
包阅导读总结
1. 关键词:Mysql、Innodb、日志、缓冲区、性能
2. 总结:
本文以 Innodb 存储引擎为主,介绍了 Mysql 中的各种日志和缓冲区,包括写入数据流程,如 undo log 用于回滚和 MVCC,buffer pool 及 LRU 算法,change buffer,redo log 及刷盘策略,binlog 及其数据格式。这些机制共同保障 Mysql 的性能、数据一致性和功能实现。
3. 主要内容:
– Mysql 中的日志和缓冲区
– 写入数据流程
– 写入 undo log 用于回滚
– 写入 buffer pool 或 change buffer
– 记录 redo log 并刷盘
– 写入 binlog 并二阶段提交
– 刷盘策略
– undo log
– 用于数据回滚
– 实现 MVCC
– buffer pool
– Innodb 缓存区
– 采用变种 LRU 算法
– Flush 链表管理脏页
– change buffer
– 缓存未在内存中的更新操作
– 占用 buffer pool 内存
– redo log 与 redo log buffer
– 防止数据丢失
– 环形文件,顺序写入
– 三种刷盘策略
– binlog
– 二进制格式,实现多种功能
– 三种数据格式
– 总结
– 各区域保障性能、数据一致性和功能
思维导图: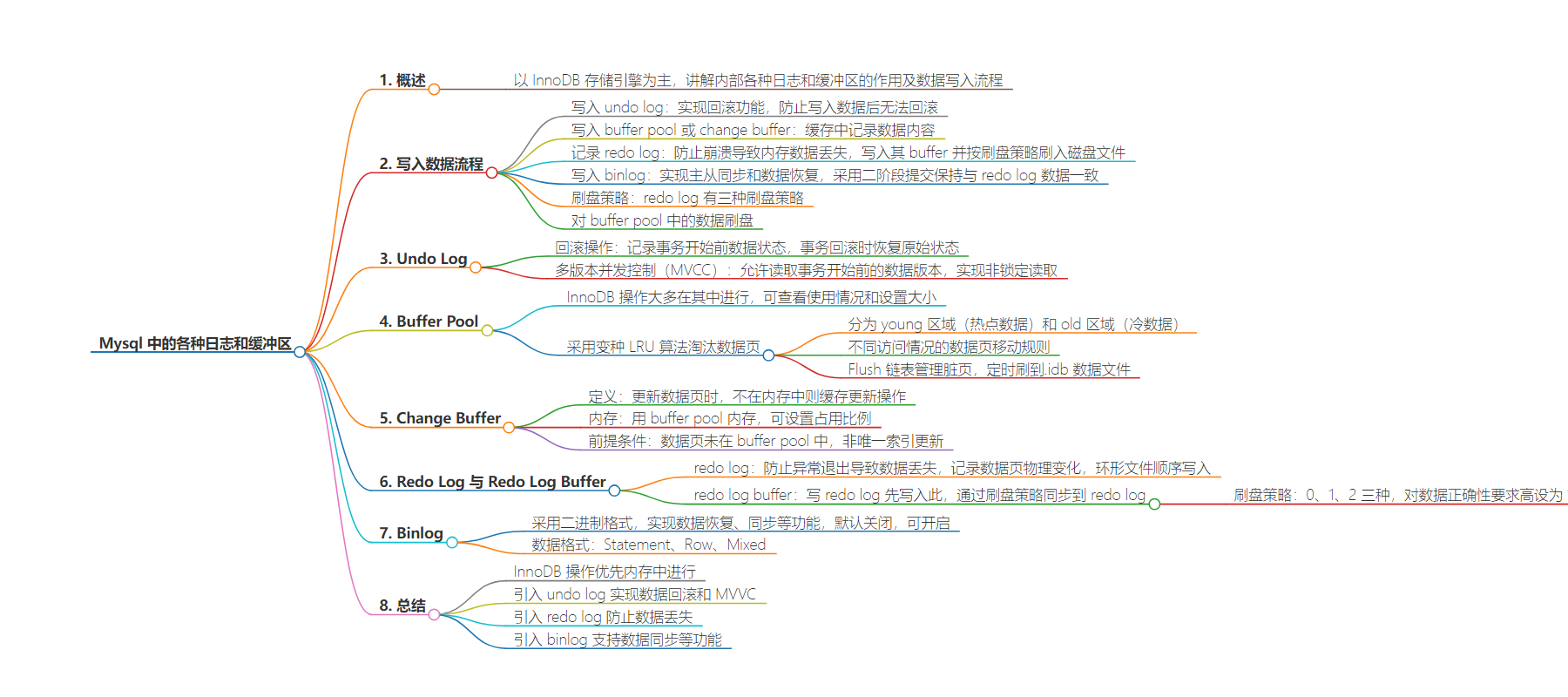
文章地址:https://juejin.cn/post/7411489477283856419
文章来源:juejin.cn
作者:想打游戏的程序猿
发布时间:2024/9/8 4:05
语言:中文
总字数:3012字
预计阅读时间:13分钟
评分:87分
标签:MySQL,InnoDB,数据库日志,缓冲区管理,数据一致性
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
介绍
本篇文章主要以innodb存储引擎为主;在了解mysql的过程中经常能听到它内部有各种log以及缓冲区,他们在mysql中具有重要作用,例如binlog可以进行主从恢复,undo log可以进行数据回滚等。这篇文章主要讲解在mysql运气期间每个区域都是用来做什么的。
写入数据流程
对于mysql来讲,读写任何数据都是在内存中进行操作的;下图为mysql写入数据的详细流程:
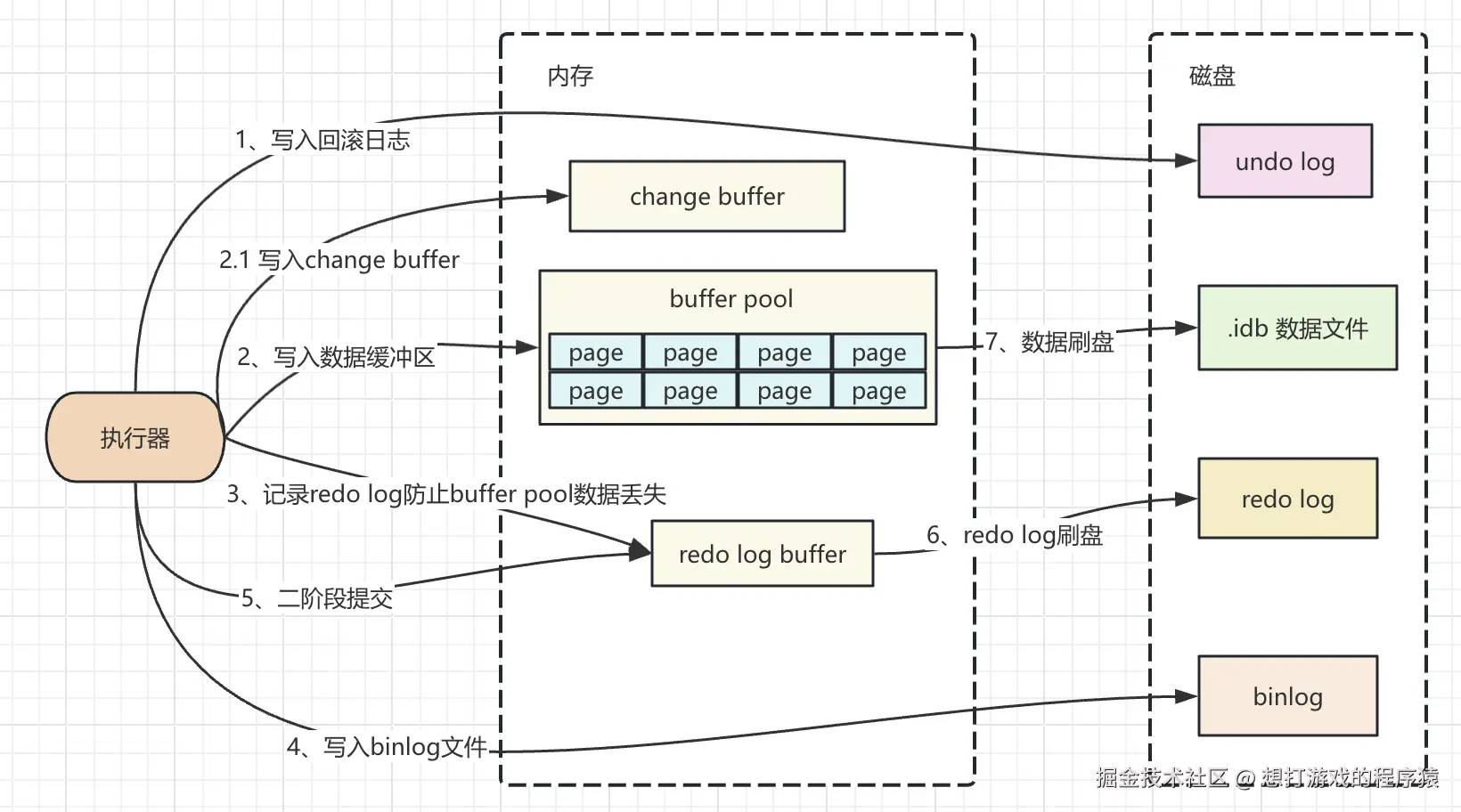
- 写入undo log,为了实现回滚的功能,在写入真实数据前需要记录它的回滚日志,防止写入完数据后无法进行回滚;
- 写入
buffer pool或change buffer,在缓存中记录下数据内容; - 为了防止mysql崩溃内存中的数据丢失,此时会记录下redo log,记录redo log时也是写入它的buffer,通过不同的刷盘策略刷入到磁盘redo log文件中;
- 为了实现主从同步,数据恢复功能,mysql提供了binlog日志,写入完redo log后写binlog文件;
- 为了使binlog和redo log保持数据一致,这里采用的二阶段提交,写入binlog成功会再在redo log buffer中写入commit;
- 对redo log进行刷盘,这里有三种刷盘策略,介绍一下刷盘策略;
- 对buffer pool中的数据进行刷盘。
undo log
undo log记录事务开始前的数据状态,它主要用于数据回滚和实现MVCC:
- 回滚操作:undo log记录了事务开始前的数据状态,当事务需要回滚时,以便可以恢复到原始状态。
- 多版本并发控制(MVCC) :在读取历史数据时,undo log允许读取到事务开始前的数据版本,从而实现非锁定读取。
MVCC的具体实现可以查看:MVCC实现
buffer pool
innodb中无论是查询还是写绝大部分都是在buffer pool中进行操作的,它相当于innodb的缓存区,可以通过show engine innodb status来查看buffer pool的使用情况;可以通过innodb_buffer_pool_size来设置buffer pool的大小,线上不要吝啬给几个G内存都是正常的,但无论给多大内存都会有不够的时候,innodb采用了变种的LRU算法对数据页进行淘汰;如下图:
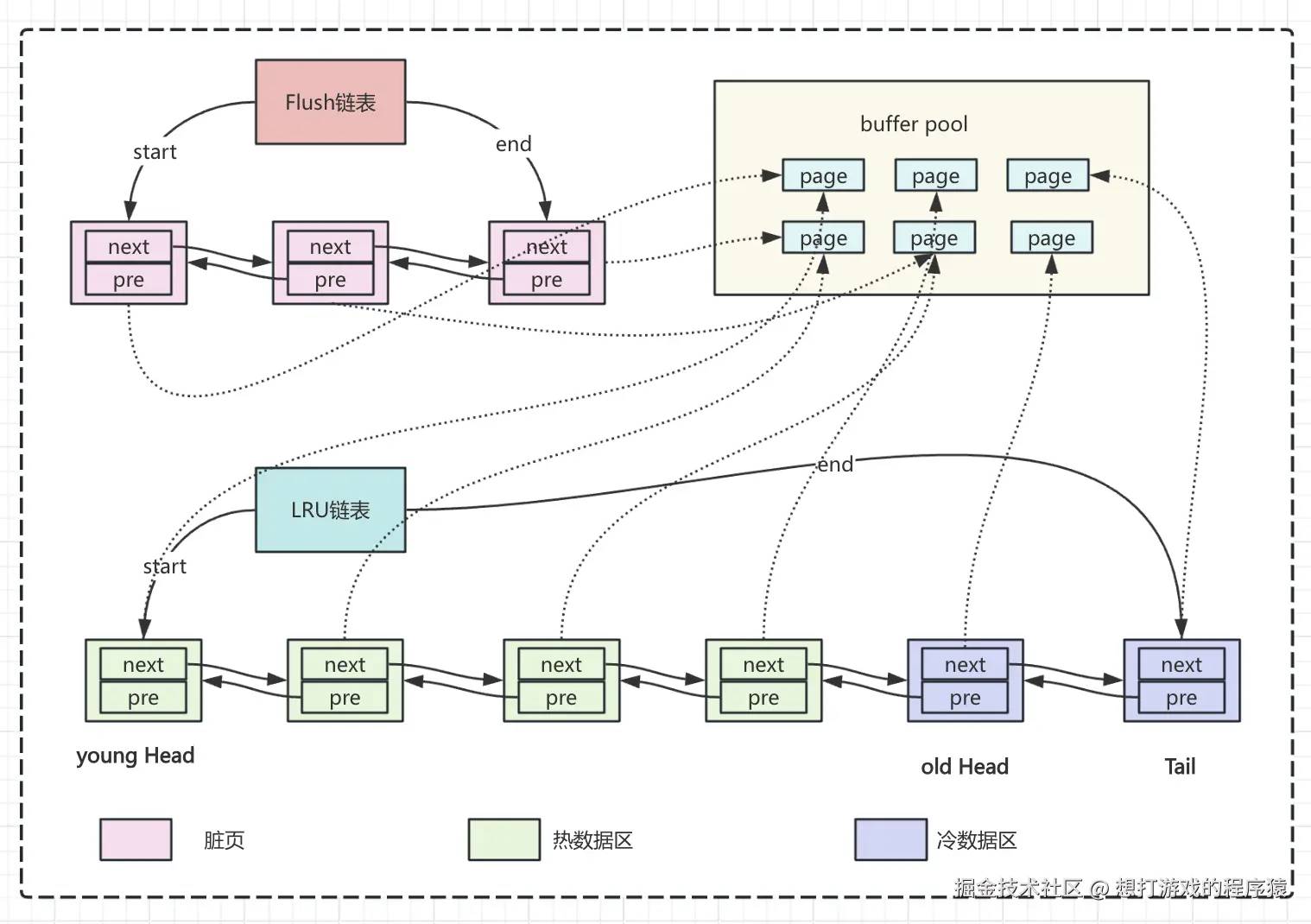 传统的LRU算法当碰到扫描一张大表时可能会直接把buffer pool中的所有页都更换为该表的数据,但这张表可能就使用一次,并不是热点数据;
传统的LRU算法当碰到扫描一张大表时可能会直接把buffer pool中的所有页都更换为该表的数据,但这张表可能就使用一次,并不是热点数据;
innodb为了避免这种场景发生,会把整个buffer pool按照 5:3分成了young区域和old区域;其中绿色区域就是young区域也就是热点数据区域,紫色区域就是old区域也就是冷数据区域;整体的淘汰流程为:
- 如果想访问绿色区域内的数据,会把访问页直接放在young head处;
- 如果想访问一个不存在的页,会把tail页淘汰掉,并且把新访问的数据页插入在old head处;
- 如果访问old区域的数据页,并且这个数据页在LRU链表中存在的时间超过了
innodb_old_blocks_time(默认1000毫秒),就把它移动到yound head处; - 如果访问old区域的数据页,并且这个数据页在LRU链表中存在的时间短于
innodb_old_blocks_time,把该页移动到old head处。
在上图中可以看到除了LRU链表还有一个Flush链表,它是用来管理脏页的;在写入数据时绝大部分都会先写入buffer pool中,再更改buffer pool中的页数据时,该页就变成了脏页,此时就会被加入到flush链表中,定时会把flush中的脏页刷到.idb数据文件中。
change buffer
在介绍buffer pool时用的是绝大部分操作,是因为在innodb中还存在change buffer,还有一部分操作是写入change buffer的。change buffer的定义是当需要更新一个数据页时,如果数据页在内存中就直接更新,而如果这个数据页还没有在内存中的话,在不影响数据一致性的前提下,innodb会将这些更新操作缓存在change buffer中,这样就不需要从磁盘中加载这个数据页了,如果有查询需要访问这个数据页的时候,再将数据页读到内存中,然后执行change buffer中与这个页有关的操作,这样就能保证这个数据的正确性。change buffer用的是buffer pool中的内存,可以通过innodb_change_buffer_max_size来设置它占用buffer pool的内存比例。使用change buffer的前提条件是该数据页还没被加载到buffer pool中,并且如果是根据唯一索引进行更新,由于要检查数据的唯一性,必须把数据页加载到buffer pool中是无法享受change buffer带来的收益的。
redo log 与 redo log buffer
redo log是为了防止由于mysql异常退出导致buffer pool中还未持久化的数据丢失而诞生的;它也是一个环形文件写数据写满时会覆盖历史的数据,它记录了数据页的物理变化,并且是顺序写入的提升了写入的性能;当mysql重启时可以使用redo log来恢复数据。
每次写redo log时并不是直接写入redo log文件,而是写入redo log buffer中,通过三种刷盘策略把数据同步到redo log中,可以通过innodb_flush_log_at_trx_commit参数来控制刷盘的时机
- 0:事务提交时,日志缓冲(log buffer)被写入到日志文件,但并不立即刷新到磁盘。日志文件的刷新操作由后台线程每隔一秒执行一次;
- 1:事务提交时,日志缓冲被写入到日志文件,并立即刷新到磁盘;
- 2:事务提交时,日志缓冲被写入到日志文件,但不立即刷新到磁盘。而是每秒由后台线程将日志文件刷新到磁盘。
如果对数据的正确性要求很高应该设置为1。
注:第一张图流程中,在第5步有二次commit,在数据恢复如果发现一个事务没有commit,则去binlog日志中查询,如果发现binlog中有相应数据则直接恢复,如果没有则丢弃。
binlog
binlog为了高效地记录和传输数据更改信息,它采用了二进制格式存储数据库的更改操作,这样还可以占用更小的存储空间;它可以实现数据恢复、数据同步等功能。默认mysql是关闭binlog日志的,可以通过在[mysqlId]部分中设置log-bin和server-id来开启binlog日志。它也是在事务提交时才进行数据记录,它有以下三种数据格式:
- Statement:记录每一条执行的sql,但由于mysql中存在一些函数,例如一些随机生成函数,此时数据同步时会发生同步过去的数据不一致;
- Row:记录每行被修改成什么,这样可以解决statement带来的数据不一致问题,但由于记录的太详细如果出现了全表更新,那记录的数据量就会特别大;
- Mixed:Statement和Row的混合体,mysql会根据执行的每一条具体的SQL语句来区别对待记录的日志格式。
总结
为了实现更高的性能,在innodb中的任何操作都是优先在内存中操作的;为了支持数据的数据回滚、MVVC引入了undo log,进而可以实现查询历史版本或数据回滚;同时为了防止异常退出导致的数据丢失引入了redo log;为了支持数据同步等功能mysql引入了binlog日志。这就是各个区域的作用,由于篇幅原因本篇文章只对每个区域做了简单介绍,后续会写各个区域详细内容的文章。
创作不易,觉得文章写得不错帮忙点个赞吧!如转载请标明出处~