
包阅导读总结
1. `pg_graphql`、`pagination`、`multi-tenancy`、`filtering`、`upcoming features`
2.
“`markdown
关键词:`pg_graphql`、`pagination`、`multi-tenancy`、`filtering`、`upcoming features`
总结:本文介绍了 pg_graphql 1.5.7 的新特性,包括 First/Offset 分页、基于模式的多租户支持、数组类型列的过滤,还提到早期支持的 keyset 分页,以及未来版本将支持的 Insert on conflict / Upsert 和嵌套插入等特性。
“`
3.
– `pg_graphql 1.5.7`
– 新特性
– `pagination`
– `First/Offset`:1.5.0 开始支持基于偏移的分页,早期支持 keyset 分页,后者性能更佳。
– `multi-tenancy`:1.5.2 后每个租户仅加载有权使用的模式,减轻数据库负担。
– `filtering`:1.5.6 为标量数组字段添加 `contains`、`containedBy`、`overlaps` 过滤操作符。
– 未来计划
– 支持 `Insert on conflict / Upsert` 和嵌套插入。
思维导图: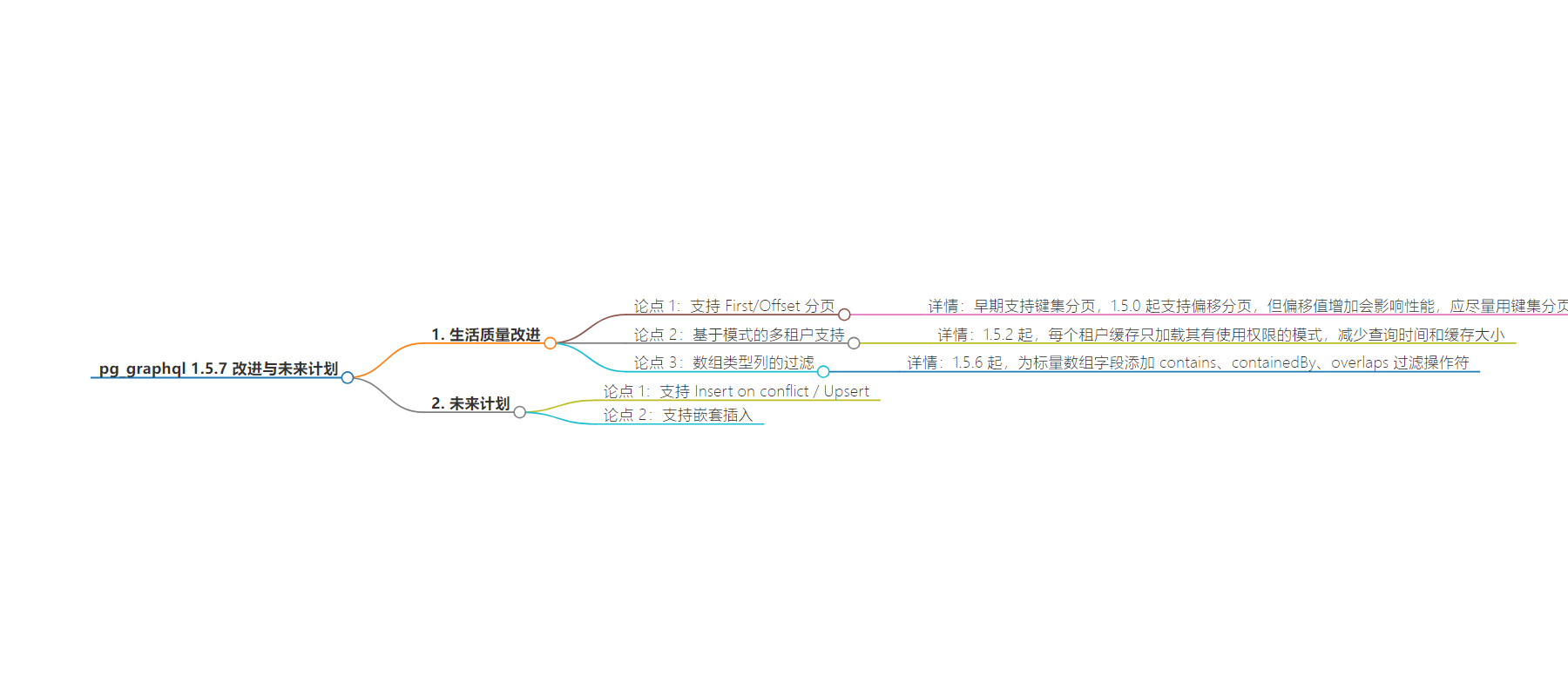
文章地址:https://supabase.com/blog/pg-graphql-1-5-7
文章来源:supabase.com
作者:Supabase Blog
发布时间:2024/8/15 0:00
语言:英文
总字数:506字
预计阅读时间:3分钟
评分:86分
标签:pg_graphql,GraphQL,PostgreSQL,分页,多租户
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Since our last check-in on pg_graphql there have been a few quality of life improvements worth calling out. A quick roundup of the key differences includes:
- Pagination via First/Offset
- Schema based multi-tenancy
- Filtering on array typed columns with
contains,containedByandoverlaps
Since the earliest days of pg_graphql, keyset pagination has been supported. Keyset pagination allows for paging forwards and backwards through a collection by specifying a number of records and the unique id of a record within the collection. For example:
_10
after: "Y3Vyc29yMQ=="
to retrieve the first 2 records after the record with unique id Y3Vyc29yMQ== .
Starting in version 1.5.0 there is support for offset based pagination, which is based on skipping offset number of records before returning the results.
That is roughly equivalent to the SQL
In general as offset values increase, the performance of the query will decrease. For that reason its important to use keyset pagination where possible.
pg_graphql caches the database schema on first query and rebuilds that cache any time the schema changes. The cache key is a combination of the postgres role and the database schema’s version number. Initially, the structure of all schemas was loaded for all roles, and table/column visibility was filtered down within pg_graphql.
In multi-tenant environments with 1 schema per tenant, that meant every time a tenant updated their schema, all tenants had to rebuild the cache. When the number of tenants gets large, that burdens the database if its under heavy load.
Following version 1.5.2 each tenant’s cache only loads the schemas that they have usage permission for, which greatly reduces the query time in multi-tenant environments and the size of the schema cache. At time of writing this solution powers a project with >2200 tenants.
From 1.5.6 pg_graphql has added contains, containedBy, overlaps filter operators for scalar array fields like text[] or int[].
For example, given a table
_10
tags text[] not null,
_10
created_at timestamp not null
the tags column with type text[] can be filtered on.
_12
blogCollection(filter: { tags: { contains: ["tech", "innovation"] } }) {
In this case, the result set is filtered to records where the tags column contains both tech and innovation.
The headline features we aim to launch in coming releases of pg_graphql include support for:
- Insert on conflict / Upsert
- Nested inserts
If you want to get started with GraphQL today, check out the Docs or the source code.