
包阅导读总结
1. 关键词:BGE-M3、稀疏嵌入、密集嵌入、BERT、自然语言处理
2. 总结:
本文介绍了 BGE-M3 模型用于生成学习型稀疏嵌入,对比了稀疏嵌入和密集嵌入的特点,阐述了 BERT 的工作原理及预训练任务,还展示了 BGE-M3 的工作过程和在现实中的应用,强调其在多领域的价值和优势。
3. 主要内容:
– 稀疏嵌入和密集嵌入
– 稀疏嵌入适用于关键词匹配,高维且含零值,用非零值表示相关性。
– 密集嵌入低维无零值,适用于语义搜索。
– BGE-M3 模型
– 基于 BERT,结合稀疏和密集嵌入优点,生成学习型稀疏嵌入。
– 工作过程包括评估每个令牌重要性、线性变换、应用激活函数等。
– BERT 模型
– 采用双向编码,通过 MLM 和 NSP 任务预训练。
– 编码器各层独立分析生成丰富数据集。
– BGE-M3 应用
– 客户支持自动化,如聊天机器人和虚拟助手。
– 营销和媒体的内容生成与管理。
– 医疗数据分析,如临床文档和分析。
– 结论
– BGE-M3 具通用性和先进自然语言处理能力,多行业适用,能提升效率和服务质量。
思维导图: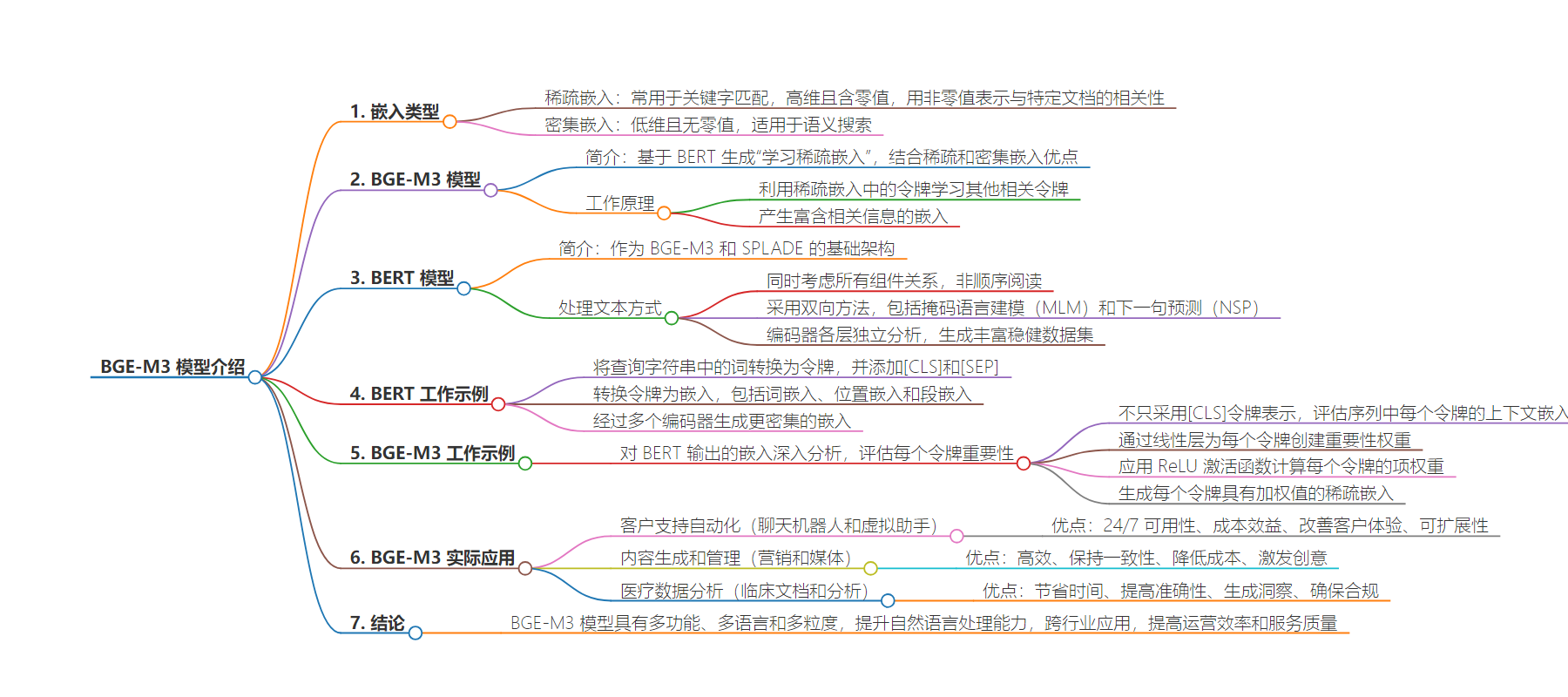
文章地址:https://thenewstack.io/generate-learned-sparse-embeddings-with-bge-m3/
文章来源:thenewstack.io
作者:Stephen Batifol
发布时间:2024/6/20 19:02
语言:英文
总字数:1362字
预计阅读时间:6分钟
评分:81分
标签:BGE-M3,稀疏嵌入,稠密嵌入,BERT,自然语言处理
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Sometimes developers need to make a choice when it comes to LLM retrieval approaches. They can use a traditional sparse embedding or a dense embedding. Sparse embeddings work really well for keyword-matching processes. We typically find sparse embeddings in natural language processing (NLP), and these high-dimensional embeddings often contain zero values. The dimensions in these embeddings represent tokens across one (or multiple) language(s). It uses non-zero values to show how relevant each token is to a specific document.
Dense embeddings, on the other hand, are lower-dimensional but they don’t contain any zero values. As the name suggests, dense embeddings are jam-packed with information. This makes dense embeddings ideal for semantic search tasks, making it easier to match the “spirit” of meaning instead of the exact string.
BGE-M3 is a machine learning model used to create an advanced type of embedding called a “learned sparse embedding.” The nice thing about these learned embeddings is that they combine the best of both worlds: the precision of sparse embedding and the semantic richness of dense embeddings. This model uses the tokens in a sparse embedding to learn which other tokens may be relevant or related, even if they’re not explicitly used in the original search string. Ultimately, this yields an embedding that is rich with relevant information.
Meet BERT
Bidirectional Encoder Representations from Transformers (or BERT) is more than meets the eye. It is the underlying architecture that enables advanced machine learning models like BGE-M3 and SPLADE.
BERT approaches text differently than traditional models. Instead of just reading a text string sequentially, it examines everything all at once, taking the relationship between all the components into account. BERT does this with a two-pronged approach. These are separate pre-training tasks that the model implements, but their outputs work together to enrich the meaning of inputs.
- Masked Language Modeling (MLM): First, BERT randomly hides part of the input token. Then it uses the model to figure out which options make sense for the hidden portions. To do this, it needs to understand the relationship not only between word order but how that order affects meaning.
- Next Sentence Prediction (NSP): While the MLM works primarily at the sentence level, NSP zooms out further. This task ensures that sentences and paragraphs flow logically, so it learns to predict what makes sense in these broader contexts.
When the BERT model analyzes a query, each layer of the encoder conducts its analysis independently of the other layers. This allows each layer to generate unique results, free from the influence of the other encoders. The output of this is a richer, more robust data set.
It’s important to understand BERT functions because BGE-M3 is based on BERT. The following example demonstrates how BERT works.
BERT in Action
Let’s take a basic query and see how BERT creates an embedding from it:
Milvus is a vector database built for scalable similarity search.
The first step is to convert the words in the query string to tokens.

You’ll notice that the model added [CLS] to the beginning and [SEP] to the end of the token. These components simply indicate the beginning and end of a sentence, respectively, at the sentence level.
Next, it needs to convert the tokens into an embedding.
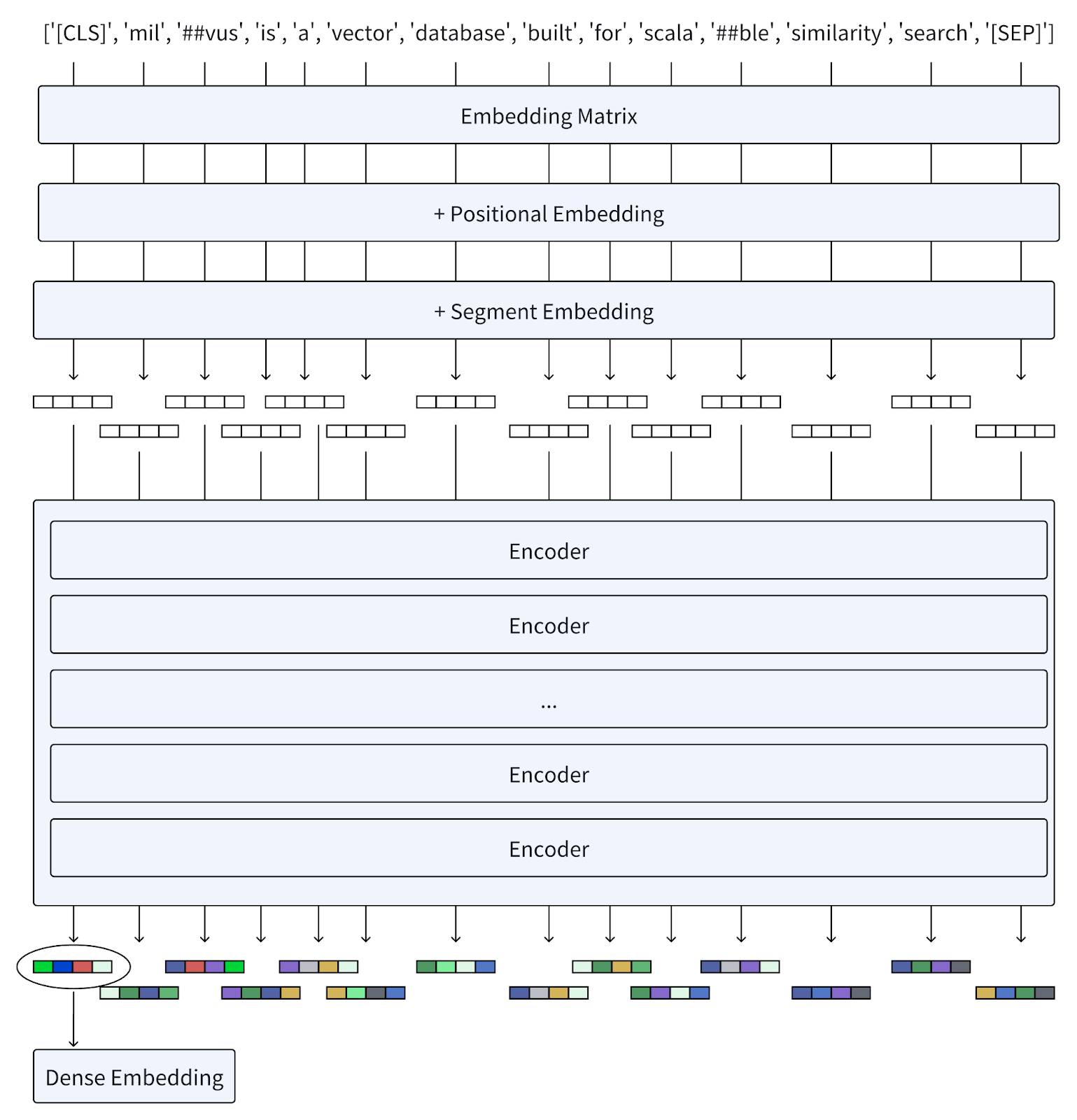
The first part of this process is the embedding. Here, an embedding matrix converts each token into a vector. Next, BERT adds positional embeddings because the order of the words matters and this embedding keeps those relative positions intact. Finally, the segment embedding simply tracks the breaks between sentences.
We can see the embedding output at this point is monochromatic to represent sparse embeddings. To achieve greater density, these embeddings go through multiple encoders. Like the pre-training tasks identified above that work independently of each other, these encoders do the same. The embeddings undergo continual revision as they work through the encoders. The tokens in the sequence provide a critical context for refining the representation generated by each encoder.
Once this process finishes, the final output is a denser embedding than the pre-encoder output. This is especially true when using individual tokens for further processing or tasks that result in a singular, dense representation.
BGE-M3 Enters the Chat
BERT got us dense embeddings, but the goal here is to generate learned sparse embeddings. So now we finally get to the BGE-M3 model.
BGE-M3 is basically an advanced machine learning model that takes BERT further by focusing on enhancing text representation through multifunctionality, multi-linguisticity and multi-granularity. All this is to say that it does more than create dense embeddings by generating learned sparse embeddings that provide the best of both worlds: word meaning and precise word choices.
BGE-M3 in Action
Let’s start with the same query we used to understand BERT. Running the query generates the same sequence of contextualized embeddings that we saw above. We can call this output ( Q ).

The BGE-M3 model goes deeper into these embeddings and attempts to understand the significance of each token on a more granular level. There are several aspects of this.
- Token importance estimation: BGE-M3 doesn’t take the [CLS] token representation
Q[0]as the only possible representation. It also evaluates the contextualized embedding of each tokenQ[i]within the sequence. - Linear transformation: The model also takes the BERT output and, using a linear layer, creates an importance weighting for each token. We can call the set of weights that BGE-M3 produces
W_{lex}. - Activation function: BGE-M3 then applies a rectified linear unit (ReLU) activation function to the product of
W_{lex}andQ[i]to compute the term weightw_{t}for each token. Using ReLU ensures that the term weight is non-negative, contributing to the sparsity of the embedding. - Learned sparse embedding: The final output result is a sparse embedding where every token has a weighted value that indicates how important it is to the original input string.
BGE-M3 in the Real World
Applying the BGE-M3 model to real-world use cases can help demonstrate the value of this machine learning model. These are areas where organizations stand to benefit from the model’s ability to understand linguistic nuances across large quantities of textual data.
Customer Support Automation — Chatbots and Virtual Assistants
You can use BGE-M3 to power chatbots and virtual assistants, significantly enhancing customer support services. These chatbots can handle a wide range of customer queries, providing instant responses and understanding complex questions and contextual information. They can also learn from interactions to improve over time.
Benefits:
- 24/7 availability: Provides round-the-clock support to customers.
- Cost efficiency: Reduces the need for a large customer support team.
- Improved customer experience: Quick and accurate responses improve customer satisfaction.
- Scalability: Can handle numerous queries simultaneously, ensuring consistent service during peak times.
Content Generation and Management for Marketing and Media
You can leverage BGE-M3 to generate high-quality content for blogs, social media, advertisements and more. It can create articles, social media posts and even full-length reports based on desired tone, style and context. You can also use this model to summarize long documents, create abstracts and generate product descriptions.
Benefits:
- Efficiency: Produces large volumes of content quickly.
- Consistency: Maintains a consistent tone and style across different pieces of content.
- Cost reduction: Lowers the need for large content creation teams.
- Creativity: Helps brainstorm and generate creative content ideas.
Medical Data Analysis — Clinical Documentation and Analysis
Developers in the healthcare sector can use BGE-M3 to analyze clinical documents and patient records, extract relevant information and assist in generating comprehensive medical reports. It can also aid in identifying trends and insights from vast amounts of medical data, supporting better patient care and research.
Benefits:
- Time savings: Reduces the time healthcare professionals spend on documentation.
- Accuracy: Enhances the accuracy of medical records and reports.
- Insight generation: Identifies patterns and trends that can inform better clinical decisions.
- Compliance: Helps ensure documentation complies with regulatory standards.
Conclusion
The BGE-M3 model provides a significant degree of versatility and advanced natural language processing capabilities that have applications across industries and sectors and can provide significant improvements in operational efficiency and service quality.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.