
包阅导读总结
1. 关键词:安卓手机、大模型、部署、MLC LLM、环境配置
2. 总结:
本文介绍了在安卓手机上部署大语言模型的实战过程,包括MLC LLM的概念和组成,所需的基本环境配置,如Anaconda、Rust、Android Studio等,以及模型的构建、运行时和模型库的准备,最后构建Android应用程序生成APK并安装到手机上。
3. 主要内容:
– 前言
– 大语言模型成为热点,出于定制化等目的需在终端设备本地运行
– 介绍采用机器学习编译技术解决问题
– MLC介绍
– 由模型定义、编译和运行三个子模块组成
– 各子模块的特点和支持的模型架构
– 基本环境配置
– 电脑和手机的硬件要求
– 配置Anaconda虚拟环境
– 安装Rust、Android Studio等
– 配置环境变量
– 安装Java
– 相关TVM的配置
– 安装MLC-LLM
– 构建运行时和模型库
– 配置mlc-package-config.json
– 构建和准备模型库的命令及输出
– 模型下载相关
– 构建Android应用程序
– 生成APK
– 启用手机“USB调试”
– 安装APK和权重
– 可在手机上运行较小模型,后续将尝试更大模型
– 参考文档链接
思维导图: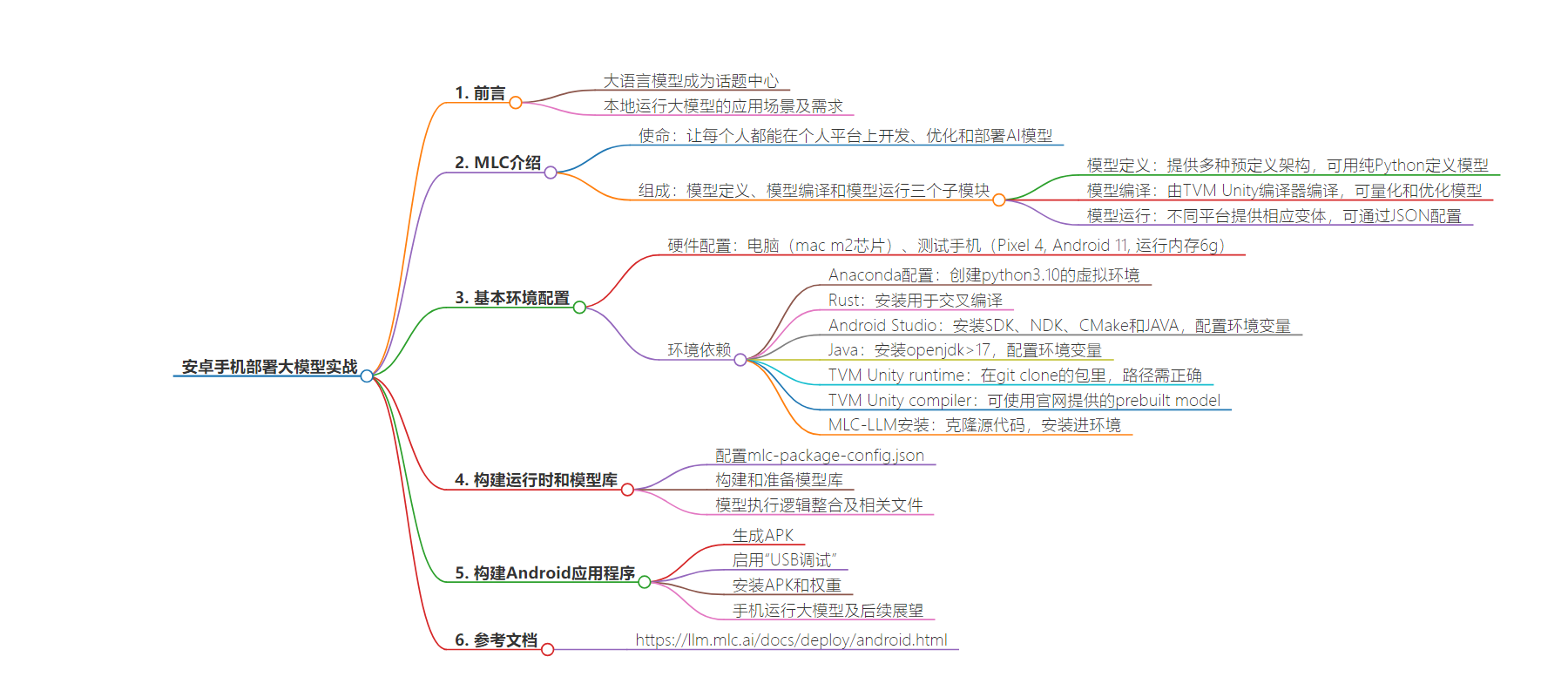
文章地址:https://mp.weixin.qq.com/s/Y7wBJJ1mszxecedOk0y_Wg
文章来源:mp.weixin.qq.com
作者:Lbin
发布时间:2024/7/25 6:53
语言:中文
总字数:3328字
预计阅读时间:14分钟
评分:89分
标签:大语言模型,安卓部署,MLC LLM,本地运行,AI应用
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
前言
自ChatGPT发布以来,大语言模型(Large language model, LLM)就成了AI乃至整个计算机科学的话题中心。学术界,工业界围绕大语言模型本身及其应用展开了广泛的讨论,大量的新的实践层出不穷。
由于LLM对计算资源的需求极大,有能力部署大语言模型的公司和实验室一般通过搭建集群,然后开放API或者网页demo的方式让用户可以使用模型。在人们纷纷发挥想象力尝试各种prompt与模型对话的时候,我们也注意到在一些应用场景中,出于定制化、个性化或者隐私性的目的,人们想要自己在各种终端设备中本地运行大语言模型,不需要/不希望连接互联网或者依赖于服务器,例如
1、智能汽车的终端可以对驾驶员的操作习惯定制化
2、智能家居的终端可以对户主的生活习惯定制化
3、手机游戏,或者主机游戏中NPC的对话可以根据玩家的行为而改变
4、PC端的应用希望本地部署聊天机器人,但是用户的显卡可能是N卡,A卡,或者集成显卡,安装了CUDA/Vulkan/OpenCL驱动
希望能够让每个人都可以开发,优化和部署AI大模型,让它工作在每个人都能方便获得的设备上。
如何做
我们采用了机器学习编译技术来解决这一类问题。
MLC LLM 是一个用于大型语言模型的机器学习编译器和高性能部署引擎。该项目的使命是让每个人都能够在每个人的平台上原生地开发、优化和部署 AI 模型。
本页是一个快速教程,介绍如何尝试 MLC LLM,以及使用 MLC LLM 部署您自己的模型的步骤。
MLC介绍
这里稍微讲解了一些MLC的基本概念,以帮助我们使用和了解 MLC LLM。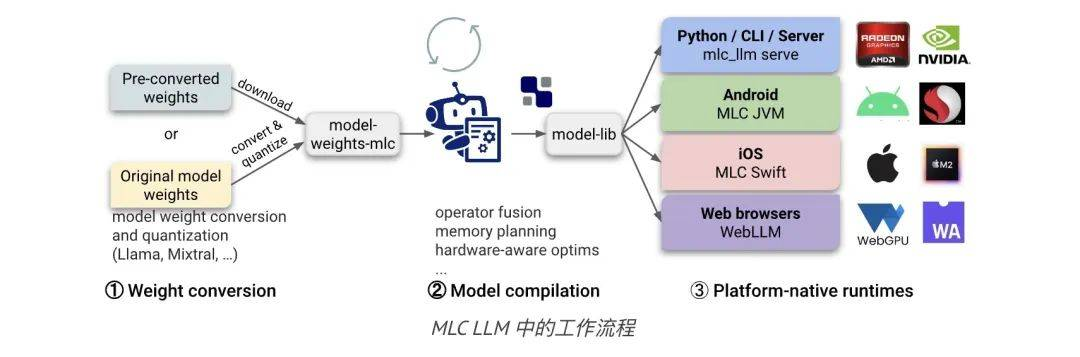 MLC-LLM 由三个不同的子模块组成:模型定义、模型编译和模型运行。
MLC-LLM 由三个不同的子模块组成:模型定义、模型编译和模型运行。
MLC LLM 的三个独立子模块
1、Python 中的模型定义。MLC 提供各种预定义架构,例如 Llama(例如 Llama2、Vicuna、OpenLlama、Wizard)、GPT-NeoX(例如 RedPajama、Dolly)、RNN(例如 RWKV)和 GPT-J(例如MOSS)。开发人员可以仅使用纯 Python 定义模型,而无需接触编码。
2、Python 中的模型编译。模型由TVM Unity编译器编译,其中编译配置为纯 Python。MLC LLM 将基于 Python 的模型量化导出到模型库并量化模型权重。可以用纯 Python 开发量化和优化算法,以针对特定用例压缩和加速 LLM。
3、不同平台的模型运行。每个平台上都提供了 MLCChat 的变体:用于命令行的C++ 、用于 Web 的Javascript 、用于 iOS 的Swift 和用于 Android 的Java,可通过 JSON 进行配置。开发人员只需熟悉平台即可将 MLC 编译的 LLM 集成到他们的项目中。
MLC LLM 还有很多概念,这里不在过多赘述,下面我们直接开始实践。
基本环境配置
这是我这里的硬件配置
电脑:mac m2芯片测试手机:Pixel 4,Android 11,运行内存6g
电脑根据官网所说,在windows、linux、mac都可以跑通,主要强调一下手机,运行内存需至少需大于6g,这个配置上可以跑gemma-2b,Qwen2-1.5B等较小的模型,但如果是Llama2-13B较大的,很可能会超出内存
需要的环境依赖不少,这里我们一步一步慢慢来
Anaconda 配置
在MLC中需要使用的python最低版本在3.10以上,为避免环境冲突,所以最好使用虚拟环境来进行环境配置,这里推荐使用Anconda来配置虚拟环境,相关的安装方法,可参考Anaconda安装
创建虚拟环境,后续的一些操作都尽量在虚拟环境中去操作
#创建一个your-environment的虚拟环境,python版本为3.10
condacreate-nyour-environmentpython==3.10
#进入虚拟环境
activateyour-environment
Rust
来自官网的介绍:Rust (install) is needed to cross-compile HuggingFace tokenizers to Android. Make sure rustc, cargo, and rustup are available in $PATH.如此安装:
curl--proto'=https'--tlsv1.2-sSfhttps://sh.rustup.rs|sh
Android Studio
要使用Android Studio就需要安装 SDK、NDK、CMake和JAVA。
其中Android Studio可以在官网中去下载。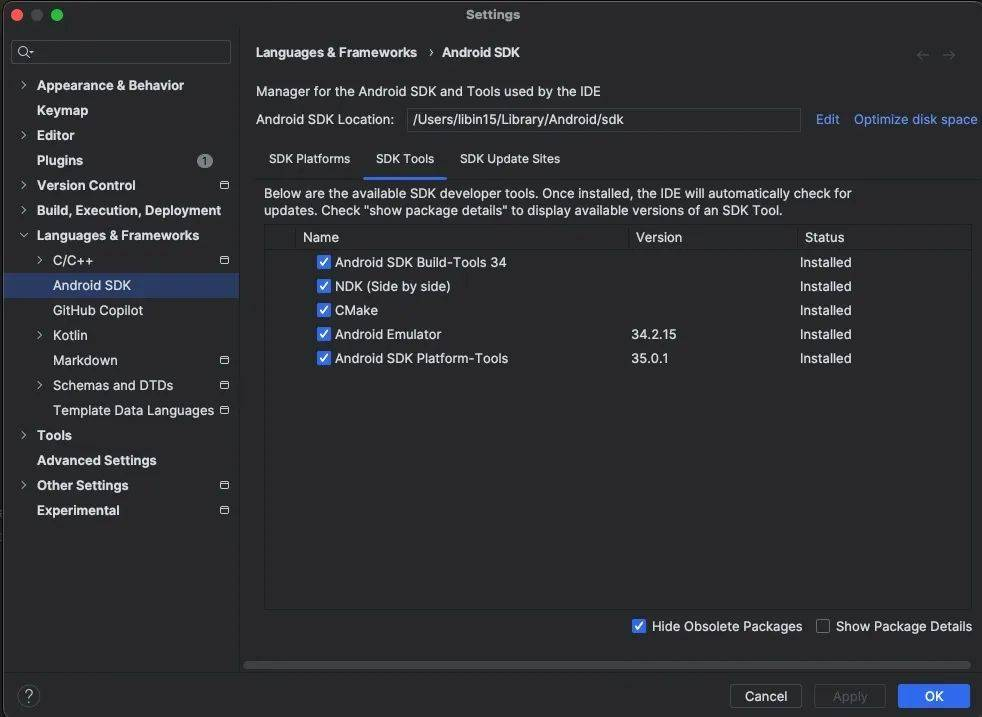 在 Android Studio 单击“File → Settings → Languages & Frameworks → Android SDK → SDK Tools”,选择安装NDK、CMake和Android SDK Platform-Tools。安装完成后,需要在环境变量中去对NDK等进行配置才可使用。
在 Android Studio 单击“File → Settings → Languages & Frameworks → Android SDK → SDK Tools”,选择安装NDK、CMake和Android SDK Platform-Tools。安装完成后,需要在环境变量中去对NDK等进行配置才可使用。
配置环境变量
exportANDROID_NDK="$HOME/Library/Android/sdk/ndk/27.0.11902837"
exportANDROID_HOME="$HOME/Library/Android/Sdk"
exportPATH="$PATH:$HOME/Library/Android/Sdk/cmake/3.22.1/bin"
exportPATH="$PATH:$HOME/Library/Android/Sdk/platform-tools"
exportTVM_NDK_CC="$ANDROID_NDK/toolchains/llvm/prebuilt/darwin-x86_64/bin/aarch64-linux-android24-clang"
exportTVM_SOURCE_DIR="$HOME/pyProjects/intelli-vista/3rdparty/tvm"
exportTVM_HOME="$TVM_HOME/include/tvm/runtime"
exportMLC_LLM_SOURCE_DIR="$HOME/pyProjects/intelli-vista"
exportJAVA_HOME="/Applications/Android\Studio.app/Contents/jbr/Contents/Home"
Java
Android Studio需要安装openjdk,官方要求的版本是>17。安装教程很多,这里以linux常用的安装方式为列:
#更新update
sudoaptupdate
#安装openjdk17
sudoaptinstallopenjdk-17-jdk
#查看jdk17的安装路径
sudoupdate-alternatives--listjava
#用上面命令获取的路径,编入到bashrc文件的最后一行中
vi~/.bashrc
#将下面的命令,编入到bashrc文件的最后一行中
exportJAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64/bin/java
#更新环境变量
source~/.bashrc
TVM Unity runtime
这个就在我们接下来要git clone的包里,在 3rdparty/tvm里面,所以不需要额外下载,只需要在上面环境配置中路径写对即可。
TVM Unity compiler
我们需要用这个来对模型进行编译,也可以直接使用官网提供的prebuilt model,这样就不用安装,本章直接使用官网已经提供的作为展示。
condaactivateyour-environment
python-mpipinstall--pre-U-fhttps://mlc.ai/wheelsmlc-ai-nightly
TVM的安装验证:以下命令可以帮助确认 TVM 是否已正确安装为 python 包并提供 TVM python 包的位置
>>>python-c"importtvm;print(tvm.__file__)"
/some-path/lib/python3.10/site-packages/tvm/__init__.py
MLC-LLM安装
#克隆源代码及源代码附属的子项目
gitclonehttps://github.com/mlc-ai/mlc-llm.git--recursive
#进入mlc-llm文件夹
cdmlc-llm
#将mlc-llm安装进环境
pipinstall.
验证安装
>>>mlc_llm--help
usage:MLCLLMCommandLineInterface.[-h]
{compile,convert_weight,gen_config,chat,serve,bench}
positionalarguments:
{compile,convert_weight,gen_config,chat,serve,bench}
Subcommandtotorun.(choices:compile,
convert_weight,gen_config,chat,serve,bench)
options:
-h,--helpshowthishelpmessageandexit
构建运行时和模型库
Android 应用程序构建的模型在 中指定MLCChat/mlc-package-config.json:在 中model_list,model指向 Hugging Face 存储库,该存储库model指向包含预转换模型权重的 Hugging Face 存储库。Android 应用程序将从 Hugging Face URL 下载模型权重。model_id是唯一的模型标识符。estimated_vram_bytes是对模型在运行时所占用的 vRAM 的估计。”bundle_weight”: true意味着模型的模型权重将在构建时捆绑到应用程序中。overrides指定一些模型配置参数覆盖。
此处我们测试两个模型gemma-2b 和 Qwen2-1.5B,所以配置mlc-package-config.json为:
{
"device":"android",
"model_list":[
{
"model":"HF://mlc-ai/gemma-2b-it-q4f16_1-MLC",
"model_id":"gemma-2b-q4f16_1-MLC",
"estimated_vram_bytes":3000000000,
"bundle_weight":true
},
{
"model":"HF://mlc-ai/Qwen2-1.5B-Instruct-q4f16_1-MLC",
"estimated_vram_bytes":3980990464,
"model_id":"Qwen2-1.5B-Instruct-q4f16_1-MLC",
"bundle_weight":true
}
]
}
我们有一个单行命令来构建和准备所有模型库:
cd/path/to/MLCChat#e.g.,"android/MLCChat"
exportMLC_LLM_SOURCE_DIR=/path/to/mlc-llm#e.g.,"../.."
mlc_llmpackage
该命令主要执行以下两个步骤:编译模型。我们将每个模型编译model_list成MLCChat/mlc-package-config.json二进制模型库。
构建运行时和标记器。除了模型本身之外,还需要轻量级运行时和标记器来实际运行 LLM。
该命令创建一个./dist/包含运行时和模型构建输出的目录。请确保以下所有文件都存在于中./dist/。
dist
└──lib
└──mlc4j
├──build.gradle
├──output
│├──arm64-v8a
││└──libtvm4j_runtime_packed.so
│└──tvm4j_core.jar
└──src
├──cpp
│└──tvm_runtime.h
└──main
├──AndroidManifest.xml
├──assets
│└──mlc-app-config.json
└──java
└──...
移动 GPU 中的模型执行逻辑已整合到 中libtvm4j_runtime_packed.so,而tvm4j_core.jar是与之绑定的轻量级 (~60 kb) Java 。dist/lib/mlc4j是一个 gradle 子项目,您应将其包含在应用中,以便 Android 项目可以引用 mlc4j (MLC LLM java 库)。此库打包了执行模型所需的依赖模型库和必要的运行时。
我们定义的模型下载后会在这里
dist
├──bundle
│├──gemma-2b-q4f16_1#Themodelweightsthatwillbebundledintotheapp.
│└──mlc-app-config.json
└──...
由于环境和网络限制,可以使用国内大佬们提供好的下载,也可以采用一些特别手段,这里不在赘述。
构建Android应用程序
生成 APK。进入 Android Studio,点击“Build → Generate Signed Bundle/APK”生成 APK 进行发布。如果是第一次生成 APK,需要根据Android 官方指南生成密钥。此 APK 将放置在 下android/MLCChat/app/release/app-release.apk。
在手机设置的开发者模式中启用“USB 调试”。运行以下命令,如果 ADB 安装正确,你的手机将显示为设备:
adbdevices
将 APK 和权重安装到您的手机。运行以下命令安装应用程序,并将本地权重推送到设备上的应用程序数据目录。完成后,您可以在设备上启动 MLCChat 应用程序。bundle_weight设置为 true 的模型的权重已存在于设备上。
cd/path/to/MLCChat#e.g.,"android/MLCChat"
pythonbundle_weight.py--apk-pathapp/release/app-release.apk
现在已经可以在手机上运行大模型了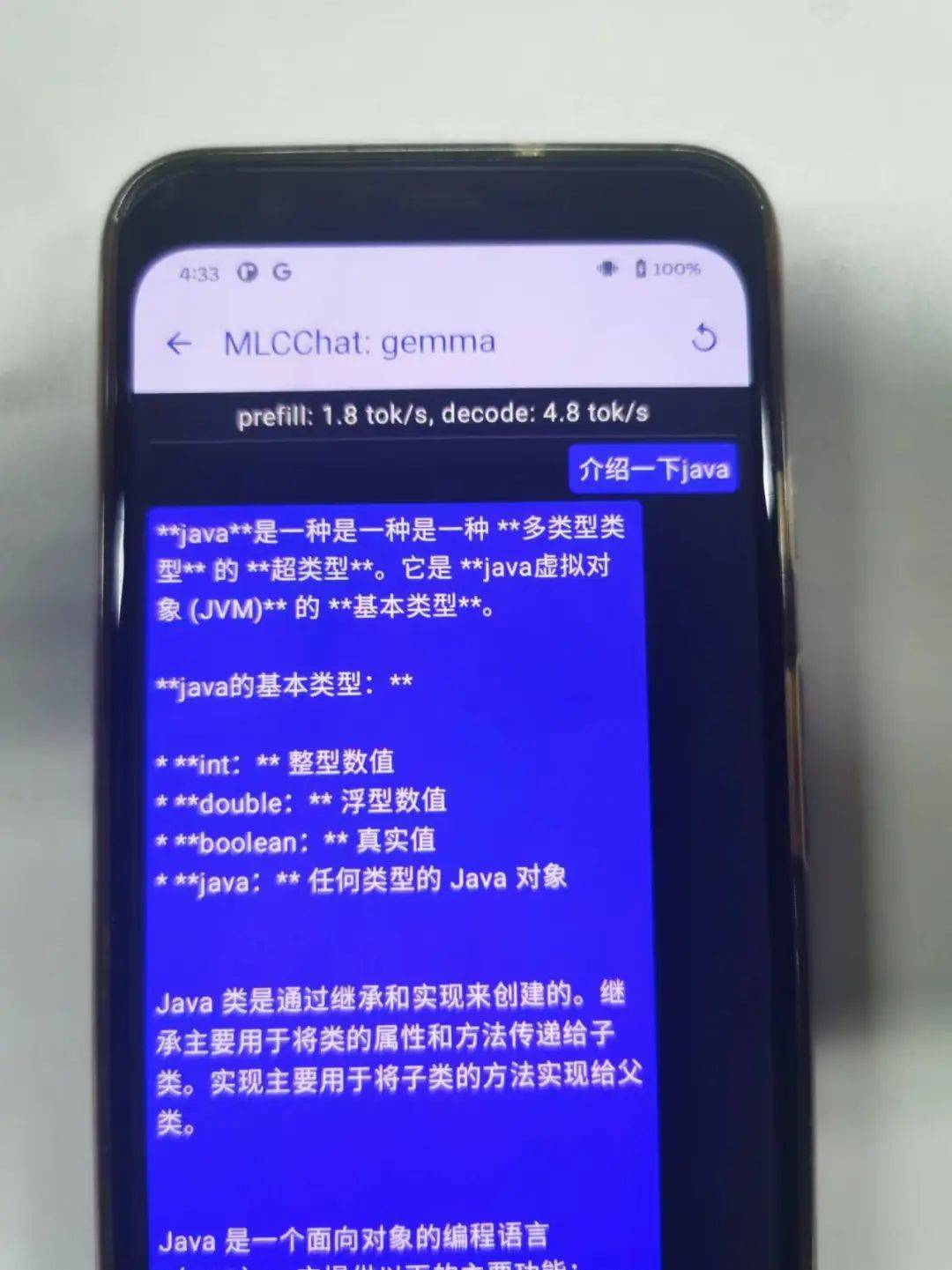
由于手机硬件问题,目前只能跑像gemma-2b 或者 Qwen2-1.5B较小的模型,后续会在其他手机上尝试跑一下更大的模型例如Llama-13B。
参考文档:
https://llm.mlc.ai/docs/deploy/android.html