
包阅导读总结
1. 关键词:Linux 内存、回收机制、水线、IO 打满、hungtask
2. 总结:本文介绍了 Linux 内存变低时的处理机制,包括内存回收、规整、oom-kill,核心函数`__alloc_pages_nodemask`的处理逻辑,内存管理的三条水线,内存回收时磁盘 IO 打满和低内存引发 hungtask 的原因,以及优化低内存处理的方法。
3. 主要内容:
– 内存不足的处理机制:
– 内存回收、规整、oom-kill 三种机制。
– 内存申请的核心函数:
– `__alloc_pages_nodemask`先尝试从伙伴系统的 freelist 拿空闲页,失败则进入慢速路径。
– 慢速路径先唤醒 `kswapd` 回收内存,若不行则进入 `direct_reclaim` 直接回收,再不行做内存规整,最后 oom-kill。
– 三条水线:
– `MIN`、`LOW`、`HIGH`,可用内存低于 `LOW` 唤醒 `kswapd`,低于 `MIN` 进行 `direct reclaim`。
– 内存回收与磁盘 IO:
– `kswapd` 和 `direct_reclaim` 最终都走到 `shrink_node` 核心函数。
– 回收文件页会产生 IO,内存回收倾向于回收文件页。
– 低内存引发 hungtask:
– 大量进程 `direct reclaim` 导致 IO 打满,进程被阻塞超 120S 触发。
– 同步机制接口 `uninterruptible` 性质易引发连锁反应。
– 优化低内存处理:
– 调整脏页回刷频率。
– 调高 `low` 水线和 `min` 水线。
思维导图: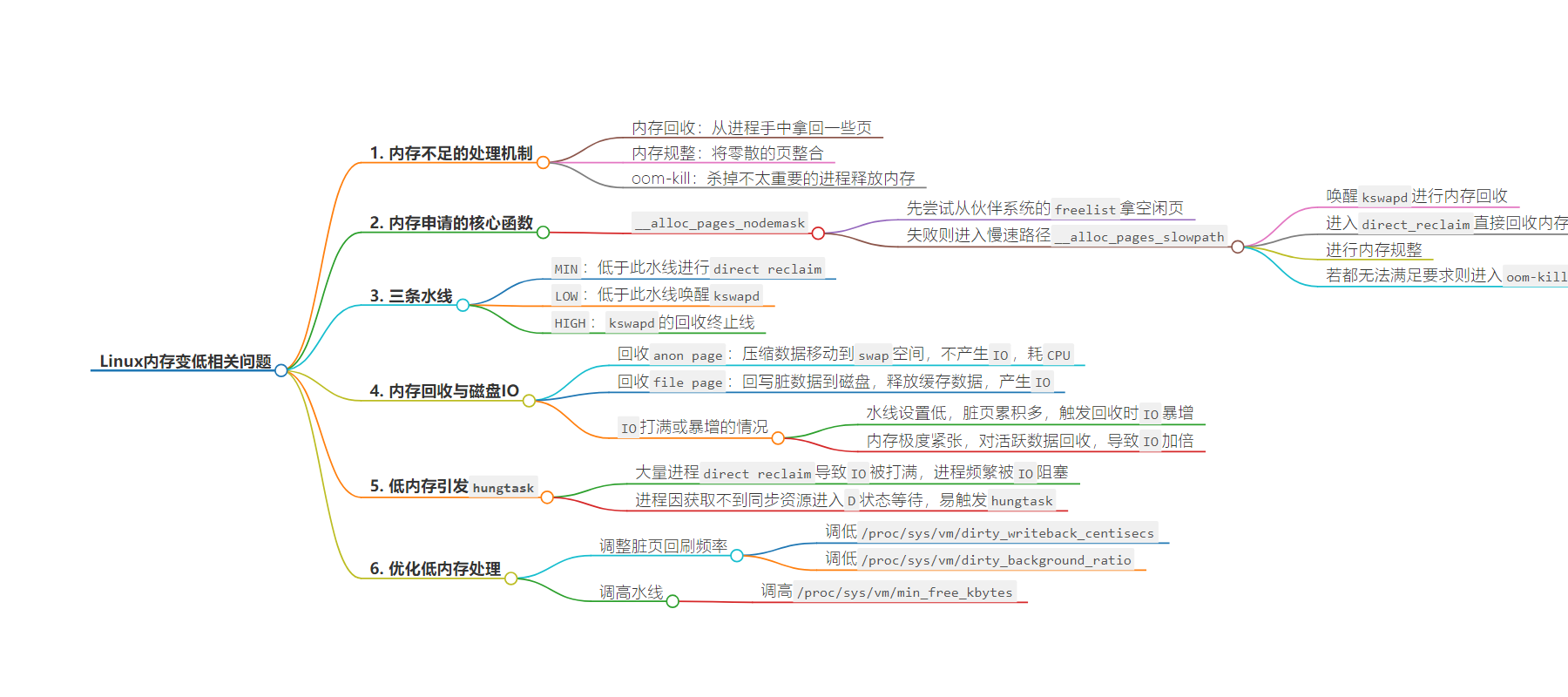
文章地址:https://mp.weixin.qq.com/s/c2y36IH-4mRwhR-xvvdqGw
文章来源:mp.weixin.qq.com
作者:腾讯程序员
发布时间:2024/9/9 8:49
语言:中文
总字数:3643字
预计阅读时间:15分钟
评分:86分
标签:Linux内核,内存管理,性能优化,系统稳定性,磁盘IO
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

作者:cynrikluo
内存不是无限的,总有不够用的时候,linux内核用三个机制来处理这种情况:内存回收、内存规整、oom-kill。
当发现内存不足时,内核会先尝试内存回收,从一些进程手里拿回一些页;如果这样还是不能满足申请需求,则触发内存规整;再不行,则触发oom主动kill掉一个不太重要的进程,释放内存。
低内存情况下,内核的处理逻辑
内存申请的核心函数是__alloc_pages_nodemask:
/*
*Thisisthe'heart'ofthezonedbuddyallocator.
*/
structpage*
__alloc_pages_nodemask(gfp_tgfp_mask,unsignedintorder,intpreferred_nid,
nodemask_t*nodemask)
{
structpage*page;
unsignedintalloc_flags=ALLOC_WMARK_LOW;
gfp_talloc_mask;/*Thegfp_tthatwasactuallyusedforallocation*/
structalloc_contextac={};
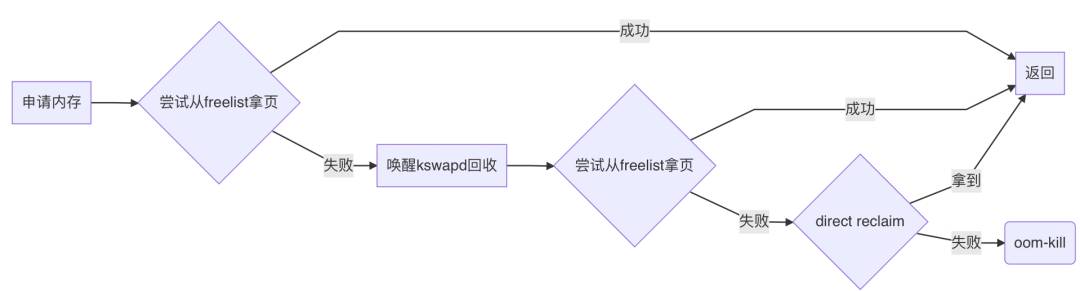
__alloc_pages_nodemask会先尝试调用get_page_from_freelist从伙伴系统的freelist里拿空闲页,如果能拿到就直接返回:
如果拿不到,则进入慢速路径:
__alloc_pages_slowpath,慢速路径,顾名思义,就是拿得慢一点,需要做一些操作以后再拿。
首先, __alloc_pages_slowpath会唤醒kswapd:
kswapd是一个守护进程,专门进行内存回收操作,执行路径:

它被唤醒后,会立1刻开始进行回收,效率高的话,freelist上会立刻多出很多空闲页。
所以 __alloc_pages_slowpath会马上再次尝试从freelist获取页面,获取成功则直接返回了。
若还是失败, __alloc_pages_slowpath则会进入direct_reclaim阶段:
direct_reclaim,顾名思义,就是直接内存回收,回收到的页不用放回freelist再get_page_from_freelist这么麻烦了,也不用唤醒某个进程帮忙回收,而是由当前进程(current)亲自下场去回收,执行路径:

如果direct_reclaim也回收不上来, __alloc_pages_slowpath还会垂死挣扎下,做一下内存规整,尝试把零散的页辗转腾挪,拼成为大order页(仅在申请order>0的页时有用)。
如果还是无法满足要求,则进入oom-kill了:
总结上面的逻辑:内存申请时,首先尝试直接从freelist里拿;失败了则先唤醒kswapd帮忙回收内存;若内存低到让kswapd也爱莫能助,则进入direct reclaim直接回收内存;若direct reclaim也无能为力,则oom:
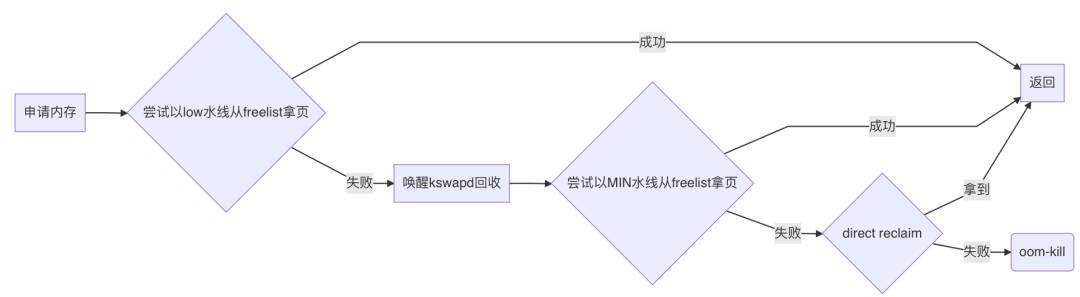
三条水线
实际上,从freelist上拿页不是简单地直接拿,而是先检查下该zone是否满足水线要求,不满足那就直接失败。
内核给内存管理划了三条水线:MIN、LOW、HIGH。
三者大小关系从字面即可推断,MIN < LOW < HIGH。
在首次尝试从freelist拿页时,门槛水线是LOW;唤醒kswapd后再次尝试拿页,门槛水线是MIN。
所以实际逻辑如下:
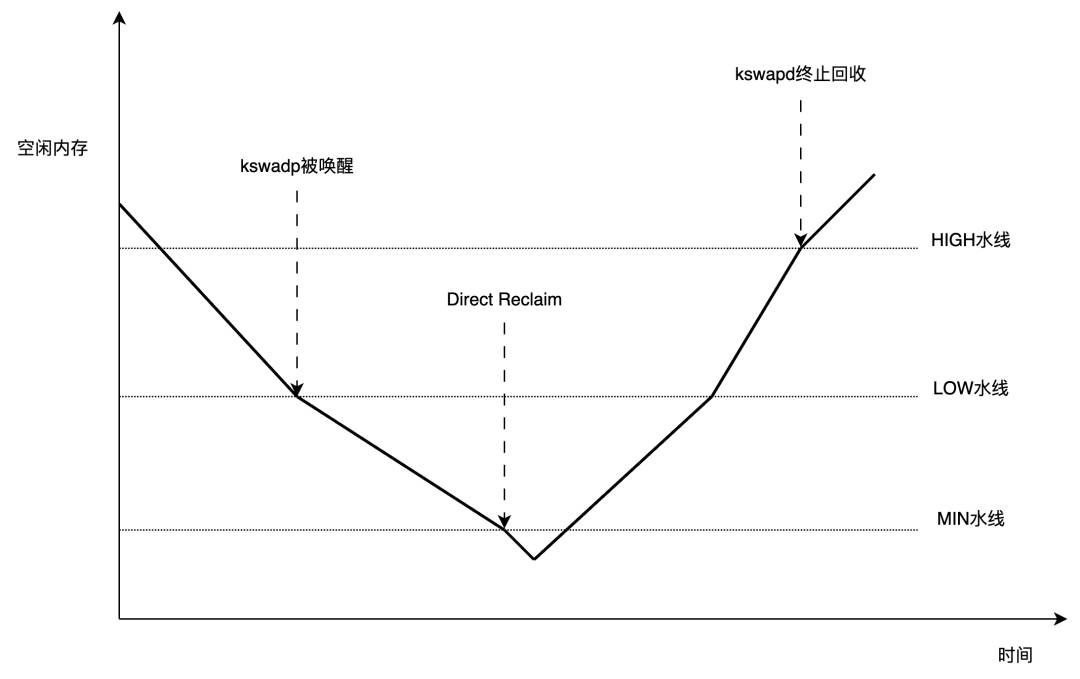
所以,可以简单地认为,可用内存低于LOW水线时,唤醒kswapd;低于MIN水线时,进行direct reclaim;而HIGH水线,是kswapd的回收终止线:
为什么内存回收时,磁盘IO会被打满?
可以看到,kswapd和direct_reclaim最终都是走到了shrink_node:

shrink_node是内存回收的核心函数,顾名思义,让整个node进行一次“收缩”,把不要的数据清掉,空出空闲页。

get_scan_count决定本次扫描多少个anon page和file page。
anon page就是Anonymous Page,匿名页,是进程的堆栈、数据段等。内核回收匿名页时,将这些数据进行压缩(压缩比大概为3),然后移动到内存中的一个小角落中(swap空间),这个过程并没有与磁盘发生交互,因此不会产生IO,但需要压缩数据,所以耗CPU。
file page就是文件页,是进程的代码段、映射的文件。内核回收文件页时,先将“脏”数据回写到磁盘,然后释放掉这些缓存数据,干净的数据则直接释放掉。这个过程涉及到写磁盘,因此会产生IO。
简单总结一下get_scan_count的逻辑:
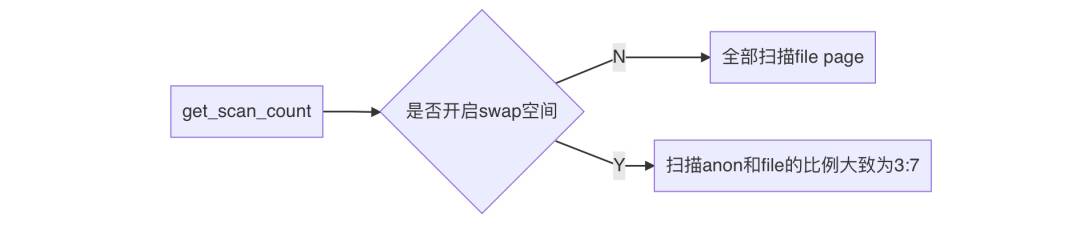
所以说,不论开没开swap,内存回收都是倾向于回收file page。
如果file page中有脏页,那内存回收大概率就会产生一些IO,无非是IO量多少罢了。
以下情况IO可能会打满或者暴增
-
当前内存不是特别紧张,但low、min水线设置得太低,之前一直没怎么触发过内存回收,以致于脏页已经累积到大量,一触发回收,立刻就是回写大量脏页,导致IO暴增。 -
内存极度紧张 (free 和available同时很低)。这种情况下,anon page远比file page多,这意味着可回收的内存很少,内核会对活跃数据下手,一些进程上一秒还用着的数据,这一秒可能就被不幸回收了,但下一秒马上又要被使用,会再次被读入内存。如此,同一份数据,内核就进行了多次回收和读入,IO就加倍了。
为什么低内存有时会引发hungtask?
低内存时,通常不是个别进程触发了direct reclaim,而是大量进程都在direct reclaim。
大家都要回写脏页,于是IO被打满了。
这时候,进程会频繁地被IO阻塞,被阻塞的进程为了不占用CPU,会调用io_schedule_timeout或io_schedule来挂起自己,直到IO完成。
这种等待是D状态的,一旦超过了120S,就会触发hungtask。当然,这是非常极端的情况,IO已经完全没救的情况。
大部分时候,IO虽然打满了,但是总能周转过来,所以这些进程并不会等太久。
然而,这些进程若是来自同一个业务,则大概率会访问同一个数据,这就需要通过mutex、rwsem、semaphore等同步机制来控制访问行为。
而这些同步机制的基本接口都是uninterruptible性质的,以semaphore为例:
externvoiddown(structsemaphore*sem);//基本接口。获取信号量,获取不到则进入uninterruptible睡眠
externint__must_checkdown_interruptible(structsemaphore*sem);//其他接口
externint__must_checkdown_killable(structsemaphore*sem);//其他接口
externint__must_checkdown_trylock(structsemaphore*sem);//其他接口
externint__must_checkdown_timeout(structsemaphore*sem,longjiffies);//其他接口
所谓uninterruptible性质,即当进程获取不到同步资源时,直接进入D状态等待其他进程释放资源。
其他同步资源,rwsem、mutex等,都有这样的uninterruptible性质接口。
正常情况下,只要持有同步资源的进程正常运行不卡顿,那么即使有上百个进程来争抢这些同步资源,对于排序靠后的进程来说,时间也是够的,一般不会等待超过120s。
但在低内存情况下,大家都在等IO,这些持有资源的进程也不能幸免,引发堵车连锁反应。
如果此时同步资源的waiter们已累计了几十个甚至上百个,那么就算只有一瞬间的io卡顿,排序靠后的waiter也容易等待超过120s,触发hungtask。
一个非常典型的案例,一台CVM在连续报了几条hungtask warning后,彻底无响应了,通过魔术建触发重启。
系统信息如下:
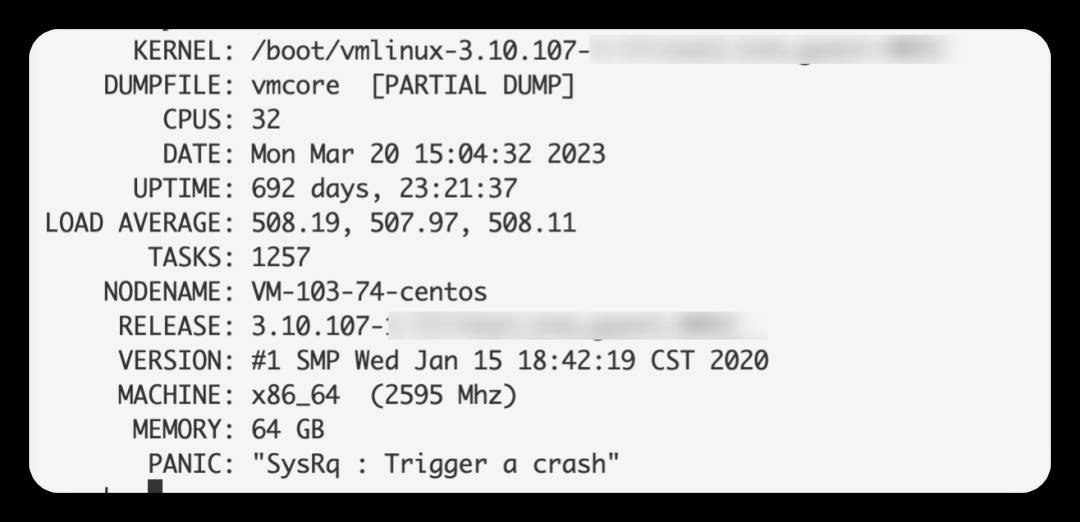
内存状况不容乐观,典型的低内存:

log上有很多hungtask warning,超时原因都是等rwsem太长,写者waiter和读者waiter都有:

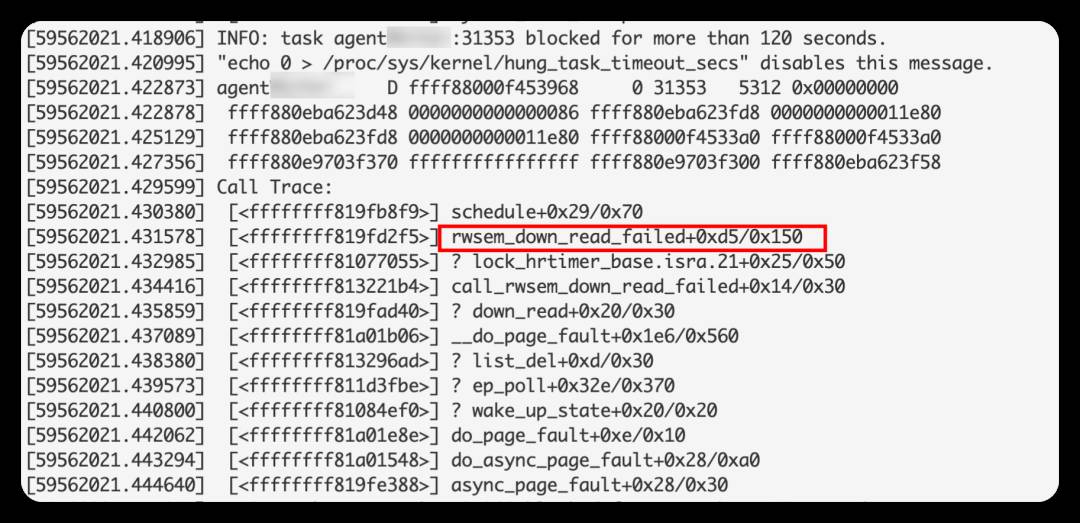
这些进程在等同一个rwsem,这个rwsem的地址为:ffff880e9703f370
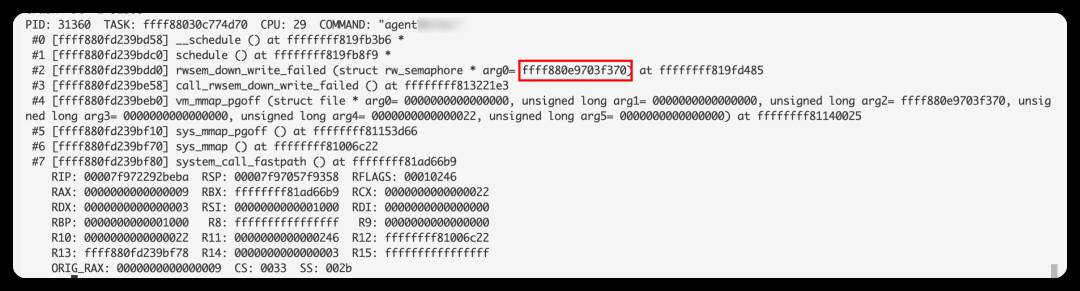
进一步探究,发现当前对ffff880e9703f370有引用的进程为19个,11个正在读,8个排队。
而这11个正在读的进程,都在做同一件事——direct reclaim,并且都卡在IO等待:
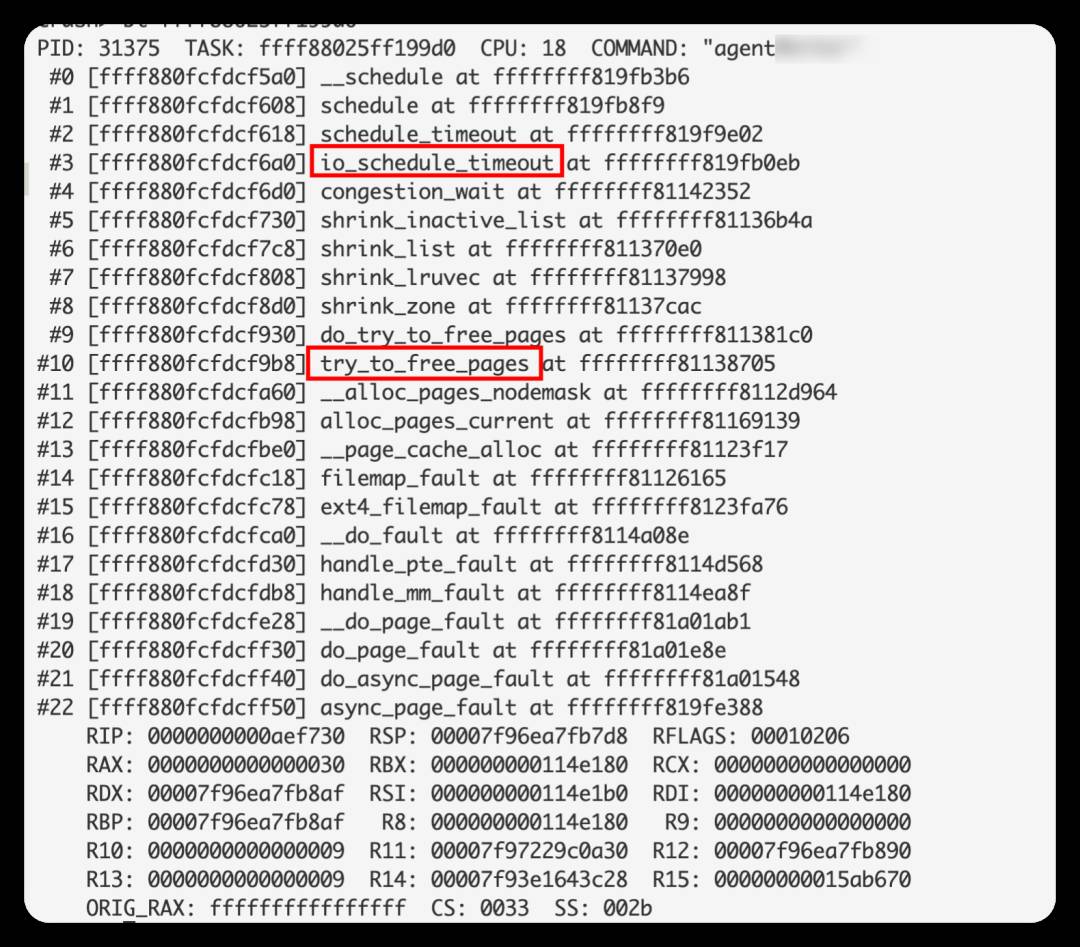
这11个进程,虽然也是D状态,但由于时不时能调度到IO,相当于D状态的持续时间不断重置,所以本身并没有触发hungtask。
而这8个waiter进程就没这个好运了,被前面11个进程你方唱罢我登场地阻塞,持续时间也没有机会重置,最终超过120s,引发hungtask了。
优化低内存处理
我们已经知道了低内存会导致IO突增,甚至导致hungtask,那要如何避免呢?
可以从两方面来避免。
1、调整脏页回刷频率。
将平时的脏页回刷频率调高,这样内存回收时,需要回收的脏页就更少,降低IO的增量。
-
调低 /proc/sys/vm/dirty_writeback_centisecs -
调低 /proc/sys/vm/dirty_background_ratio
2、调高low水线和min水线。
调高水线,可以更早地进入内存回收逻辑,这样可以将free维持在一个较高水平,避免陷入极端场景。由于low和min同时受min_free_kbytes管控,所以可以直接调整min_free_kbytes值。
-
调高 /proc/sys/vm/min_free_kbytes