以上两级缓存都未命中,则发起读盘,并在TLS中记录本次读盘,我们把这一步叫做Flying。最终,多个线程可能同步获取同一页框对应的页面,这些线程把获取到的页面更新put到中心缓存,并清空Flying。中心缓存对同一页框收到若干页面,只记录CAS成功的一个,其他的页面被释放。随中心缓存淘汰算法运行,页面被清理时,也会对每个TLS缓存发起清空。
△缓存工作流程
TLS缓存按照文件组织,也叫做TLS FilePageTable。由于检索线程数较多,该层采用更加内存友好的数据结构,否则会随检索线程的增加,内存线性地放大。TLS缓存采用了前缀树Radix-Tree,并更进一步地,采用了更内存友好的ART[6,7]。前缀树的路由采用文件中的offset,限定最大3bytes。大家都知道,ART需要通过定期合并compaction,来减少“变形”带来的操作损耗和控制内存,我们定义了一组参数(树大小、树利用率、频次)等控制合并损耗。
中心缓存用于线程在各自的TLS查不到的时候,穿透来访问。它的存储只和文件数相关,内存损耗相对可控,中心缓存的数据组织采用竞争更加打散的Array,通过CAS操作页框实现线程间同步。特别说明:(1)除非在新建/删除文件操作环节有锁,其它put/get页面都是无锁的;(2)上面描述多个线程更新同一页框时,CAS修改页框确保不丢失写,也不丢失冲突记录,否则会发生内存泄漏。
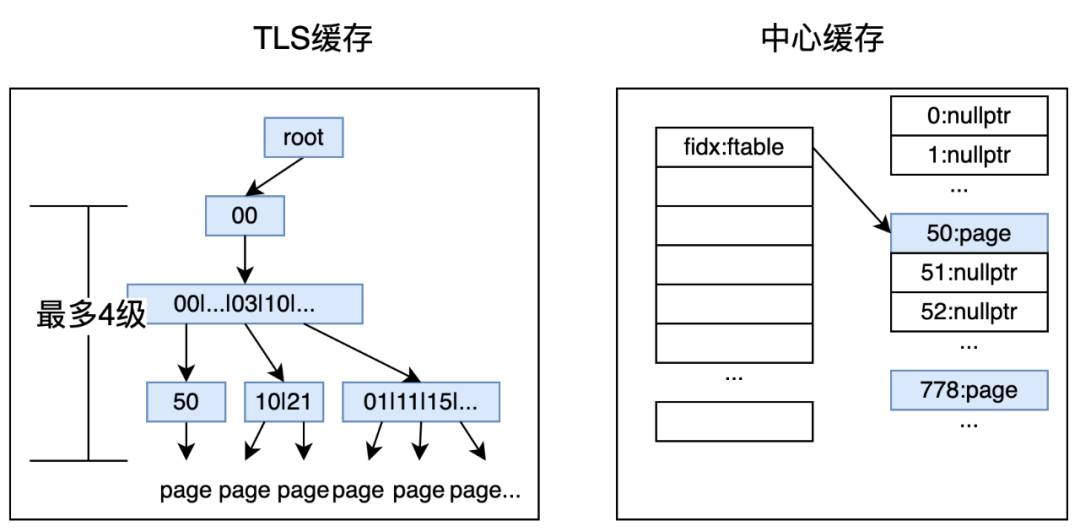
△缓存存储结构
高扇出服务必然遇到扇出带来的长尾,SSD也是如此。评测发现,异步IO时随着读页面的增加,wait耗时也会增加。对于小业务对象,Flying可显著降低访盘的页面数,在凤巢物料服务,我们通过Flying减少了60%的访盘QPS。这是个有趣的优化方向,后续可以按缓存反应出的业务热点,按照热点重新组织数据,进一步提升Flying比例和降低访盘量。
fetch_page:page = _page_manager->alloc_page();local_page_table->insert(pageidx_key, reinterpret_cast<const char*>(reinterpret_cast<uintptr_t>(page) | 1));return std::make_pair(page, true );fetch_page_done:const char* page = local_page_table->find(pageidx_key);if (!(reinterpret_cast<uintptr_t>(page) & 1)) {return 0;}local_page_table->remove(pageidx_key);page = reinterpret_cast<const char*>(reinterpret_cast<uintptr_t>(page) & (~1));
ARC[15]论文应用量高达1300次。在我们实现好整体框架和适配业务的时候,遇到的实际问题是,业务大部分情况下不知道如何划分初始队列和保护队列的比例。单纯地按照给足够大的非保护队列,积累多次访问概率,会导致保护队列的局部性无法发挥效果。ARC论文虽然定位是解决动态流量下调参难的问题,但也恰好帮我们解惑了业务落地问题。
ARC的核心原理是通过保留一倍数量的影子记录,帮助决策当前如何划分两段队列p。具体来说,假定两段队列分别为T1和T2,他们的影子队列分别为B1和B2,如果查询请求命中了B1,意味着我们应当把这次命中当作命中了T1来看,并且暗示了 |T1| 可能小了,没能将这次命中的数据存起来,此时就要调整p。p的调整是累计(0, 1]浮点数控制波动。原理非常直观。
若完全复现ARC,则要打破缓存整体结构,初始队列和受保护队列直接淘汰到DELETE,且带来影子存储的额外管理开销。为此我们实现的自适应版本是:优先受保护队列,在受保护队列未填满内存时候,允许初始队列增长。但值得注意的是,初始队列不能被过分挤压,否则无法累积请求。为此,我们额外设置初始队列的低水位,受保护队列的增长不能超过该水位。
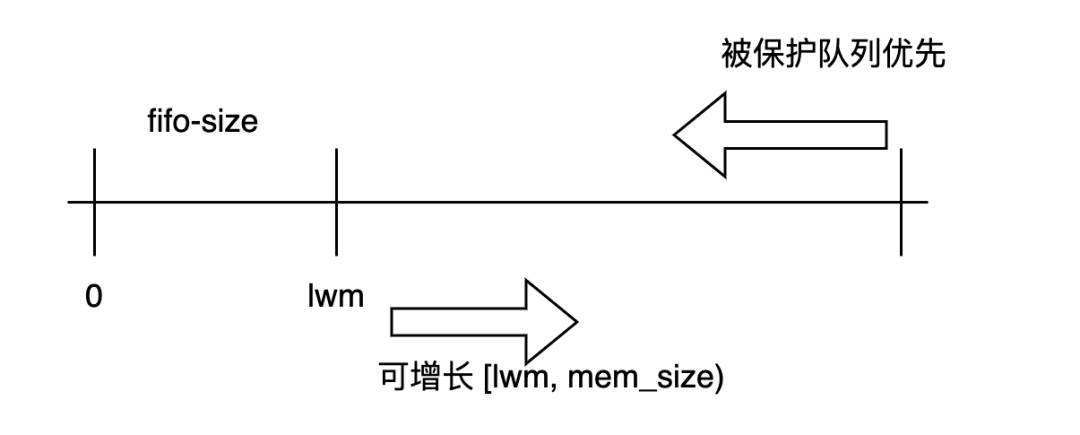
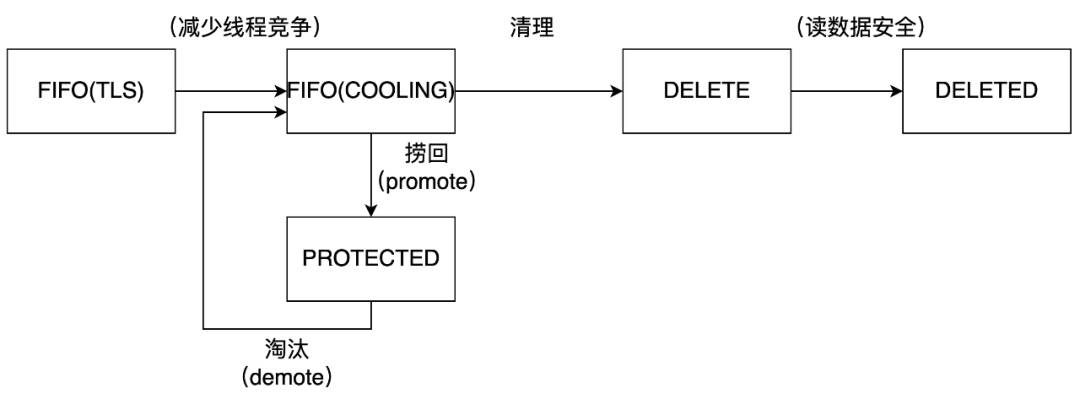
标准的DoubleClock算法通过活跃链表和非活跃链表,组合考虑了页面的<is_active, is_referenced>,近似实现LRU。我们的缓存实现是类似的:当页面按照FIFO顺序从初始链表准备被淘汰的时候,首先,根据内存配额判断必须要淘汰的页面数量,接下来,一直弹出直到淘汰足够多的页面或者链表被清空。在弹出的过程,如果页面被访问过SALVAGE,则加入到受保护区,等待按受保护区FIFO的淘汰算法再处理。
该缓存算法的优势是操作简单,劣势是几乎只通过“访问过”识别顺序。这样的话,无法区分出轮流访问的页面和访问局部性的页面。在局部性很强的场景下,缓存淘汰较LRU差比较多。
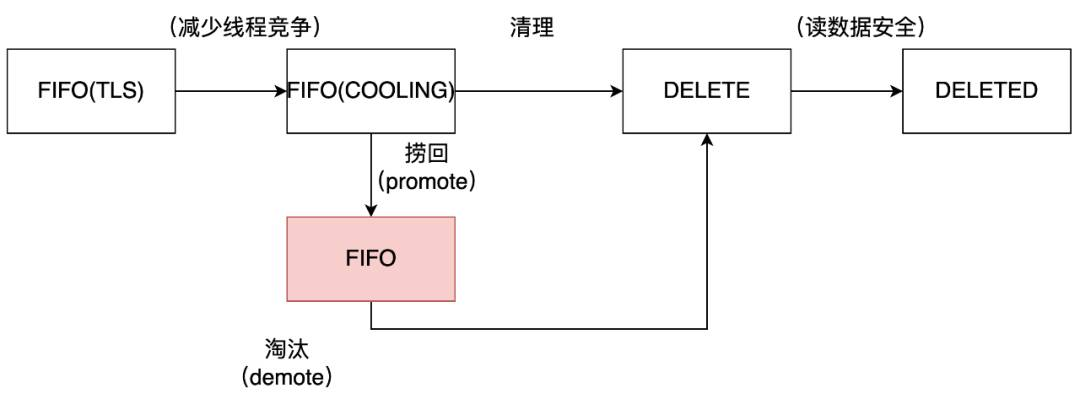
标准2Q算法有两个缓存队列,一个是FIFO队列,一个是LRU队列。当数据第一次访问时,2Q算法将数据缓存在FIFO队列里面,当数据第二次被访问时,则将数据从FIFO队列移到LRU队列里面,两个队列各自按照自己的方法淘汰数据。我们的实现中,初始链表可以看做2Q算法中的FIFO队列,LRU受保护链表作为2Q算法中的LRU队列。
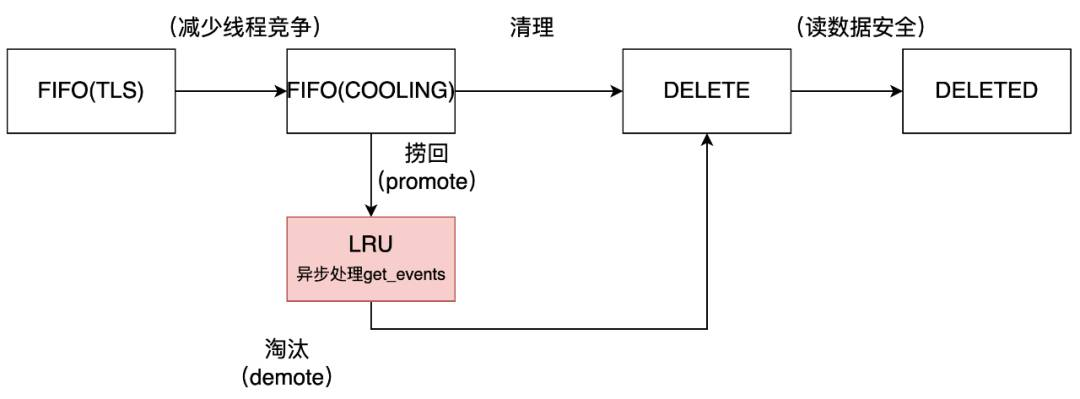
LRU缓存引入了访问时间序,根据访问时间更加准确淘汰。这个好处带来了额外成本,LRU move_to_head操作复杂,一般用锁来保护LRU的操作。为了减少竞争区,我们的LRU实现采用了异步做法,在检索线程仅仅记录TLS getevent,在后台线程扫描所有线程的TLS getevent,批量操作LRU。
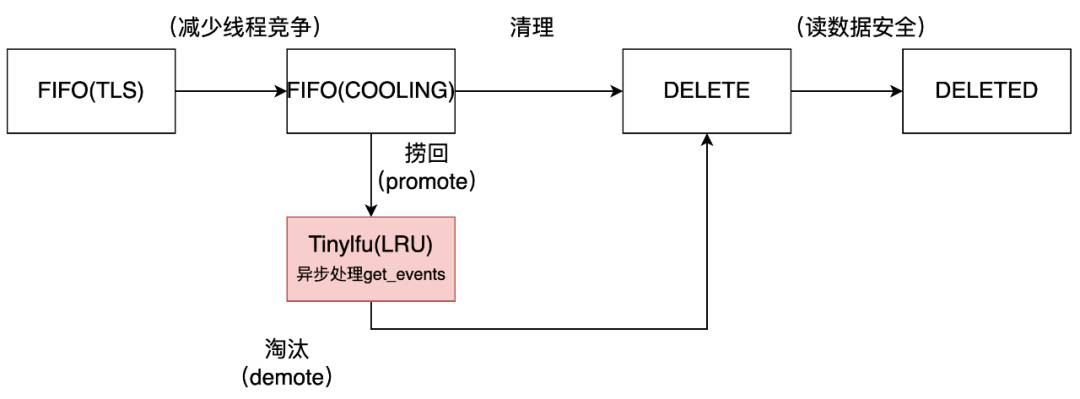
在仅仅按时间序淘汰的LRU之外,我们还参考了TinyLFU[10],引入了基于频率准入的LRU增强,这样兼顾了时间和频次。我们通过如下两点得以实现对全量数据(而不只是LRU存储数据)的统计。第一点,直觉上好像有了FIFO+SALVAGE的方式,并不需要Doorkeerper,实际不然。这是因为SALVAGE也在不断淘汰,没有足够信息识别全量SALVAGE数据,为此继续保留Doorkeeper,和Count-Min Sketch配合以近似的方式刻画全量数据,并通过重置(reset)方法保持数据新鲜度。第二点,对于突发流量的频次积累,我们通过FIFO来实现get事件的积累,无需引入更复杂的W-TinyLFU,从LRU的视角来看,插入要保护在内存的新页面时候,对于来自SALVAGE的new,与超额要淘汰的victim,根据TinyLFU判定是否保留。
效果评估
缓存的核心评价指标是命中率(Hit Ratio)。当一个数据项被访问时,如果它已经出现在缓存中,记为一次缓存命中。缓存命中的次数和数据访问的总次数之间的比率被称为命中率。因此,如果保存在缓存中的项能够“准确”预测未来的访问模式,那么缓存命中率会很高。
评测运行环境机型是CPU Intel(R) Xeon(R) Gold 5118 CPU @ 2.30GHz,L1d cache: 32K,L1i cache32K,L2 cache 1024K,L3 cache 16896K,内核是 64 位 3.10 系。
SsdEngine引擎集成在单机RocksDB中,编译器是GCC12,编译优化选项是 -O2。
为了充分验证缓存效果,先导入一批数据(1000万键空间),每条数据平均占2个页面,再按照分布要求读取这些数据。我们针对这三种缓存算法,评测了局部访问和轮流访问这两种典型的数据访问分布。
场景一:
局部访问(zipfian):在Zipfian分布中,数据项的选择概率与它们的排名成反比关系。具体来说,第i个数据项的选择概率与i的倒数成正比。这意味着排名靠前的数据项具有更高的选择概率,而排名靠后的数据项具有较低的选择概率。换句话说,Zipfian分布中的数据项呈现出“头重脚轻”的特点,即少数数据项被频繁选择,而大多数数据项被相对较少地选择,数据分布具备很强的“局部性”和“长尾性”。Zipfian幂指数参数s控制分布的陡峭程度。当s增大时,分布的头部会变得更加突出,即少数事件的频率会显著高于其他事件。在这种数据分布下,LRU较DoubleClock有优势,但缓存内存足够大的时候优势减弱。
分布是zipfan s=0.6,缓存大小分别为4G、6G、8G、10G、12G的缓存命中率:
△cache hit: zipfian0.6 LRU vs DoubleClock
同时我们看到,由于缓存命中率提升,LRU较DoubleClock在长尾访问上优势明显,以下是9999分位性能(单位us):
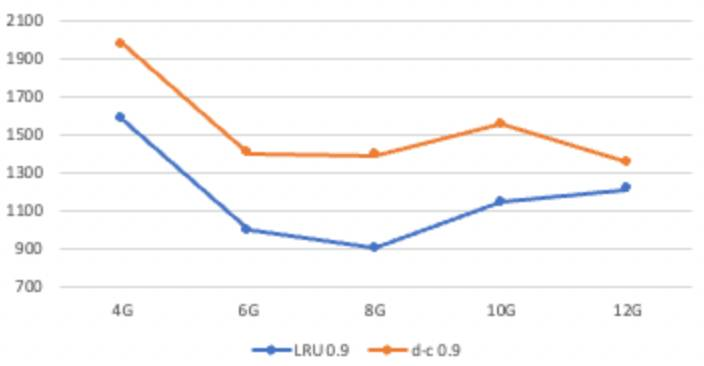
△9999分位性能 LRU vs DoubleClock
场景二:
轮流访问(uniform):每个数据项都具有相等的概率被选择。在这种数据分布下,LRU较DoubleClock并没有优势,徒有算法的复杂性。
分布是uniform,缓存大小分别是4G、6G、8G、10G、12G的缓存命中率:
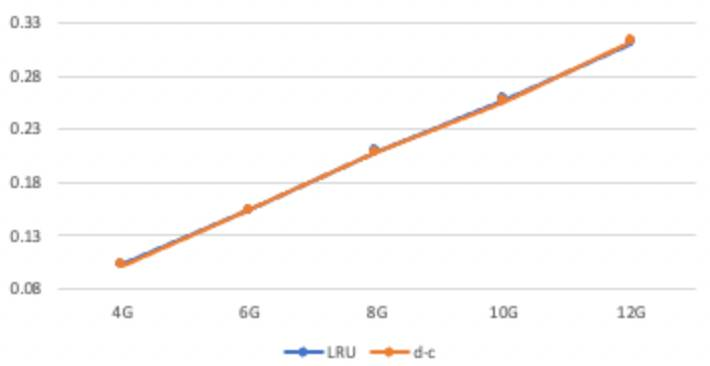
△cache hit: uniform LRU vs DoubleClock
场景三:
TinyLFU和LRU:TinyLFU以少量的内存增长,在任何分布下,都一定程度上提升了LRU的表现。下图择取的zipfan分布下的表现,可以看到,在缓存量相对Key空间较小的情况下,TinyLFU由于考虑了时间和频次,具有明显优势,但是随着缓存大小的上涨,TinyLFU和LRU缓存效果趋于相近。同时我们还发现TinyLFU要花更久的时间才能积累到缓存效果。
△cache hit: zipfian0.6 LRU vs DoubleClock & TinyLFU
参考资料:
[1].Software Engineering Advice fromBuilding Large-Scale Distributed Systems,2002
[2].Berkeley Interactive Version Latency Number
[3].极致优化 SSD 并行读调度
[4].Random notes on improving the Redis LRU algorithm
[5].A Lockless Pagecache in Linux—Introduction,Progress, Performance,2006
[6].Page Cache eviction and page reclaim
[7].The Adaptive Radix Tree: ARTful Indexing for Main-Memory Databases,2013
[8].凤巢倒排服务的优化
[9].2Q: A Low Overhead High Performance BufferManagement Replacement Algorithm,1994
[10].TinyLFU: A Highly Efficient Cache Admission Policy, 2017
[11].Better active/inactive list balancing, 2012
[12].Linux Spin Lock Cas Implementation
[13].LevelDB sharded LRU Implementation
[14].An O(1) algorithm for implementing the LFU cache eviction scheme, 2010
[15].ARC: A Self-Tuning, Low Overhead Replacement Cache,2003
推荐阅读:
如何定量分析 Llama 3,大模型系统工程师视角的 Transformer 架构
微服务架构革新:百度Jarvis2.0与云原生技术的力量
技术路线速通!用飞桨让京剧人物照片动起来
无需业务改造,一套数据库满足 OLTP 和 OLAP,GaiaDB 发布并行查询能力
Tensor 索引的使用指南及学习心得
