
包阅导读总结
1. `vec2pg`、`迁移`、`Postgres`、`pgvector`、`向量数据库`
2. `vec2pg`是一个用于将数据从向量数据库迁移到`Supabase`或任何带有`pgvector`的`Postgres`实例的`CLI`工具。迁移速度受多种因素影响,目前支持从`Pinecone`和`Qdrant`迁移。`Postgres`有诸多优势,可前往`vec2pg`的`GitHub`页面获取或通过`pip`安装,未支持的数据库厂商可反馈。
3.
– `vec2pg`工具
– 用于向量数据库数据迁移到`Supabase`或`Postgres`
– 目标是方便高效复制数据及相关`id`和元数据
– 迁移特点
– 数据加载到新架构,表名与源匹配
– 输出表使用`pgvector`的向量类型和内置`json`类型
– 可通过`SQL`操纵数据转换架构
– 迁移时要增加`Supabase`项目磁盘大小
– 支持的源
– 已支持从`Pinecone`和`Qdrant`迁移
– 迁移速度受多种因素影响
– `Postgres`优势
– 高性能、可扩展、安全
– 支持备份和时间点恢复
– 行级安全策略
– 工具获取
– 前往`GitHub`页面或通过`pip`安装
– 未支持的厂商可反馈
思维导图: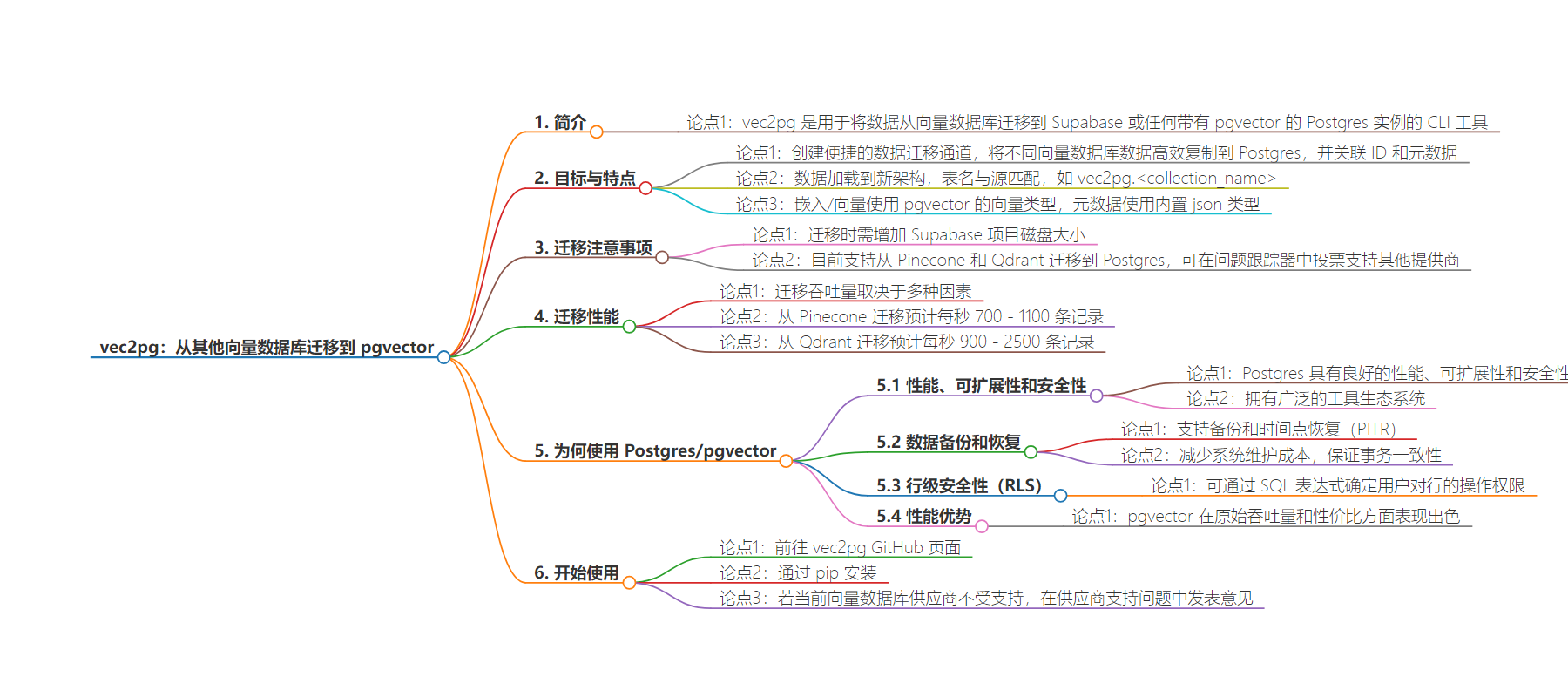
文章地址:https://supabase.com/blog/vec2pg
文章来源:supabase.com
作者:Supabase Blog
发布时间:2024/8/16 0:00
语言:英文
总字数:668字
预计阅读时间:3分钟
评分:88分
标签:向量数据库,PostgreSQL,pgvector,数据迁移,命令行工具
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
vec2pg is a CLI utility for migrating data from vector databases to Supabase, or any Postgres instance with pgvector.
Our goal with https://github.com/supabase-community/vec2pg is to create an easy on-ramp to efficiently copy your data from various vector databases into Postgres with associated ids and metadata. The data loads into a new schema with a table name that matches the source e.g. vec2pg.<collection_name> . That output table uses https://github.com/pgvector/pgvector’s vector type for the embedding/vector and the builtin json type for additional metadata.
Once loaded, the data can be manipulated using SQL to transform it into your preferred schema.
When migrating, be sure to increase your Supabase project’s disk size so there is enough space for the vectors.
At launch we support migrating to Postgres from Pinecone and Qdrant. You can vote for additional providers in the issue tracker and we’ll reference that when deciding which vendor to support next.
Throughput when migrating workloads is measured in records-per-second and is dependent on a few factors:
- the resources of the source data
- the size of your Postgres instance
- network speed
- vector dimensionality
- metadata size
When throughput is mentioned, we assume a Small Supabase Instance, a 300 Mbps network, 1024 dimensional vectors, and reasonable geographic colocation of the developer machine, the cloud hosted source DB, and the Postgres instance.
vec2pg copies entire Pinecone indexes without the need to manage namespaces. It will iterate through all namespaces in the specified index and has a column for the namespace in its Postgres output table.
Given the conditions noted above, expect 700-1100 records per second.
The qdrant subcommand supports migrating from cloud and locally hosted Qdrant instances.
Again, with the conditions mentioned above, Qdrant collections migrate at between 900 and 2500 records per second.
Why Use Postgres/pgvector?#
The main reasons to use Postgres for your vector workloads are the same reasons you use Postgres for all of your other data. Postgres is performant, scalable, and secure. Its a well understood technology with a wide ecosystem of tools that support needs from early stage startups through to large scale enterprise.
A few game changing capabilities that are old hat for Postgres that haven’t made their way to upstart vector DBs include:
Postgres has extensive supports for backups and point-in-time-recovery (PITR). If your vectors are included in your Postgres instance you get backup and restore functionality for free. Combining the data results in one fewer systems to maintain. Moreover, your relational workload and your vector workload are transactionally consistent with full referential integrity so you never get dangling records.
Row Level Security (RLS) allows you to write a SQL expression to determine which users are allowed to insert/update/select individual rows.
For example
_10
create policy "Individuals can view their own todos."
_10
( ( select auth.uid() ) = user_id );
Allows users of Supabase APIs to update their own records in the todos table.
Since vector is just another column type in Postgres, you can write policies to ensure e.g. each tenant in your application can only access their own records. That security is enforced at the database level so you can be confident each tenant only sees their own data without repeating that logic all over API endpoint code or in your client application.
pgvector has world class performance in terms of raw throughput and dominates in performance per dollar. Check out some of our prior blog posts for more information on functionality and performance:
Keep an eye out for our upcoming post directly comparing pgvector with Pinecone Serverless.
To get started, head over to the vec2pg GitHub Page, or if you’re comfortable with CLI help guides, you can install it using pip :
If your current vector database vendor isn’t supported, be sure to weigh in on the vendor support issue.