
包阅导读总结
1. 关键词:Linux、文件完整性监测、eBPF、内核追踪、老内核
2. 总结:本文探讨了在 Linux 中的文件完整性监测,指出 eBPF 是当前主流方案,但在老内核中存在局限。还介绍了老内核可用的替代方案如 inotify、audit 等及其缺点,以及 KProbes 方案和其面临的挑战,最后提到 BTF 对 eBPF 跨内核的便携性的改善。
3.
– 文件完整性监测
– eBPF 是主流方案,能实时内核事件监测,但在老内核因代码复杂等有限制
– 老内核替代方案
– inotify 无法提供进程和用户信息
– audit 系统性能有影响,存在规则冲突问题
– fanotify 不适用老内核
– 老内核其他方案
– KProbes 性能可接受,但缺乏灵活性和稳定 API,依赖内核内部结构
– 便携性
– 早期 eBPF 有跨内核便携性问题,现代 eBPF 用 BTF 改善
– 用户空间程序可独立处理 BTF 元数据
思维导图: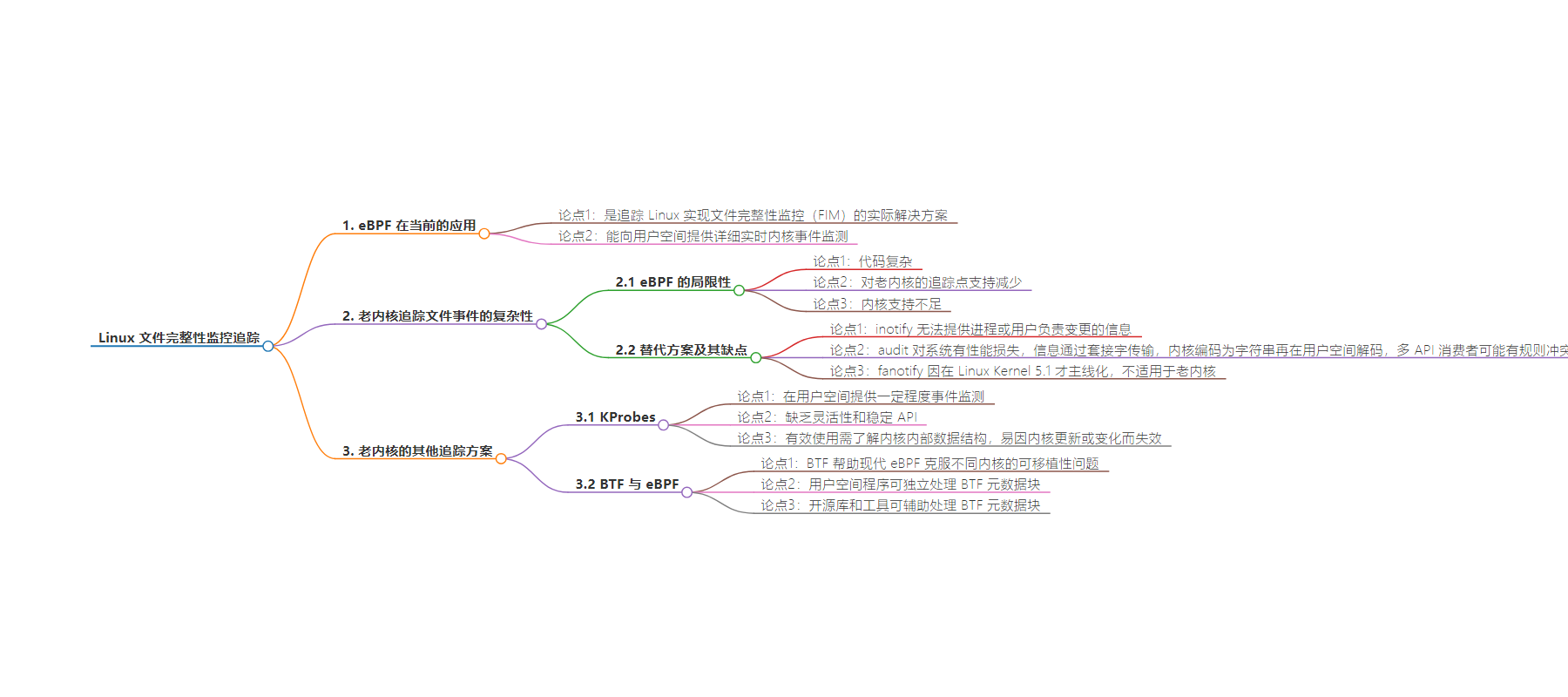
文章地址:https://www.elastic.co/blog/tracing-linux-file-integrity-monitoring-use-case
文章来源:elastic.co
作者:Panos Koutsovasilis
发布时间:2024/6/24 2:17
语言:英文
总字数:1190字
预计阅读时间:5分钟
评分:81分
标签:Beats,追踪,安全
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
In the current landscape of tracing Linux, eBPF emerges as the de-facto solution to implement FIM, facilitating real-time kernel event instrumentation with extensive detail delivered to user space. However, tracing file events with user information on older Linux kernels proves more complex than initially perceived. In such scenarios, eBPF is not always the straightforward choice due to limitations like code complexity, reduced tracepoint support, or lack of kernel support.
For older Linux kernels, alternative solutions can be used to implement an FIM, namely inotify and audit. However, these come with a different set of drawbacks. Specifically, inotify does not provide information about the process or the user responsible for the change. On the other hand, audit imposes a non-negligible performance penalty on the system. This is because all information is transmitted from the kernel to user space through a socket, with the kernel encoding everything into strings that must then be decoded in user space. Additionally, audit’s design can lead to interference issues when multiple API consumers require different rules, resulting in conflicts and reduced efficiency. Another potential solution is fanotify; however, it is worth mentioning only for completeness since it was mainlined in Linux Kernel 5.1 and is therefore not applicable to older kernels.
Another widely supported kernel tracing solution with an acceptable performance overhead for older kernels is KProbes. Although KProbes provide a level of event instrumentation in user space similar to eBPF, they lack the same degree of flexibility and notably lack a stable API. Utilizing KProbes effectively necessitates understanding kernel internal data structures’ sizes and field offsets relevant to the traced event. This requirement poses a risk of KProbes-based solutions prone to breaking with kernel updates or changes and mandates pre-holding the former structure information.
Similarly to KProbes, the portability challenge across diverse kernels was prevalent in the initial stages of eBPF development. However, modern eBPF has overcome this hurdle using the BPF Type Format (BTF). BTF is a metadata format that encapsulates DWARF-based debug symbols, including data types, sizes, functions, and more, into a blob accessible to eBPF programs at runtime. Consequently, eBPF programs can dynamically adjust their tracepoints based on this information. Modern Linux kernels embed such a blob, enabling eBPF programs to execute seamlessly across different kernel versions.
Despite BTF’s close association with eBPF, a user-space program can independently derive and process this metadata blob. For instance, the ebpf library in Golang enables Go programs to access the BTF blob and leverage its encoded information within their logic. By compiling a kernel with debug symbols and using tools like bpftool, we can extract the BPF metadata blob for KProbe-based programs. Through our experimentation, we achieved this as far back as Linux kernel 3.3. Additionally, the open-source repository btfhub-archive produces and maintains such BTF blobs for known kernel versions of various distributions, facilitating the portability of eBPF programs across Linux kernels that do not embed them.