
包阅导读总结
1.
`ES、Milvus、全文检索、文档搜索、业务落地`
2.
本文介绍了用 ES + Milvus 实战落地全文检索业务,包括背景、架构、实现过程及结果合并等。指出了两者结合的优势及问题,如解决了单一使用的不足,目前搜索点击率约 65%,后续还需优化。
3.
– 背景
– 随着团队和公司发展,文档数量增多,文档搜索成为重要功能。
– 架构
– 单 Milvus 搜索架构,用户请求后后端处理并自定义评分。
– ES + Milvus 搜索架构,在单 Milvus 基础上增加 ES 搜索召回,整合结果排序返回。
– 实现过程
– Milvus 向量搜索,开发工作量不大,重点在前期数据处理。
– ES 工作较多,按类型配置 DSL 以保证搜索效率。
– 召回结果合并
– 确定数据比例,如 milvus 辅助 es 时正常 6:4,特定情况 8:2。
– 对评分进行归一化等处理,合并去重后排序返回。
– 总结
– 介绍了一种文档搜索实现方案,有不完善之处,搜索点击率一般,后续持续优化。
思维导图:
文章地址:https://mp.weixin.qq.com/s/9ZyMRQUs5R6IZRzZhs0etw
文章来源:mp.weixin.qq.com
作者:井柏然
发布时间:2024/7/17 3:03
语言:中文
总字数:4810字
预计阅读时间:20分钟
评分:90分
标签:全文检索,Elasticsearch,Milvus,搜索优化,向量搜索
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
点击关注公众号,“技术干货”及时达!
「本文为稀土掘金技术社区首发签约文章」
经过前面几篇文章的铺垫,我们已经领略到 ES、Milvus 在其各自优势中给全文搜索领域的业务带来的无限可能。简单来说,ES擅长关键词匹配,Milvus具备”语义“优化能力,可以对近、同义词的内容进行检索,以提升搜索质量。接着,我便结合他们俩的能力来落地文档搜索的业务,let’go~
回顾背景
随着团队、公司的发展,一定会沉淀出各式各样的文档,并且随着时间的累积,文档的数量也肯定是越来越多。其中不乏有技术分享文档、接口设计文档、业务对接文档、教程、changelog 等等…随着文档数量的增加和用户数量的增加,文档搜索便成为了一个很重要的功能,它能帮助用户快速查找、定位到他们需要查看的内容,以提升工作效率。
本文正是基于以上这点,用 ES+Milvus 落地实战了一个文档搜索的业务。大概介绍一下场景和效果,目前大概有 8W 左右的文档数量,平均每篇文档的字数没有统计过(属于正常文档吧,不会特别长也不会很短的),目前粗略统计出来的数据是搜索点击率 65% 左右。
图览架构
有从前面几篇文章一路看下来的同学应该都有所感悟,ES在多重语义场景下的语义搜索能力欠缺和Milvus在非中文场景的搜索不准确其实都多多少少影响着整体搜索的效果和用户体验。比如在一开始没有使用 Milvus 做向量搜索时,就有用户反馈同义、近义词,或者语义相近的词语总是搜不出对应的文档;再比如后来切换成纯 Milvus 做搜索时,又有用户通过直接搜索代码、Api无法搜索出对应文档…
因此,再后来便有了结合使用 ES+Milvus 的实战,可以说一路走来真的是跌跌碰碰,一边在不断地优化、一边在不断地发现新的问题~这里,我先贴出之前文章中有提到的 Milvus向量搜索的一个架构介绍图:

图上分了两部分,一部分是数据清洗、落库的;一部分是用户搜索的,这里我们「关注右边」那一块就好了。在单 Milvus 搜索的情况下,用户每次请求,后端做的事件很简单,把搜索关键词做特征化处理后,调用 Milvus 的向量搜索接口,然后将 Milvus 的返回结果经过一些自定义的评分后返回给用户。
这里的自定义评分其实也没做什么,只是会「针对命中的数据类型给予不同的权重系数」而已,比如说搜索出来的结果有文章标题的,那系数为2,有 h2 类型标题的系数为1.5,正文类型的为1…仅此而已
那么,ES + Milvus 结构下的搜索架构,只需要在上述的基础上加上 ES 的搜索召回,整合 ES 和 Milvus 的结果,排好序返回前端即可,其架构图如下:
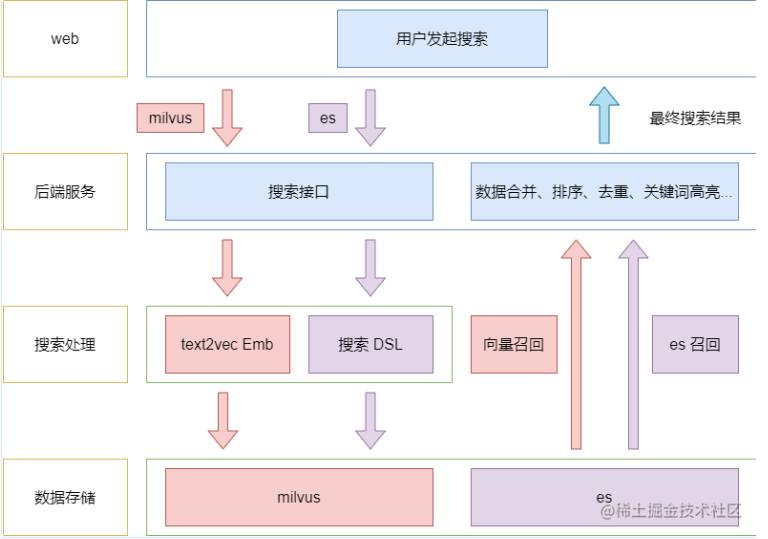
总结上图核心流程:
-
「用户提交查询阶段」,后端服务对搜索数据做相应处理 -
-
-
自定义评分调整排序。如向量搜索会根据命中的内容类型乘上相应系数。 -
合并 ES、Milvus 结果。这里先做归一化处理,再进行去重,再重新算分后排序 -
关键词高亮。向量搜索的返回结果是不具备关键词高亮的,需要自己实现
-
全文检索
1. 向量
对于 Milvus 这一部分而言,开发工作量相比 ES 是轻松很多的(前提是基建完善,有一个可用的词嵌入处理模型。具体的和之前文章中介绍的都差不多,这里再简单回顾一下就过了。
实现向量搜索的业务开发阶段,无非就是把用户的搜索关键词做一次词嵌入获得对应的向量数组后,再调用 milvus 的向量搜索接口完成的。其中的调用查询接口,需要我们关注的无非就是那段查询的配置了。以我目前用的 node.js SDK 调用的 api 为例子给大家演示。(当然大家也可以直接看官网的案例(https://milvus.io/docs/single-vector-search.md)
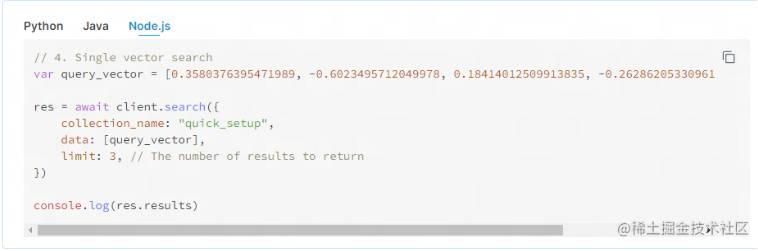
以下是我目前调用 milvus 的配置:
awaitapp.milvus.search({
collection_name:collection,//集合
partition_names,//分区
vector:text_embs,//向量数据
params:{nprobe:16},//nprobe搜索精度相关
metric_type:searchConfig.metric_type,//度量方式
limit:limit??searchConfig.limit,//查询数量
timeout:searchConfig.timeout,
offset:0,//从0开始查询
filter:filter??null,//一些过滤条件
});
简单讲一下大家可能有疑问的配置:
-
partition_names:因为我这边搜索的文档是分「中英日」三种语言的,所以我在数据存储的时候用了分区存储,这里就是根据用户当前搜索的语种来选分区的 -
nprobe:用于 IVF 检索类型,我目前用的是FLAT(数据总量在 35w 左右),跟搜索精度相关的,值越大,越耗时,当然精度也越高。这个大家可以自己按需求配置吧,我也是自己试着调用看的效果设置的。 -
metric_type:这里我直接用了IP,大家也可以自己试着配置看效果决定 -
limit、offset:一次性取多条数据,再通过后端分页。 -
filter:一些过滤条件。比如我只需要搜索某个父类文档中的子文档,便可以通过filter来缩小范围
至于 limit、offset,大家可能还会有疑问就是为什么我是一次性取多条数据,再自己实现分页呢?因为我在文档存储阶段,就对文档数据做了切片、分类(如标题、正文)再进行词嵌入后再落库到 mivlus 中的处理,所以直接通过 milvus 中的分页,可能会存在重复的数据(一篇长文档可能被切割成几十条数据再存进 milvus 中的)。
那对文档数据做切割再落库的目的,大家可以回看之前的文章(https://juejin.cn/post/7365152703830048806)介绍,反正原理就是你对一整篇文章做阅读理解和对这篇文章中的一句话做阅读理解的结果可能是不一样的,所以对于我目前「内部用户的短句搜索习惯」来说,我需要把长的文段切割再做词嵌入落库。
再有就是说,milvus 的检索速度在我目前的数据量来说还是非常快的,基本都是「几百毫秒」下就有返回,所以我一次性搜索多条数据也不会影响性能。并且因为跟 ES 并用,更多情况下向量搜索出结果了还需要等 ES 那边…所以一次性查一定量数据来自己做分页,性能上大家也不用太担忧。
总的来说,业务搜索对于向量搜索的实现来说并不复杂,就是简单地传参、调接口而已。我个人感觉更多的工作量是在前期准备阶段,也就是对「文档的数据清洗、切割、分类、再做词嵌入落库」这么一个过程。当然,这一块后续有时间也会写一篇文章来介绍下。
2. ES
ES 这块相比向量来说要做的工作就多一点,不过也是配置为主…熟悉 ES 的都知道,他的 DSL 也就是一份 json 配置。之前的文章也有一些截图,大家可以在我截的 kibana 界面中的一些简单的搜索配置:
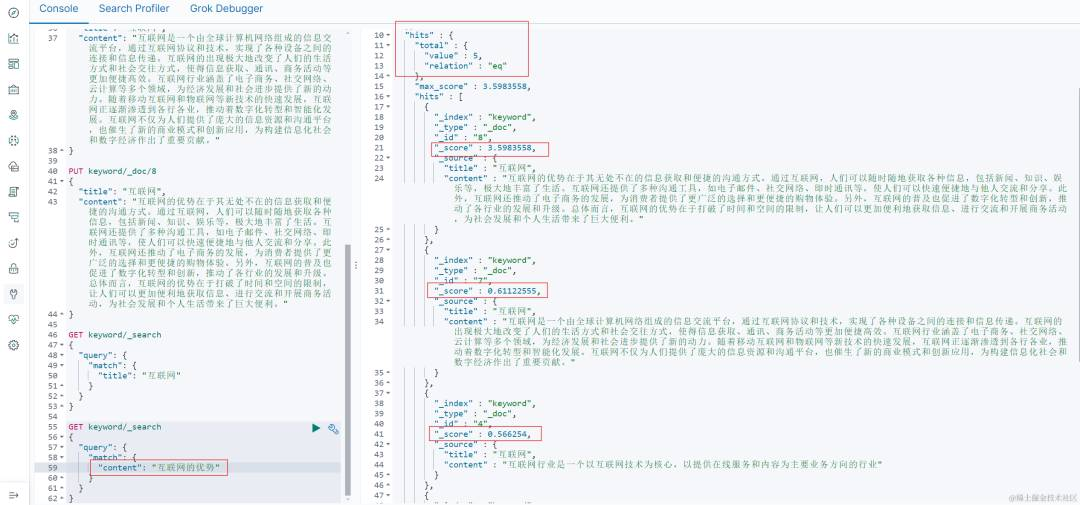
如上图所示,其实就是那段 json:
{
"query":{...}
}
这里我就简单介绍一下目前的 DSL 的设计,「从整体的大框架看,搜索主要有四部分」,外加一块关键词高亮的 DSL:
代码大概如下:
constDSL={
query:{
bool:{
filter:[{term:{language}}],
should:[
...getTitleDSL(),//标题
...getContentDSL(),//内容
...getCodeDSL(),//代码块
...enhanceApiSearchDSL(),//api增强
...enhanceNumberSearchDSL(),//纯数字增强
],
},
},
highlight:getHighlightDSL(),
from,
size,
_source:{
exclude:['h*.*'],
},
min_score:1.0
};
其实我从类型进行不同的 DSL 配置,一部分是基于「内部用户的搜索情况」决定的,一部分是从「搜索效率」决定的。因为在我接手前,ES 的那段 DSL 比较复杂,大量地方用了像 wildcard、fuzzy 这种比较耗时的检索配置,导致经常出现超时问题…所以我还是有所取舍地按分类配置 DSL,以保证一定的搜索效率,毕竟准度方面还有 milvus 辅助。
❝
ps:对于本文提及的 ES DSL 的一些搜索关键字,如
match、match_phrase的作用、区别等,本文不会展开探讨,必要时大家自己查询文档说明即可。❞
简单讲讲我的一些配置策略:
-
「标题」:主要是用的是 match和match_phrase_prefix。基于标题本身字符数量少,因此 match 中配置了minimum_should_match: '80%',拆词后命中 80% 即可,另外还配置了slop: 2,允许出现 2 的偏移情况 -
「正文」:仅配置 match_phrase。因为正文内容多,且用户直接通过搜索正文的场景次数偏低,所以我这里对于正文采取的策略是完全匹配用户搜索词才算命中。 -
「代码块」:代码块的策略主要是模糊匹配,所以配置了 match_phrase_prefix、wildcard两种。主要是内部用户经常通过方法名、api接口路径等方式搜索,所以采取了这么一个策略。 -
「增强搜索」:相信大家上文看到这个词有点懵,这主要是我针对内部用户搜索习惯做了一些搜索增强处理。之前有跟大家探索过 「milvus 在非中文场景中的搜索质量一般」,所以针对「非中文」的搜索情况,我在 ES 方面做了增强以弥补 mivlus 方面的不足。大概就是在判断用户的搜索词为非中文的情况下,「对 标题、正文 类型的也进行 wildcard的配置而已」,以此来增强 ES 方面的检索命中情况。
总的来说,ES 这块针对文档落库的分类情况,构造了对应的搜索 DSL,也就是前文提到的「四部分的搜索大框架」。其中,当用正则判断出用户搜索词为 「纯数字、变量名」 等非纯中文的情况下,还会通过配置 wildcard 关键字到整个 DSL 配置中,以提升 ES 方面的检索精度。(当然,ES 和 向量的数据处理一样,在落库时也是做了分类的)
召回结果合并
经过各自检索工具的工作后,我们会得到两份召回的数据,所以最后的工作就是怎么整合这两份数据给到用户侧。这一块的工作并不难,更多是要「根据自己的业务场景」来决定一些系数、比例,来组合数据就行了。大概流程如下图所示:
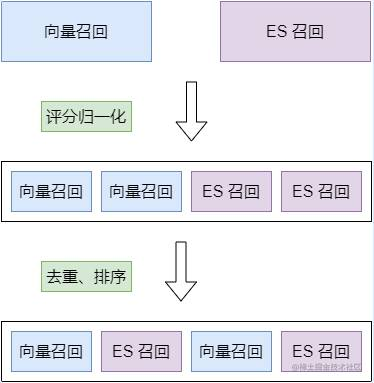
简单总结为:
-
「确定数据比例」。这里的数据比例指 ES 取多少条、milvus 取多少条。首先根据场景,自行决定是 ES 辅助 milvus 还是反过来。我目前是「milvus 辅助 es」,并且根据用户的搜索词类型会调整占比系数,正常时为 6:4,搜索词为变量名、纯数字等情况时会提升到8:2。 -
「评分归一化」。mivlus 和 es 本身的评分体系就不一样,所以采取分别归一化的数学运算来让他们的意义相等。这里我就简单地将每组数据的「分数分别除以他们的最高分」,将他们的得分标准简单地进行统一。 -
「es精细化评分处理」。es 结果乘一个大于 1的系数。因为我的搜索策略是 「milvus 辅助 es」,所以归一化后肯定会出现 es、mivlus 都是1的情况(作为分母的数据一定是1),所以乘个大于1的系数可以「保证 es 的结果排名会优先 mivlus」。 -
「milvus精细化评分处理」。因为通过大量的数据实践对比,我制定了一个 0.7的标准分给 milvus,当 milvus 搜索数据的分数(归一化前)超过0.7时,我会额外给他加一点分。因为经过观察,milvus 照会结果超0.7分时,比较符合业务搜索的期望返回。 -
「数据合并」。这里主要会将 ES、milvus 数据进行去重后合并,其中,去重的时候我会给他们「当前的最高分double」,以提升他的最终排名,毕竟两个搜索引擎都搜出来的结果,我认为他是较为准确的,剩下的就是基于分数排序数据了。
基本上述流程走完,就可以有一个比较符合期望的结果返回到用户侧了。当然上面还有一些细节没展开,比如说搜索词为 变量名、英文 等不同类型时,在评分策略中会有一些系数配置,不过这些都太细了,而且十分耦合我的业务场景,也就没必要一一跟大家分享了。总之,大概的流程就是这样,中间还有很多小细节可以优化处理,但是这一部分的工作更加需要契合当前的搜索业务。
总结
本文通过用 ES + milvus 的方式来实战全文检索业务,向大家介绍了内部文档搜索业务的一种实现方案。当然这一套东西还是有很多不完善的地方的,我还没时间对 ES 的 DSL 进行深度优化,只是简单的做了一版,连评分都是 ES 的默认机制算出来的;也没有对模型调优,或者切换其他的模型尝试效果。当前做下来的搜索点击率 65% 也非常一般,不过总算是比单用 ES,或者单用 milvus 的时候要好吧。后续还会持续优化,争取点击率再往上提一提,到时候再写文章来分享吧。