
包阅导读总结
1. 关键词:LLMs、本地模型、应用开发、用户体验、成本
2. 总结:本文探讨了生成式 AI 从云端模型向本地模型的转变趋势,分析了其原因、可行性及影响,包括降低成本、改善用户体验、保障数据隐私等,还提及这一转变对应用开发者的意义。
3. 主要内容:
– 背景
– 过去计算设备与远程主机连接,如今生成式 AI 架构类似,模型在云端,应用在本地。
– 现状
– 生成式 AI 模型计算量大,因消费者级 GPU 内存有限,工作负载移至数据中心。
– 模型不断变大,但在用户设备上运行现有模型已可行。
– 本地模型的意义
– 改变开发者一切,避免应用因依赖云模型而淘汰。
– 降低成本,消除价格顾虑。
– 改善用户体验,减少对网络连接的依赖。
– 保障数据隐私,支持更多模型变体。
– 可行性
– 多数生成式应用所需模型能在消费硬件上运行。
– 小模型可通过微调、开源模型等提升性能。
– LoRA 使任务特定模型更高效。
– 催化因素
– 硬件方面,苹果等推动设备具备本地运行能力。
– 软件方面,新库更好利用消费级硬件。
– 对应用开发者的影响
– 假设 LLM 推理免费,影响产品构建和定价。
– 开发方式转变,微调成为重点。
思维导图: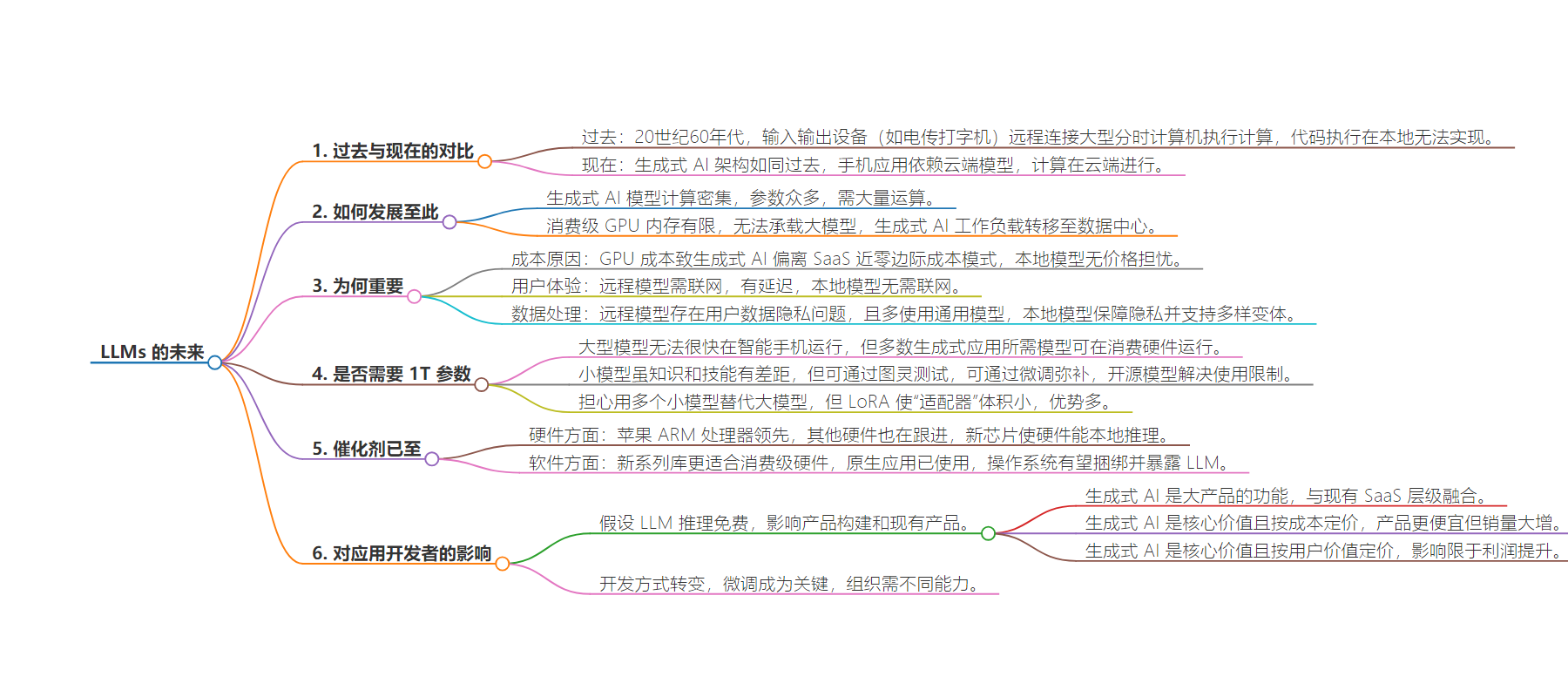
文章地址:https://thenewstack.io/the-future-of-llms-is-in-your-pocket/
文章来源:thenewstack.io
作者:Javier Redondo
发布时间:2024/9/3 21:55
语言:英文
总字数:2380字
预计阅读时间:10分钟
评分:89分
标签:生成式人工智能,本地模型执行,应用程序开发,硬件创新,软件库
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Imagine a world where one device acts as the user interface and is connected remotely to a second device that performs the actual computations. This was common in the 1960s. Teletypes used for inputting commands and outputting results could be found in places like office settings and high school libraries. Code execution, however, was too resource-intensive to be put in every room. Instead, each teletype would connect remotely to a large, time-shared computer among many clients.
The current generative AI architecture is in the teletype era: an app runs on the phone, but it depends on a model that can only be hosted in the cloud. This is a relic of the past. Over the decades, teletypes and mainframes gave way to PCs. Similarly, generative AI will eventually run on consumer-grade hardware — but this transition will happen much more quickly.
And this shift has significant implications for application developers.
How We Got Here
You are probably aware that generative AI models are defined by computationally intensive steps that transform an input (e.g., a prompt) into an output (e.g., an answer). Such models are specified by billions of parameters (aka weights), meaning that producing an output also requires billions of operations that can be parallelized across as many cores as the hardware offers. With thousands of cores, GPUs are an excellent fit for running generative AI models. Unfortunately, because consumer-grade GPUs have limited memory, they can’t hold models that are 10s of GB in size. As a result, generative AI workloads have shifted to data centers featuring a (costly) network of industrial GPUs where resources are pooled.
We keep hearing that the models will “keep getting better” and that, consequently, they will continue to get bigger. We have a contrarian take: While any step function change in model performance can be revolutionary when it arrives, enabling the current generation of models to run on user devices has equally profound implications — and it is already possible today.
Why This Matters
One question to answer before discussing the feasibility of local models is: Why bother? In short, local models change everything for generative AI developers, and applications that rely on cloud models risk becoming obsolete.
The first reason is that, due to the cost of GPUs, generative AI has broken the near-zero marginal cost model that SaaS has enjoyed. Today, anything bundling generative AI commands a high seat price simply to make the product economically viable. This detachment from underlying value is consequential for many products that can’t price optimally to maximize revenue. In practice, some products are constrained by a pricing floor (e.g., it is impossible to discount 50% to 10x the volume), and some features can’t be launched because the upsell doesn’t pay for the inference cost (e.g., AI characters in video games). With local models, the price is gone as a concern: they are entirely free.
The second reason is that the user experience with remote models could be better: generative AI enables useful new features, but they often come at the expense of a worse experience. Applications that didn’t depend on an internet connection (e.g., photo editors) now require it. Remote inference introduces additional friction, such as latency. Local models remove the dependency on an internet connection.
The third reason has to do with how models handle user data. This plays out in two dimensions. First, serious concerns have been raised about sharing growing amounts of private information with AI systems. Second, most generative AI adopters have been forced to use generic (aka foundation) models because scaling the distribution of personalized models was too challenging. Local models guarantee data privacy and open up the door to as many model variants as there are devices.
Do We Need 1T Parameters?
The idea that generative AI models will run locally might sound surprising. Having grown in size over the years, some models, like SOTA (state-of-the-art) LLMs, have reached 1T+ parameters. These (and possibly larger models under development) will not run on smartphones soon.
However, most generative applications only require models that can already run on consumer hardware. This is the case wherever the bleeding-edge models are already small enough to fit in the device’s memory, such as for non-LLM applications such as transcription (e.g., Whisper at ~1.5B) and image generation (e.g., Flux at ~12B). It is less evident for LLMs, as some can run on an iPhone (e.g., Llama-3.1-8B), but their performance is significantly worse than the SOTA.
That’s not the end of the story. While small LLMs know less about the world (i.e., they hallucinate more) and are less reliable at following prompt instructions, they can pass the Turing test (i.e., speak without hiccups). This has been a recent development — in fact, in our opinion, it’s the main advancement seen in the last year, in stark contrast with the lackluster progress in SOTA LLMs. It results from leveraging larger datasets of better quality in training and applying techniques such as quantization, pruning, and knowledge distillation to reduce model size further.
The knowledge and skills gap can now be bridged by fine-tuning — teaching the model how to handle a specific task, which is more challenging than prompting a SOTA LLM. A known method is to use a large LLM as the coach. In a nutshell, if a SOTA LLM is competent at the task, it can be used to produce many successful completion examples, and the small LLM can learn from those. Until recently, this method was not usable in practice because the terms of use for proprietary SOTA models like OpenAI’s GPT-4 explicitly forbade it. The introduction of open-source SOTA models like Llama-3.1-405B without such restrictions solves this.
Finally, a potential concern would be that the replacement for the one-stop-shop 1T-parameter model would be a hundred task-specific 10B-parameter models. The reality is that the task-specific models are all essentially identical. Hence, a method called LoRA enables “adapters,” which can be less than 1% the size of the foundation model they modify. It’s a win in many dimensions. Among other things, it simplifies fine-tuning (lighter hardware requirements), model distribution to end-users (small size of adapters), and context switching between applications (fast swapping due to size).
The Catalysts Are Here
Small models that can deliver best-in-class capabilities in all contexts (audio, image, and language) arrive at the same time as the necessary ecosystem to run them.
On the hardware side, Apple led the way with its ARM processors. The architecture was prescient, making macOS and iOS devices capable of running generative AI models before they became fashionable. They bundle a GPU capable of computing and pack high-bandwidth memory, which is often the limiting factor in inference speed.
Apple is not alone, and the shift is coming to the entire hardware lineup. Not to be left behind, laptops with Microsoft’s Copilot+ seal of approval can also run generative models. These machines rely on new chips like Qualcomm’s Snapdragon X Elite, showing that hardware is now being designed to be capable of local inference.
On the software side, while PyTorch has remained king in the cloud, a new series of libraries are well-positioned to leverage consumer-grade hardware better. These include Apple’s MLX and GGML. Native applications, like on-device ChatGPT alternatives, are already using these tools as a backend, and the release of WASM bindings enables any website loaded from a browser to do the same.
There are some wrinkles left to iron out, particularly concerning what developers can expect to find on a given device. Small foundation models are still a few GB large, so they’re not a practical standalone dependency for almost any application, web or native. With the release of Apple Intelligence, however, we expect macOS and iOS to bundle and expose an LLM within the operating system. This will enable developers to ship LoRA adapters in the 10s of MBs, and other operating systems will follow.
While a potential problem for developers could be the inconsistency between the models bundled by each device, convergence is likely to occur. We can’t say for sure how that will happen, but Apple’s decision with DCLM was to open-source both the model weights and the training dataset, which encourages and enables others to train models that behave similarly.
Implications for App Developers
The shift to on-device processing has significant implications for application developers.
First, start with the assumption that LLM inference is free, which removes the cost floor on any generative AI functionality. What new things can you build, and how does this affect your existing products? We predict three scenarios:
- Where generative AI is a feature of a much larger product, it will blend in more seamlessly with existing SaaS tiers, putting it at the same level as other premium features driving upgrades.
- Where generative AI is the core value proposition, and the product is priced at “cost plus” (i.e., the cost determines the price point), the products will get cheaper, but this will be more than offset by much larger volumes.
- Where generative AI is the core value proposition, and the product was priced on value to the user (i.e., well above cost), the impact will be limited to margin improvements.
Second, realize that there is a shift in how applications are developed, especially those that depend on LLMs: “prompt engineering” and “few-shot training” are out, fine-tuning is now front and center. This means that organizations building generative AI applications will require different capabilities. A benefit of SOTA LLMs was that software engineers were detached from the model, which was seen as an API that worked like any other microservice. This eliminated the dependency on internal teams of ML engineers and data scientists, which were resources many organizations didn’t have or certainly didn’t have at the scale needed to introduce generative AI across the board. On the other hand, those profiles are required for many of the workflows that local models demand. While software engineers without ML backgrounds have indeed leveled up their ML skills with the increased focus on AI, this is a higher step up to take. In the short term, the products are more challenging to build because they require differentiated models instead of relying on SOTA foundation LLMs. In the long run, however, the differentiated small models make the resulting product more valuable.
These are positive evolutions, but only those who pay the most attention to the disruptive dynamic will be ahead and reap the benefits.
Opportunities for Infrastructure Innovation
Finally, a shift to local models requires a revised tech stack. Some categories that already existed in the context of cloud-hosted models become even more necessary and might need to expand their offering:
- Foundation models: Foundation model companies started with a single goal: creating the best SOTA models. Although many have shifted partially or entirely to building models with the best cost-to-performance ratio, targeting consumer-grade hardware has not been top of mind. As local models become the primary means of consumption, priorities will shift, but now there is a lot of whitespace to cover.
- Observability and guardrails: As developers have shipped AI applications into production, the media has spotlighted their erratic behavior (e.g., hallucinations, toxicity). This has led to a need for tools that provide observability and, in some cases, hard constraints around model behavior. With a proliferation of distributed instances of the models, these challenges are aggravated, and the importance of such tools grows.
- Synthetic data and fine-tuning: While fine-tuning has been an afterthought for many application developers in the era of SOTA models, it will be front and center when dealing with fewer parameters. We argued that open-source SOTA models make it possible to synthesize fine-tuning datasets, and anyone can set up their own fine-tuning pipelines. Nevertheless, we know the people required to do these things are scarce, so we believe synthetic data and on-demand fine-tuning are areas where demand will grow significantly.
At the same time, the requirements of local models lead us to believe that several new categories will arise:
- Model CI/CD: One thing we don’t have a good sense for yet is how developers will deliver models (or model adapters) to applications. For example, will models be shipped with native application binaries, or will they be downloaded from some repository when the application loads? This brings up other questions, like how frequently models will be updated and how model versions are handled. We believe that solutions will emerge that solve these problems.
- Adapter marketplaces: While a single SOTA LLM can serve all applications, we established that making small models work across tasks requires different adapters. Many applications will undoubtedly rely on independently developed adapters, but certain adapters can also have a purpose in many applications, e.g., summarization and rephrasing. Only some developers will want to manage such standard adapters’ development and delivery lifecycle independently.
- Federated execution: While not an entirely new category, running models on consumer hardware is a new paradigm for those thinking about federated ML, that is, distributed training and inference. The focus here is less on massive fleets of devices connected over the internet and more on small clusters of devices in a local network, e.g., in the same office or home. We’re already seeing innovation here that enables more compute-intensive workloads like training or inference on medium-sized models by distributing the job across two or three devices.
Looking Forward
There’s a future where AI leaves the cloud and lands on user devices. Understanding that the ingredients to make this a possibility are already in place, it will lead to better products at a lower cost. In this new paradigm, organizations will need to update go-to-market strategies, organizational skills, and developer toolkits. While that evolution will have meaningful consequences, we don’t believe it to be the end of the story.
Today, AI remains highly centralized up and down the supply chain. SOTA GPUs are designed by only one company, which depends on a single foundry for manufacturing. Hyperscalers hosting that hardware can be counted on one hand, as can the LLM providers that developers settle for when looking for SOTA models. The innovation potential is much greater in a world where models run on commodity consumer hardware. That is something to be excited about.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.