
包阅导读总结
1. 关键词:Go 语言、协程、GMP 模型、线程实现、调度机制
2. 总结:本文深入剖析了 Go 语言协程的原理与实现机制 GMP 模型,介绍了协程的发展历史、线程实现模型,阐述了 GMP 模型的基本概念、设计思想、调度模型、生命周期、调度时机、源码结构和调度启动等核心内容。
3. 主要内容:
– 协程原理与实现
– 发展历史:协程概念追溯到 20 世纪 60 年代,现代网络发展和高并发要求使其重新受重视。
– 线程实现模型:分为内核级、用户级、两级线程模型,差异在于用户线程与内核调度实体的对应关系。
– GMP 模型
– 基本概念:包括 G(Groutine)、M(Machine)、P(Processor)及其细分类型。
– 设计思想:中间态思想、局部性原理、工作窃取机制、动态关联。
– 调度模型:优化传统线程模型,实现高效任务分配与负载均衡,减少阻塞影响。
– 生命周期:分为启动和循环逻辑,体现关键调度步骤。
– 调度时机:结合协同式与抢占式调度,包括主动、被动和抢占式调度。
– GMP 源码
– 基本结构:介绍 G、M、P 的核心数据结构。
– 调度启动:在进程初始化时处理,通过汇编代码启动。
思维导图: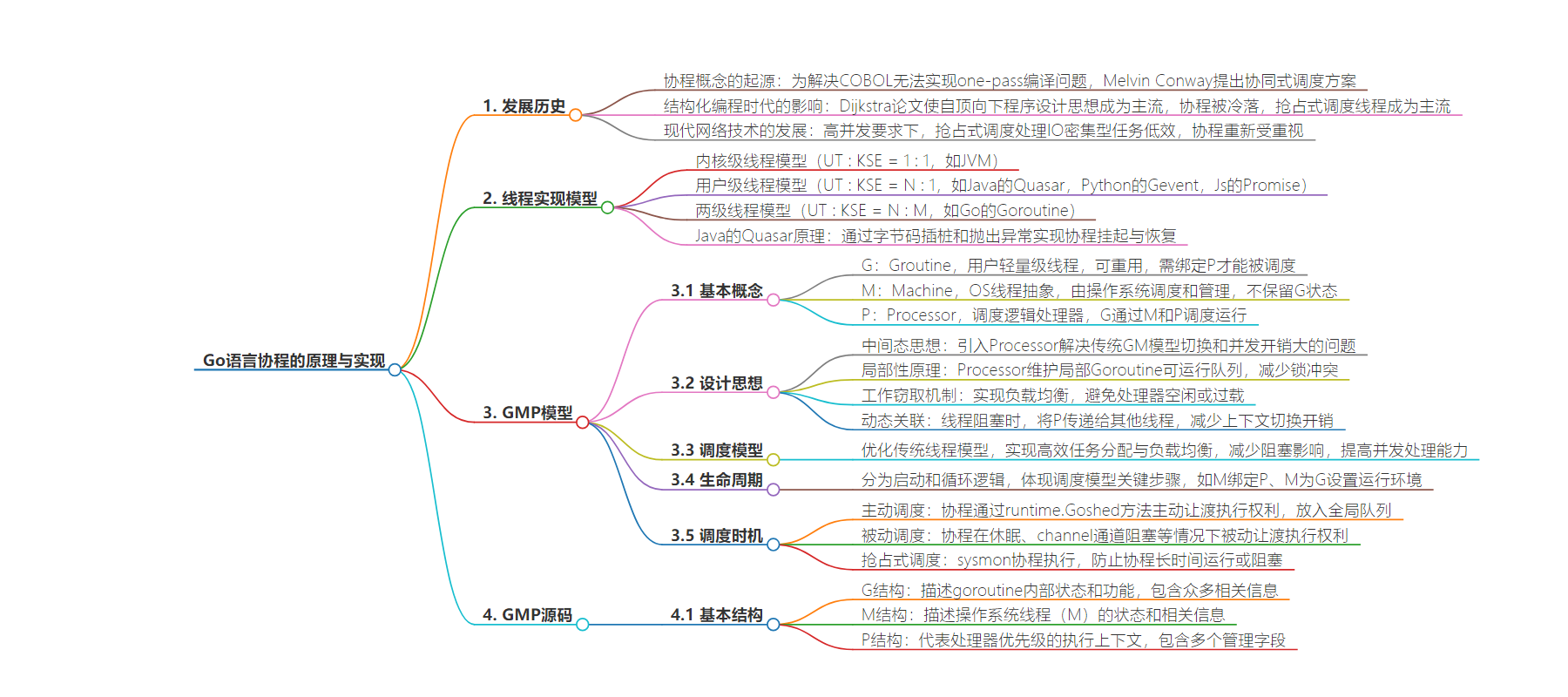
文章地址:https://mp.weixin.qq.com/s/JKPposLgq_rIwsMDwroeqw
文章来源:mp.weixin.qq.com
作者:祭酒
发布时间:2024/9/6 11:59
语言:中文
总字数:12810字
预计阅读时间:52分钟
评分:89分
标签:Go语言,协程,GMP模型,并发编程,调度策略
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
▐发展历史
协程(Coroutine)的概念最早可以追溯到 20 世纪 60 年代,为了解决软硬件限制导致的 COBOL 无法实现 one-pass 编译问题,Melvin Conway 提出了一种协同式调度解决方案:其在编译器设计中将词法分析与语法分析合作运行,而不像其他编译器那样互相独立运行,两个模块来回交织,两个模块都具备让出和恢复的能力。
但在1968年,Dijkstra发表论文 Go To Statement Considered Harmful,结构化编程的理念深入人心,自顶向下的程序设计思想成为主流,协程跳来跳去的执行行为类似 goto 语句,违背自顶向下的设计思想,同时,抢占式调度的线程因其在资源管理、易用性、系统级支持以及对当时硬件环境的适应性等方面的优势,成为了那个时代并发处理的主流选择。
随着现代网络技术的发展和高并发要求,抢占式调度在处理 IO 密集型任务时的低效成为软肋,自2003年起,为了更好的利用 CPU 资源,各类高级语言开始拥抱协程。
▐线程实现模型
协程的实现是基于线程的实现模型,线程的实现模型分为三种:
-
内核级线程模型(UT : KSE = 1 : 1,eg:JVM)
-
用户级线程模型(UT : KSE = N : 1,eg:Java 的 Quasar,Python 的 Gevent,Js 的 Promise)
-
两级线程模型(也称混合型线程模型,UT : KSE = N : M,eg:Go 的 Goroutine )
Java 的 Quasar 的原理:通过字节码插桩和抛出异常的方式实现协程的挂起与恢复,从而允许在单线程中高效地调度多个轻量级的执行单元(Fiber),避免回调地狱并最大化 CPU 资源利用。
他们之间最大的差异在于用户线程(UT)与内核调度实体(KSE)之间的对应关系上。
▐主要特点
-
轻量级,体现在占用资源更小,线程为 MB,协程为 KB;
-
用户级,体现在协程的切换在用户态完成,减少了内核态与用户态切换的开销。
GMP模型

▐基本概念
Golang 协程实现原理是 GMP,三个主要元素:
-
G:Groutine,协程,用户轻量级线程,每个 Goroutine 对应一个 G 结构体,G 存储 Goroutine 的运行堆栈、状态以及任务函数,可重用。当 Goroutine 被调离 CPU 时,调度器代码负责把 CPU 寄存器的值保存在 G 对象的成员变量之中,当 Goroutine 被调度起来运行时,调度器代码又负责把 G 对象的成员变量所保存的寄存器的值恢复到 CPU 的寄存器,G 并非执行体,每个 G 需要绑定到 P 才能被调度执行。
-
M:Machine,OS 线程抽象,代表着真正执行计算的资源,由操作系统的调度器调度和管理。M 结构体对象除了记录着工作线程的诸如栈的起止位置、当前正在执行的 Goroutine 以及是否空闲等等状态信息之外,还通过指针维持着与 P 结构体的实例对象之间的绑定关系,在绑定有效的 P 后,进入 schedule 循环,而 schedule 循环的机制大致是从 Global 队列、P 的 Local 队列以及 wait 队列中获取 G,切换到 G 的执行栈上并执行 G 的函数,调用 goexit 做清理工作并回到 M,如此反复,M 并不保留 G 状态,这是 G 可以跨 M 调度的基础。
-
P:Processor,调度逻辑处理器,G 实际上是由 M 通过 P 来进行调度运行的,对 G 来说,P 相当于 CPU 核,G 只有绑定到 P (在 P 的 local runq 中)才能被调度。对 M 来说,P 提供了相关的执行环境(Context),如内存分配状态(mcache),任务队列(G)等。
其中 G 细分为以下几类:
-
主协程:用来执行用户main函数的协程;
-
主协程创建的协程:也是P调度的主要成员;
-
G0:每个 M 都有一个 G0 协程,是 runtime 的一部分,跟 M 绑定,主要用来执行调度逻辑的代码,不能被抢占也不会被调度(普通 G 也可以执行 runtime_procPin 禁止抢占),G0 的栈是系统分配的,比普通的 G 栈(2KB)要大,不能扩容也不能缩容;
-
sysmon:sysmon 是 runtime 的一部分,直接运行在 M 不需要 P,主要做一些检查工作:检查死锁、检查计时器获取下一个要被触发的计时任务、检查是否有 ready 的网络调用以恢复用户 G 的工作、检查一个 G 是否运行时间太长进行抢占式调度。
其中 M 细分为以下几类:
-
普通 M:用来与 P 绑定执行 G 中任务;
-
m0:Go 程序是一个进程,进程都有一个主线程,m0 就是 Go 程序的主线程,通过一个与其绑定的 G0 来执行 runtime 启动加载代码;一个 Go 程序只有一个 m0;
-
运行 sysmon 的 M:主要用来运行 sysmon 协程。
▐设计思想
-
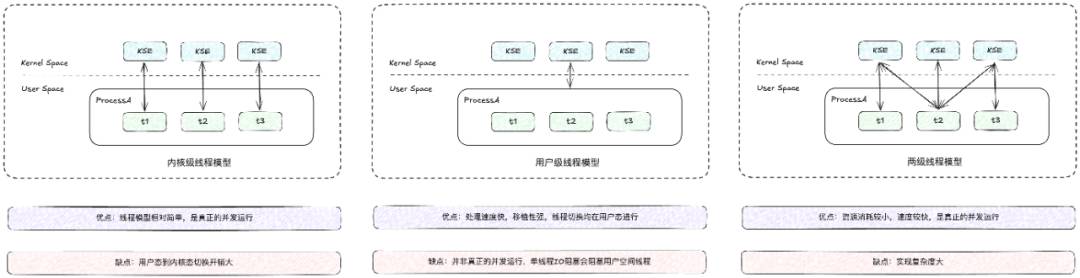
中间态思想:没有什么是加一层中间层不能解决的,传统的线程模型可以理解为 GM 模型(这里的 G 引申为用户的并发任务),为了解决传统 GM 模型的切换开销大(内核态到用户态),并发开销大(线程为 MB 级别,并发数量受内存限制)的问题,Go 语言引入了 一层 Processor 来作为两者的中间态,Processor 的设计进一步细化了并发时分复用的调度粒度,从 MB 到 KB,实现轻量,将内核态用户态的互相切换完整放在用户态执行,实现用户级快速切换。
-
局部性原理:Processor 维护一个局部 Goroutine 可运行 G 队列,工作线程优先使用自己的局部运行队列,只有必要时才会去访问全局运行队列,这可以大大减少锁冲突,提高工作线程的并发性,并且可以良好的运用程序的局部性原理。
-
工作窃取(work stealing机制):work stealing 机制是一种用于提高并发性能的策略,其允许一个处理器(P)在没有可运行的 Goroutine 时,从其他处理器的本地队列中窃取(steal)一些 Goroutine 来执行。这种机制有助于实现负载均衡,避免某些处理器过载而其他处理器空闲的情况。
-
动态关联(Hand off 传递):当一个线程因为系统调用或其他原因阻塞时,GMP 不会让绑定的处理器(P)空闲,而是将当前的 P 传递给另一个线程,以便新线程可以继续执行 P 上的 Goroutine。这有助于减少因线程阻塞导致的上下文切换开销,并保持程序的并发性。
▐调度模型
GMP 调度模型是 Go 语言的核心,通过引入中间态 Processor来 优化传统线程模型,利用局部性原理和工作窃取机制实现高效的任务分配与负载均衡,结合动态关联策略减少阻塞影响,从而整体上大幅提高了并发处理能力,降低了资源消耗,确保了程序能够充分利用多核处理器的并行计算优势,是实现 Go 语言高并发、低延迟特性的关键所在。
根据源码可以整理出如下调度模型,其中体现了上文的核心四条设计思想,详细内容可见源码走读。
▐生命周期
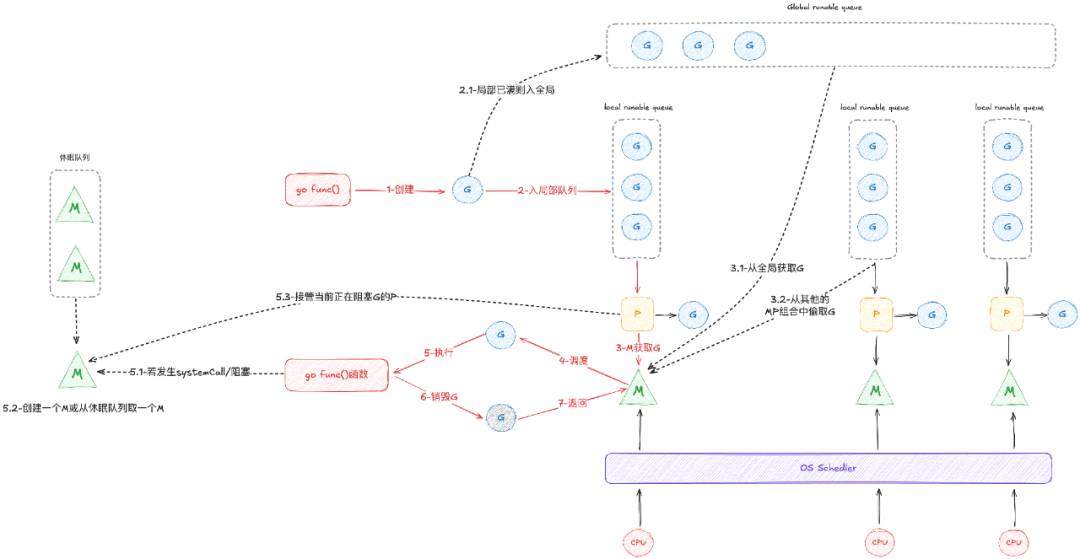
GMP 调度器的生命周期管理是 Go 语言运行时的核心机制,其重要性体现在通过精细控制 G、M、P 的创建、分配与回收,确保了高并发环境下资源的高效利用与程序的正确执行,是实现 Go 轻量级线程高效调度和并行计算能力的基础。
其生命周期主要分为启动和循环逻辑,其中也体现了调度模型中的一些关键步骤比如 M 绑定 P,M 为 G 设置运行环境,详细内容可见源码走读。
▐调度时机
GMP模型结合了协同式调度与抢占式调度的特点,其中主动调度和被动调度体现了协程间的协作,而 sysmon 协程执行的抢占式调度确保了即使协程长时间运行或阻塞也能被及时中断,从而公平高效地分配 CPU 资源。
-
主动调度:协程通过 runtime.Goshed 方法主动让渡自己的执行权利,之后这个协程会被放到全局队列中,等待后续被执行。
-
被动调度:协程在休眠、channel 通道阻塞、网络 I/O 堵塞、执行垃圾回收时被暂停,被动式让渡自己的执行权利。大部分场景都是被动调度,这是 Go 高性能的一个原因,让 M 永远不停歇,不处于等待的协程让出 CPU 资源执行其他任务。
-
抢占式调度:sysmon 协程上的调度,当发现 G 处于系统调用(如调用网络 io )超过 20 微秒或者 G 运行时间过长(超过10ms),会抢占 G 的执行 CPU 资源,让渡给其他协程,防止其他协程没有执行的机会。
GMP源码

Golang 的运行时(runtime)源码结构围绕着 GMP 模型展开,其源码结构如下:
-
runtime/amd_64.s:涉及到进程启动以及对 CPU 执行指令进行控制的汇编代码,进程的初始化部分也在这里面;
-
runtime/runtime2.go:重要数据结构的定义,比如 g、m、p 以及涉及到接口、defer、panic、map、slice 等核心类型;
-
runtime/proc.go:核心方法的实现,涉及 gmp 调度等核心代码在这里。
Runtime:golang 的 runtime 是与用户代码一起打包在一个可执行文件中,是程序的一部分,在 golang 语言中的关键字编译时会变成 runtime 中的函数调用,例如 go 关键字对应 runtime 中的 newproc 函数。
▐基本结构
基本数据结构是源码解读的切入口,特别是 G、M、P 的核心结构,每当要新增逻辑的时候,就需要考虑把状态存在什么位置,阅读基础结构可以对其功能点有个大致的了解,再顺着执行链路,可以大致了解 GMP 的运行流程,相应的代码解读如下:
g struct 详细地描述了一个 goroutine 的内部状态和功能。
其封装了诸如协程栈的边界信息、panic 和 defer 机制的管理、与之关联的 M(内核线程)指针、用于调度和恢复执行的寄存器上下文、goroutine 的生命状态标识、栈锁定机制、唯一的 goroutine ID,以及大量与调度策略、垃圾回收、信号处理、竞态条件检测、性能剖析、通道操作、系统调用、抢占机制、错误处理等等相关的状态。
type g struct {stack stackstackguard0 uintptrstackguard1 uintptr_panic *_panic_defer *_deferm *msched gobufsyscallsp uintptrsyscallpc uintptrsyscallbp uintptrstktopsp uintptrparam unsafe.Pointeratomicstatus atomic.Uint32stackLock uint32goid uint64schedlink guintptrwaitsince int64waitreason waitReasonpreempt boolpreemptStop boolpreemptShrink boolasyncSafePoint boolpaniconfault boolgcscandone boolthrowsplit boolactiveStackChans boolparkingOnChan atomic.BoolinMarkAssist boolcoroexit boolraceignore int8nocgocallback booltracking booltrackingSeq uint8trackingStamp int64runnableTime int64lockedm muintptrsig uint32writebuf []bytesigcode0 uintptrsigcode1 uintptrsigpc uintptrparentGoid uint64gopc uintptrancestors *[]ancestorInfostartpc uintptrracectx uintptrwaiting *sudogcgoCtxt []uintptrlabels unsafe.Pointertimer *timersleepWhen int64selectDone atomic.Uint32goroutineProfiled goroutineProfileStateHoldercoroarg *corotrace gTraceStategcAssistBytes int64}
m struct 描述了 Go 运行时中每个操作系统线程(M)的状态和相关信息。包含指向正在运行的 goroutine (g) 的引用、系统调用相关的字段、堆栈信息、信号处理的指针,以及与内存分配、锁管理和性能分析相关的各种标志和计数器。
type m struct {g0 *gmorebuf gobufdivmod uint32_ uint32procid uint64gsignal *ggoSigStack gsignalStacksigmask sigsettls [tlsSlots]uintptrmstartfn func()curg *gcaughtsig guintptrp puintptrnextp puintptroldp puintptrid int64mallocing int32throwing throwTypepreemptoff stringlocks int32dying int32profilehz int32spinning boolblocked boolnewSigstack boolprintlock int8incgo boolisextra boolisExtraInC boolisExtraInSig boolfreeWait atomic.Uint32needextram booltraceback uint8ncgocall uint64ncgo int32cgoCallersUse atomic.Uint32cgoCallers *cgoCallerspark notealllink *mschedlink muintptrlockedg guintptrcreatestack [32]uintptrlockedExt uint32lockedInt uint32nextwaitm muintptrmLockProfile mLockProfileprofStack []uintptrwaitunlockf func(*g, unsafe.Pointer) boolwaitlock unsafe.PointerwaitTraceSkip intwaitTraceBlockReason traceBlockReasonsyscalltick uint32freelink *mtrace mTraceStatelibcall libcalllibcallpc uintptrlibcallsp uintptrlibcallg guintptrwinsyscall winlibcallvdsoSP uintptrvdsoPC uintptrpreemptGen atomic.Uint32signalPending atomic.Uint32pcvalueCache pcvalueCachedlogPerMmOSchacha8 chacha8rand.Statecheaprand uint64locksHeldLen intlocksHeld [10]heldLockInfo}
p struct 是 Go 语言中的一个核心数据结构,代表了一个处理器优先级的执行上下文。它包含多个字段,分别用于管理处理器的状态、调度信息、内存分配、系统调用计数、工作队列、延迟调用、GC(垃圾回收)相关操作、以及性能监测。
type p struct {id int32status uint32link puintptrschedtick uint32syscalltick uint32sysmontick sysmontickm muintptrmcache *mcachepcache pageCacheraceprocctx uintptrdeferpool []*_deferdeferpoolbuf [32]*_defergoidcache uint64goidcacheend uint64runqhead uint32runqtail uint32runq [256]guintptrrunnext guintptrgFree struct {gListn int32}sudogcache []*sudogsudogbuf [128]*sudogmspancache struct {len intbuf [128]*mspan}pinnerCache *pinnertrace pTraceStatepalloc persistentAllocgcAssistTime int64gcFractionalMarkTime int64limiterEvent limiterEventgcMarkWorkerMode gcMarkWorkerModegcMarkWorkerStartTime int64gcw gcWorkwbBuf wbBufrunSafePointFn uint32statsSeq atomic.Uint32timers timersmaxStackScanDelta int64scannedStackSize uint64scannedStacks uint64preempt boolgcStopTime int64}
▐调度启动
调度器的初始化和启动调度循环是在进程初始化是处理的,Go 进程的启动是通过汇编代码进行的,入口函数在 asm_amd64.s 中的 runtime.rt0_go
get_tls(BX)LEAQ runtime·g0(SB), CXMOVQ CX, g(BX)LEAQ runtime·m0(SB), AXMOVQ CX, m_g0(AX)MOVQ AX, g_m(CX)CALL runtime·check(SB)CALL runtime·args(SB)CALL runtime·osinit(SB)CALL runtime·schedinit(SB)MOVQ $runtime·mainPC(SB), AXPUSHQ AXCALL runtime·newproc(SB)POPQ AXCALL runtime·mstart(SB)
在 runtime 中全局变量 sched 代表全局调度器,数据结构为 schedt 结构体,保存了调度器的状态信息、全局可运行 G 队列。
type schedt struct {goidgen atomic.Uint64lastpoll atomic.Int64pollUntil atomic.Int64lock mutexmidle muintptrnmidle int32nmidlelocked int32mnext int64maxmcount int32nmsys int32nmfreed int64ngsys atomic.Int32pidle puintptrnpidle atomic.Int32nmspinning atomic.Int32needspinning atomic.Uint32runq gQueuerunqsize int32disable struct {user boolrunnable gQueuen int32}gFree struct {lock mutexstack gListnoStack gListn int32}sudoglock mutexsudogcache *sudogdeferlock mutexdeferpool *_deferfreem *mgcwaiting atomic.Boolstopwait int32stopnote notesysmonwait atomic.Boolsysmonnote notesafePointFn func(*p)safePointWait int32safePointNote noteprofilehz int32procresizetime int64totaltime int64sysmonlock mutextimeToRun timeHistogramidleTime atomic.Int64totalMutexWaitTime atomic.Int64stwStoppingTimeGC timeHistogramstwStoppingTimeOther timeHistogramstwTotalTimeGC timeHistogramstwTotalTimeOther timeHistogramtotalRuntimeLockWaitTime atomic.Int64}
func schedinit() {lockInit(&sched.lock, lockRankSched)lockInit(&sched.sysmonlock, lockRankSysmon)lockInit(&sched.deferlock, lockRankDefer)lockInit(&sched.sudoglock, lockRankSudog)lockInit(&deadlock, lockRankDeadlock)lockInit(&paniclk, lockRankPanic)lockInit(&allglock, lockRankAllg)lockInit(&allpLock, lockRankAllp)lockInit(&reflectOffs.lock, lockRankReflectOffs)lockInit(&finlock, lockRankFin)lockInit(&cpuprof.lock, lockRankCpuprof)allocmLock.init(lockRankAllocmR, lockRankAllocmRInternal, lockRankAllocmW)execLock.init(lockRankExecR, lockRankExecRInternal, lockRankExecW)traceLockInit()lockInit(&memstats.heapStats.noPLock, lockRankLeafRank)gp := getg()if raceenabled {gp.racectx, raceprocctx0 = raceinit()}sched.maxmcount = 10000crashFD.Store(^uintptr(0))worldStopped()ticks.init()moduledataverify()stackinit()mallocinit()godebug := getGodebugEarly()cpuinit(godebug)randinit()alginit()mcommoninit(gp.m, -1)modulesinit()typelinksinit()itabsinit()stkobjinit()sigsave(&gp.m.sigmask)initSigmask = gp.m.sigmaskgoargs()goenvs()secure()checkfds()parsedebugvars()gcinit()gcrash.stack = stackalloc(16384)gcrash.stackguard0 = gcrash.stack.lo + 1000gcrash.stackguard1 = gcrash.stack.lo + 1000if disableMemoryProfiling {MemProfileRate = 0}mProfStackInit(gp.m)lock(&sched.lock)sched.lastpoll.Store(nanotime())procs := ncpuif n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {procs = n}if procresize(procs) != nil {throw("unknown runnable goroutine during bootstrap")}unlock(&sched.lock)worldStarted()if buildVersion == "" {buildVersion = "unknown"}if len(modinfo) == 1 {modinfo = ""}}
调度系统时在 runtime.mstart0 函数中启动,这个函数是在 m0 的 g0 上执行的。
func mstart0() {gp := getg()osStack := gp.stack.lo == 0if osStack {size := gp.stack.hiif size == 0 {size = 16384 * sys.StackGuardMultiplier}gp.stack.hi = uintptr(noescape(unsafe.Pointer(&size)))gp.stack.lo = gp.stack.hi - size + 1024}gp.stackguard0 = gp.stack.lo + stackGuardgp.stackguard1 = gp.stackguard0mstart1()if mStackIsSystemAllocated() {osStack = true}mexit(osStack)}func mstart1() {gp := getg()if gp != gp.m.g0 {throw("bad runtime·mstart")}gp.sched.g = guintptr(unsafe.Pointer(gp))gp.sched.pc = getcallerpc()gp.sched.sp = getcallersp()asminit()minit()if gp.m == &m0 {mstartm0()}if fn := gp.m.mstartfn; fn != nil {fn()}if gp.m != &m0 {acquirep(gp.m.nextp.ptr())gp.m.nextp = 0}schedule()}
当经过初始的调度,主协程获取执行权后,首先进入的就是 runtime.main 函数。
func main() {mp := getg().mmp.g0.racectx = 0if goarch.PtrSize == 8 {maxstacksize = 1000000000} else {maxstacksize = 250000000}maxstackceiling = 2 * maxstacksizemainStarted = trueif haveSysmon {systemstack(func() {newm(sysmon, nil, -1)})}lockOSThread()if mp != &m0 {throw("runtime.main not on m0")}runtimeInitTime = nanotime()if runtimeInitTime == 0 {throw("nanotime returning zero")}if debug.inittrace != 0 {inittrace.id = getg().goidinittrace.active = true}doInit(runtime_inittasks)needUnlock := truedefer func() {if needUnlock {unlockOSThread()}}()gcenable()main_init_done = make(chan bool)if iscgo {if _cgo_pthread_key_created == nil {throw("_cgo_pthread_key_created missing")}if _cgo_thread_start == nil {throw("_cgo_thread_start missing")}if GOOS != "windows" {if _cgo_setenv == nil {throw("_cgo_setenv missing")}if _cgo_unsetenv == nil {throw("_cgo_unsetenv missing")}}if _cgo_notify_runtime_init_done == nil {throw("_cgo_notify_runtime_init_done missing")}if set_crosscall2 == nil {throw("set_crosscall2 missing")}set_crosscall2()startTemplateThread()cgocall(_cgo_notify_runtime_init_done, nil)}for m := &firstmoduledata; m != nil; m = m.next {doInit(m.inittasks)}inittrace.active = falseclose(main_init_done)needUnlock = falseunlockOSThread()if isarchive || islibrary {return}fn := main_mainfn()if raceenabled {runExitHooks(0)racefini()}if runningPanicDefers.Load() != 0 {for c := 0; c < 1000; c++ {if runningPanicDefers.Load() == 0 {break}Gosched()}}if panicking.Load() != 0 {gopark(nil, nil, waitReasonPanicWait, traceBlockForever, 1)}runExitHooks(0)exit(0)for {var x *int32*x = 0}}
▐调度循环
调度循环启动之后,便会进入一个无限循环中,不断的执行以下循环 :
-
schedule
-
execute
-
gogo
-
goroutine任务
-
goexit
-
goexit1
-
mcall
-
goexit0
-
schedule
其中调度的过程是在 m 的 g0 上执行的,而 goroutine 任务 -> goexit -> goexit1 -> mcall 则是在 goroutine 的堆栈空间上执行的。
func schedule() {mp := getg().mif mp.locks != 0 {throw("schedule: holding locks")}if mp.lockedg != 0 {stoplockedm()execute(mp.lockedg.ptr(), false)}if mp.incgo {throw("schedule: in cgo")}top:pp := mp.p.ptr()pp.preempt = falseif mp.spinning && (pp.runnext != 0 || pp.runqhead != pp.runqtail) {throw("schedule: spinning with local work")}gp, inheritTime, tryWakeP := findRunnable()if debug.dontfreezetheworld > 0 && freezing.Load() {lock(&deadlock)lock(&deadlock)}if mp.spinning {resetspinning()}if sched.disable.user && !schedEnabled(gp) {lock(&sched.lock)if schedEnabled(gp) {unlock(&sched.lock)} else {sched.disable.runnable.pushBack(gp)sched.disable.n++unlock(&sched.lock)goto top}}if tryWakeP {wakep()}if gp.lockedm != 0 {startlockedm(gp)goto top}execute(gp, inheritTime)}
findrunnalbe 中首先从本地队列中检查,然后从全局队列中寻找,再从就绪的网络协程,如果这几个没有就去其他 p 的本地队列偷一些任务。
func findRunnable() (gp *g, inheritTime, tryWakeP bool) {mp := getg().mtop:pp := mp.p.ptr()if sched.gcwaiting.Load() {gcstopm()goto top}if pp.runSafePointFn != 0 {runSafePointFn()}now, pollUntil, _ := pp.timers.check(0)if traceEnabled() || traceShuttingDown() {gp := traceReader()if gp != nil {trace := traceAcquire()casgstatus(gp, _Gwaiting, _Grunnable)if trace.ok() {trace.GoUnpark(gp, 0)traceRelease(trace)}return gp, false, true}}if gcBlackenEnabled != 0 {gp, tnow := gcController.findRunnableGCWorker(pp, now)if gp != nil {return gp, false, true}now = tnow}if pp.schedtick%61 == 0 && sched.runqsize > 0 {lock(&sched.lock)gp := globrunqget(pp, 1)unlock(&sched.lock)if gp != nil {return gp, false, false}}if fingStatus.Load()&(fingWait|fingWake) == fingWait|fingWake {if gp := wakefing(); gp != nil {ready(gp, 0, true)}}if *cgo_yield != nil {asmcgocall(*cgo_yield, nil)}if gp, inheritTime := runqget(pp); gp != nil {return gp, inheritTime, false}if sched.runqsize != 0 {lock(&sched.lock)gp := globrunqget(pp, 0)unlock(&sched.lock)if gp != nil {return gp, false, false}}if netpollinited() && netpollAnyWaiters() && sched.lastpoll.Load() != 0 {if list, delta := netpoll(0); !list.empty() {gp := list.pop()injectglist(&list)netpollAdjustWaiters(delta)trace := traceAcquire()casgstatus(gp, _Gwaiting, _Grunnable)if trace.ok() {trace.GoUnpark(gp, 0)traceRelease(trace)}return gp, false, false}}if mp.spinning || 2*sched.nmspinning.Load() < gomaxprocs-sched.npidle.Load() {if !mp.spinning {mp.becomeSpinning()}gp, inheritTime, tnow, w, newWork := stealWork(now)if gp != nil {return gp, inheritTime, false}if newWork {goto top}now = tnowif w != 0 && (pollUntil == 0 || w < pollUntil) {pollUntil = w}}...}
整个函数的主要目的:
-
将一个准备运行的 goroutine (gp) 切换到运行状态(_Grunning);
-
确保在切换期间做出必要的状态更新和性能分析记录;
-
处理 M(机器状态)与 G(goroutine)之间的关联,确保资源的正确分配与管理;
-
考虑多线程环境中的调度与性能监控,保证程序的健壮性和性能有效性。
func execute(gp *g, inheritTime bool) {mp := getg().mif goroutineProfile.active {tryRecordGoroutineProfile(gp, nil, osyield)}mp.curg = gpgp.m = mpcasgstatus(gp, _Grunnable, _Grunning)gp.waitsince = 0gp.preempt = falsegp.stackguard0 = gp.stack.lo + stackGuardif !inheritTime {mp.p.ptr().schedtick++}hz := sched.profilehzif mp.profilehz != hz {setThreadCPUProfiler(hz)}trace := traceAcquire()if trace.ok() {trace.GoStart()traceRelease(trace)}gogo(&gp.sched)}
gogo 由汇编实现,主要是由 g0 切换到 g 栈,然后执行函数。
// src/runtime/asm_amd64.sTEXT runtime·gogo(SB), NOSPLIT, $0-8// gobufMOVQ buf+0(FP), BXMOVQ gobuf_g(BX), DX// make sure g != nilMOVQ 0(DX), CXJMP gogo<>(SB)
当调用任务函数结束返回的时候,会执行到在创建 g 流程中就初始化好的指令:goexit
// src/runtime/asm_arm64.sTEXT runtime·goexit(SB),NOSPLIT|NOFRAME|TOPFRAME,$0-0MOVD R0, R0BL runtime·goexit1(SB)
func goexit1() {if raceenabled {racegoend()}trace := traceAcquire()if trace.ok() {trace.GoEnd()traceRelease(trace)}mcall(goexit0)}func goexit0(gp *g) {gdestroy(gp)schedule()}
▐调度时机
协程可以选择主动让渡自己的执行权利,大多数情况下不需要这么做,但通过 runtime.Goched 可以做到主动让渡。
Gosched 函数用于显式告诉调度器,现在可以切换到其他 goroutine。这是通过用户请求而非系统决定的方式切换 goroutine。
func Gosched() {checkTimeouts()mcall(gosched_m)}func gosched_m(gp *g) {goschedImpl(gp, false)}func goschedImpl(gp *g, preempted bool) {trace := traceAcquire()status := readgstatus(gp)if status&^_Gscan != _Grunning {dumpgstatus(gp)throw("bad g status")}if trace.ok() {if preempted {trace.GoPreempt()} else {trace.GoSched()}}casgstatus(gp, _Grunning, _Grunnable)if trace.ok() {traceRelease(trace)}dropg()lock(&sched.lock)globrunqput(gp)unlock(&sched.lock)if mainStarted {wakep()}schedule()}
大部分情况下的调度都是被动调度,当协程在休眠、channel 通道阻塞、网络 IO 阻塞、执行垃圾回收时会暂停,被动调度可以保证最大化利用 CPU 资源。被动调度是协程发起的操作,所以调度时机相对明确。
首先从当前栈切换到 g0 协程,被动调度不会将 G 放入全局运行队列,所以被动调度需要一个额外的唤醒机制。
这里面涉及的函数主要是 gopark 和 ready 函数,gopark 函数用来完成被动调度,由_ Grunning 变为 _Gwaiting 状态。
func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceReason traceBlockReason, traceskip int) {if reason != waitReasonSleep {checkTimeouts()}mp := acquirem()gp := mp.curgstatus := readgstatus(gp)if status != _Grunning && status != _Gscanrunning {throw("gopark: bad g status")}mp.waitlock = lockmp.waitunlockf = unlockfgp.waitreason = reasonmp.waitTraceBlockReason = traceReasonmp.waitTraceSkip = traceskipreleasem(mp)mcall(park_m)}func park_m(gp *g) {mp := getg().mtrace := traceAcquire()if trace.ok() {trace.GoPark(mp.waitTraceBlockReason, mp.waitTraceSkip)}casgstatus(gp, _Grunning, _Gwaiting)if trace.ok() {traceRelease(trace)}dropg()if fn := mp.waitunlockf; fn != nil {ok := fn(gp, mp.waitlock)mp.waitunlockf = nilmp.waitlock = nilif !ok {trace := traceAcquire()casgstatus(gp, _Gwaiting, _Grunnable)if trace.ok() {trace.GoUnpark(gp, 2)traceRelease(trace)}execute(gp, true)}}schedule()}
如果一个 g 运行时间过长就会导致其他 g 难以获取运行机会,当进行系统调用时也存在会导致其他 g 无法运行情况;当出现这两种情况时,为了让其他 g 有运行机会,则会进行抢占式调度。
func retake(now int64) uint32 {n := 0lock(&allpLock)for i := 0; i < len(allp); i++ {pp := allp[i]if pp == nil {continue}pd := &pp.sysmonticks := pp.statussysretake := falseif s == _Prunning || s == _Psyscall {t := int64(pp.schedtick)if int64(pd.schedtick) != t {pd.schedtick = uint32(t)pd.schedwhen = now} else if pd.schedwhen+forcePreemptNS <= now {preemptone(pp)sysretake = true}}if s == _Psyscall {t := int64(pp.syscalltick)if !sysretake && int64(pd.syscalltick) != t {pd.syscalltick = uint32(t)pd.syscallwhen = nowcontinue}if runqempty(pp) && sched.nmspinning.Load()+sched.npidle.Load() > 0 && pd.syscallwhen+10*1000*1000 > now {continue}unlock(&allpLock)incidlelocked(-1)trace := traceAcquire()if atomic.Cas(&pp.status, s, _Pidle) {if trace.ok() {trace.ProcSteal(pp, false)traceRelease(trace)}n++pp.syscalltick++handoffp(pp)} else if trace.ok() {traceRelease(trace)}incidlelocked(1)lock(&allpLock)}}unlock(&allpLock)return uint32(n)}

结语
总之,本文是一篇关于协程原理与实现的深度解析,重点聚焦于Golang的GMP模型,通过历史背景、理论基础、源码分析等多个维度,全面阐述了协程在现代软件开发中的应用与优化策略。