
包阅导读总结
1. 关键词:数据集成、ETL、ELT、EtLT、架构演变
2. 总结:本文探讨了数据集成架构从 ETL 到 ELT 再到 EtLT 的演变,分析了各架构的优缺点,阐述了数据集成的成熟度模型,包括数据生产、计算模型等方面的特点和趋势。
3. 主要内容:
– 数据集成架构演变
– ETL 架构
– 优势:数据一致性和质量、复杂数据源集成等
– 劣势:缺乏实时处理、硬件成本高等
– ELT 架构
– 优势:处理大数据量、提高开发和运营效率等
– 劣势:实时支持有限、数据存储成本高等
– EtLT 架构
– 优势:实时数据处理、支持复杂数据源等
– 劣势:技术复杂、依赖目标系统能力等
– 数据集成成熟度模型解读
– 数据生产
– 数据收集:支持多种收集方式,实时数据获取和 DDL 变化检测仍在发展
– 数据转换:复杂业务处理减少,SQL 类语言的轻量转换为主流
– 数据分布:主流工具具备传统加载方式,竞争在于数据源支持广度
– 数据存储:具备缓存能力,利用云存储成新方向
– 数据结构迁移:自动表创建和检查仍在实验阶段
– 计算模型
– 从强调计算到注重传输,再到实时传输的轻量计算
思维导图: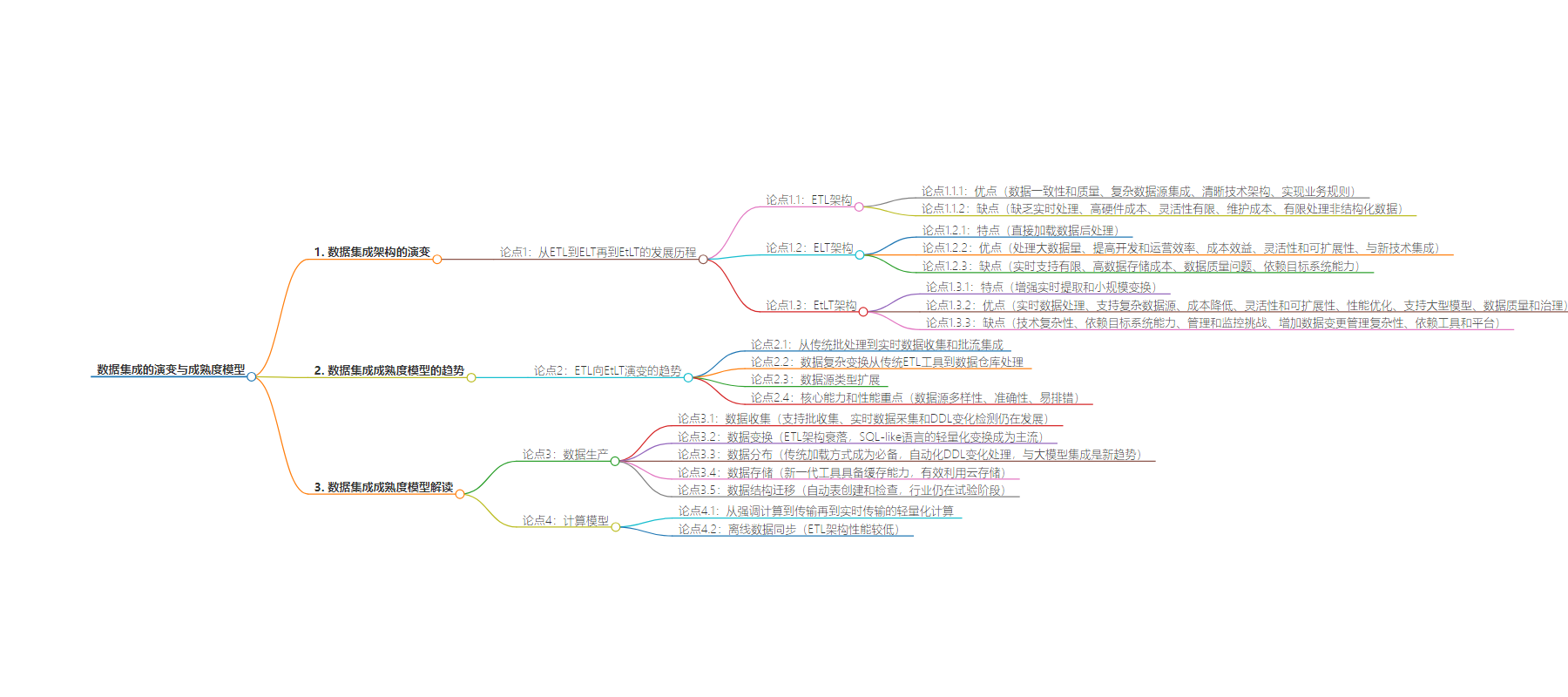
文章地址:https://thenewstack.io/how-data-integration-is-evolving-beyond-etl/
文章来源:thenewstack.io
作者:Guo Wei
发布时间:2024/6/23 21:33
语言:英文
总字数:4046字
预计阅读时间:17分钟
评分:84分
标签:数据集成,ETL,ELT,EtLT,实时数据
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
When it comes to data integration, some people may wonder what there is to discuss— isn’t it just ETL? That is, extracting from various databases, transforming, and ultimately loading into different data warehouses.
However, with the rise of big data, data lakes, real-time data warehouses, and large-scale models, the architecture of data integration has evolved from the ETL of the data warehouse era to the ELT of the big data era, and now to the current stage of EtLT. In the global tech landscape, emerging EtLT companies like FiveTran, Airbyte, and Matillion have emerged, while giants like IBM have invested $2.3 billion in acquiring StreamSets and webMethods to upgrade their product lines from ETL to webMethods (DataOps).
Whether you’re a manager in an enterprise or a professional in the data field, it’s essential to re-examine the changes in data integration in recent times and future trends.
ETL Architecture
Most experts in the data field are familiar with the term ETL. During the heyday of data warehousing, ETL tools like IBM DataStage, Informatica, Talend, and Kettle were popular. Some companies still use these tools to extract data from various databases, transform it, and load it into different data warehouses for reporting and analysis. The pros and cons of the ETL architecture are as follows:
Advantages of ETL Architecture:
- Data Consistency and Quality
- Integration of Complex Data Sources
- Clear Technical Architecture
- Implementation of Business Rules
Disadvantages of ETL Architecture:
- Lack of Real-time Processing
- High Hardware Costs
- Limited Flexibility
- Maintenance Costs
- Limited Handling of Unstructured Data
ELT Architecture
With the advent of the big data era, facing the challenges of ETL’s inability to load complex data sources and its poor real-time performance, a variant of ETL architecture, ELT, emerged. Companies started using ELT tools provided by various data warehousing vendors, such as Teradata’s BETQ/Fastload/TPT and Hadoop Hive’s Apache Sqoop. The characteristics of ELT architecture include directly loading data into data warehouses or big data platforms without complex transformations and then using SQL or H-SQL to process the data.
The pros and cons of the ELT architecture are as follows:
Advantages of ELT Architecture:
- Handling Large Data Volumes
- Improved Development and Operational Efficiency
- Cost-effectiveness
- Flexibility and Scalability
- Integration with New Technologies
Disadvantages of ELT Architecture:
- Limited Real-time Support
- High Data Storage Costs
- Data Quality Issues
- Dependence on Target System Capabilities
EtLT Architecture
The weaknesses of ELT architecture in real-time processing and handling unstructured data are highlighted with the popularity of data lakes and real-time data warehouses. Thus, a new architecture, EtLT, emerged. EtLT architecture enhances ELT by adding real-time data extraction from sources like SaaS, Binlog, and cloud components, as well as incorporating small-scale transformations before loading the data into the target storage. This trend has led to the emergence of several specialized companies worldwide, such as StreamSets, Attunity (acquired by Qlik), Fivetran, and SeaTunnel by the Apache Foundation.
The pros and cons of the EtLT architecture are as follows:
Advantages of EtLT Architecture:
- Real-time Data Processing
- Support for Complex Data Sources
- Cost Reduction
- Flexibility and Scalability
- Performance Optimization
- Support for Large Models
- Data Quality and Governance
Disadvantages of EtLT Architecture:
- Technical Complexity
- Dependence on Target System Capabilities
- Management and Monitoring Challenges
- Increased Data Change Management Complexity
- Dependency on Tools and Platforms
Overall, in recent years, with the rise of data, real-time data warehouses, and large models, the EtLT architecture has gradually become mainstream worldwide in the field of data integration. For specific historical details, you can refer to the relevant content in my article “ELT is dead, and EtLT will be the end of modern data processing architecture“.
Under this overarching trend, let’s interpret the maturity model of the entire data integration track. Overall, there are four clear trends:
- In the trend of ETL evolving into EtLT, the focus of data integration has shifted from traditional batch processing to real-time data collection and batch-stream integrated data integration. The hottest scenarios have also shifted from past single-database batch integration scenarios to hybrid cloud, SaaS, and multiple data sources integrated in a batch-stream manner.
- Data complexity transformation has gradually shifted from traditional ETL tools to processing complex transformations in data warehouses. At the same time, support for automatic schema changes (Schema Evolution) in the case of DDL (field definition) changes during real-time data integration has also begun. Even adapting to DDL changes in lightweight transformations has become a trend.
- Support for data source types has expanded from files and traditional databases to include emerging data sources, open-source big data ecosystems, unstructured data systems, cloud databases, and support for large models. These are also the most common scenarios encountered in every enterprise, and in the future, real-time data warehouses, lakes, clouds, and large models will be used in different scenarios within each enterprise.
- In terms of core capabilities and performance, diversity of data sources, high accuracy, and ease of troubleshooting are the top priorities for most enterprises. Conversely, there are not many examination points for capabilities such as high throughput and high real-time performance.
Chapter 2: Data Integration Maturity Model Interpretation
Data Production
The data production segment refers to how data is obtained, distributed, transformed, and stored within the context of data integration. This part poses the greatest workload and challenges in integrating data.
When users in the industry use data integration tools, their primary consideration is whether the tools support integration with their databases, cloud services, and SaaS systems. If these tools do not support the user’s proprietary systems, then additional costs are incurred for customizing interfaces or exporting data into compatible files, which can pose challenges to the timeliness and accuracy of data.
- Data Collection: Most data integration tools now support batch collection, rate limiting, and HTTP collection. However, real-time data acquisition (CDC) and DDL change detection are still in their growth and popularity stages. Particularly, the ability to handle DDL changes in source systems is crucial. Real-time data processing is often interrupted by changes in source system structures. Effectively addressing the technical complexity of DDL changes remains a challenge, and various industry vendors are still exploring solutions.
- Data Transformation: With the gradual decline of ETL architectures, complex business processing (e.g., Join, Group By) within integration tools has gradually faded into history. Especially in real-time scenarios, there is limited memory available for operations like stream window Join and aggregation. Therefore, most ETL tools are migrating towards ELT and EtLT architectures. Lightweight data transformation using SQL-like languages has become mainstream, allowing developers to perform data cleaning without having to learn various data integration tools. Additionally, the integration of data content monitoring and DDL change transformation processing, combined with notification, alerts, and automation, is making data transformation a more intelligent process.
- Data Distribution: Traditional JDBC loading, HTTP, and bulk loading have become essential features of every mainstream data integration tool, with competition focusing on the breadth of data source support. Automated DDL changes reduce developers’ workload and ensure the smooth execution of data integration tasks. Various vendors employ their methods to handle complex scenarios where data table definitions change. Integration with large models is emerging as a new trend, allowing internal enterprise data to interface with large models, though it is currently the domain of enthusiasts in some open-source communities.
- Data Storage: Next-generation data integration tools come with caching capabilities. Previously, this caching existed locally, but now distributed storage and distributed checkpoint/snapshot technologies are used. Effective utilization of cloud storage is also becoming a new direction, especially in scenarios involving large data caches requiring data replay and recording.
- Data Structure Migration: This part deals with whether automatic table creation and inspection can be performed during the data integration process. Automatic table creation involves automatically creating tables/data structures in the target system that are compatible with those in the source system. This significantly reduces the workload of data development engineers. Automatic schema inference is a more complex scenario. In the EtLT architecture, in the event of real-time data DDL changes or changes in data fields, automatic inference of their rationality allows users to identify issues with data integration tasks before they run. The industry is still in the experimentation phase regarding this aspect.
Computational Model
The computational model evolves with the changing landscape of ETL, ELT, and EtLT. It has transitioned from emphasizing computation in the early stages to focusing on transmission in the middle stages, and now emphasizes lightweight computation during real-time transmission:
- Offline Data Synchronization: This has become the most basic data integration requirement for every enterprise. However, the performance varies under different architectures. Overall, ETL architecture tools have much lower performance than ELT and EtLT tools under conditions of large-scale data.
- Real-time Data Synchronization: With the popularity of real-time data warehouses and data lakes, real-time data synchronization has become an essential factor for every enterprise to consider when integrating data. More and more companies are beginning to use real-time synchronization.
- Batch-Streaming Integration: New-generation data integration engines are designed from the outset to consider batch-stream integration, providing more effective synchronization methods for different enterprise scenarios. In contrast, most traditional engines were designed to focus on either real-time or offline scenarios, resulting in poor performance for batch data synchronization. Unified use of batch and streaming can perform better in data initialization and hybrid batch-stream environments.
- Cloud Native: Overseas data integration tools are more aggressive in this aspect because they are billed on a pay-as-you-go basis. Therefore, the ability to quickly obtain/release responsive computing resources for each task is the core competitiveness and profit source for every company. In contrast, progress in big data cloud native integration in China is still relatively slow, so it remains a subject of exploration for only a few companies domestically.
Data Types and Typical Scenarios
- File Collection: This is a basic feature of every integration tool. However, unlike in the past, apart from standard text files, the collection of data in formats like Parquet and ORC has become standard.
- Big Data Collection: With the popularity of emerging data sources such as Snowflake, Redshift, Hudi, Iceberg, ClickHouse, Doris, and StarRocks, traditional data integration tools are significantly lagging in this regard. Users in China and the United States are generally at the same level in terms of big data usage, hence requiring vendors to adapt to these emerging data sources.
- Binlog Collection: This is a burgeoning industry in China, as it has replaced traditional tools like DataStage and Informatica during the process of informatization. However, the replacement of databases like Oracle and DB2 has not been as rapid, resulting in a large number of specialized Binlog data collection companies emerging to solve CDC problems overseas.
- Informatization Data Collection: This is a scenario unique to China. With the process of informatization, numerous domestic databases have emerged. Whether these databases’ batch and real-time collection can be adapted, presents a higher challenge for Chinese vendors.
- Sharding: In most large enterprises, sharding is commonly used to reduce the pressure on databases. Therefore, whether data integration tools support sharding has become a standard feature of professional data integration tools.
- Message Queues: Driven by data lakes and real-time data warehouses, everything related to real-time is booming. Message queues, as the representatives of enterprise real-time data exchange centers, have become indispensable options for advanced enterprises. Whether data integration tools support a sufficient number of memory/disk message queue types has become one of the hottest features.
- Unstructured Data: Non-structural data sources such as MongoDB and Elasticsearch have become essential for enterprises. Data integration also supports such data sources correspondingly.
- Big Model Data: Numerous startups worldwide are working on quickly interacting with enterprise data and large
- SaaS integration: This is a very popular feature overseas but has yet to generate significant demand in China.
- Data unified scheduling: Integrating data integration with scheduling systems, especially coordinating real-time data through scheduling systems and subsequent data warehouse tasks, is essential for building real-time data warehouses.
- Real-time data warehouse/data lake: These are currently the most popular scenarios for enterprises. Real-time data entry into warehouses/lakes enables the advantages of next-generation data warehouses/lakes to be realized.
- Data disaster recovery backup: With the enhancement of data integration real-time capabilities and CDC support, integration in the traditional disaster recovery field has emerged. Some data integration and disaster recovery vendors have begun to work in each other’s areas. However, due to significant differences in detail between disaster recovery and integration scenarios, vendors penetrating each other’s domains may lack functionality and require iterative improvements over time.
Operation and Monitoring
In data integration, operation and monitoring are essential functionalities. Effective operation and monitoring significantly reduce the workload of system operation and development personnel in case of data issues.
- Flow control: Modern data integration tools control traffic from multiple aspects such as task parallelism, single-task JDBC parallelism, and single JDBC reading volume, ensuring minimal impact on source systems.
- Task/table-level statistics: Task-level and table-level synchronization statistics are crucial for managing operations and maintenance personnel during data integration processes.
- Step-by-step trial run: Due to support for real-time data, SaaS, and lightweight transformation, running a complex data flow directly becomes more complicated. Therefore, some advanced companies have introduced step-by-step trial run functionality for efficient development and operation.
- Table change event capture: This is an emerging feature in real-time data processing, allowing users to make changes or alerts in a predefined manner when table changes occur in the source system, thereby maximizing the stability of real-time data.
- Batch-stream integrated scheduling: After real-time CDC and stream processing, integration with traditional batch data warehouse tasks is inevitable. However, ensuring accurate startup of batch data without affecting data stream operation remains a challenge. This is why integration and batch-stream integrated scheduling are related.
- Intelligent diagnosis/tuning/resource optimization: In cluster and cloud-native scenarios, effectively utilizing existing resources and recommending correct solutions in case of problems are hot topics among the most advanced data integration companies. However, achieving production-level intelligent applications may take some time.
Core Capabilities
There are many important functionalities in data integration, but the following points are the most critical. The lack of these capabilities may have a significant impact during enterprise usage.
- Full/incremental synchronization: Separate full/incremental synchronization has become a necessary feature of every data integration tool. However, the automatic switch from full to incremental mode has not yet become widespread among small and medium-sized vendors, requiring manual switching by users.
- CDC capture: As enterprise demands for real-time data increase, CDC capture has become a core competitive advantage of data integration. The support for the CDC from multiple data sources, the requirements, and the impact of the CDC on source databases, often become the core competitiveness of data integration tools.
- Data diversity: Supporting multiple data sources has become a “red ocean competition” in data integration tools. Better support for users’ existing system data sources often leads to a more advantageous position in business competition.
- Checkpoint resumption: Whether real-time and batch data integration supports checkpoint resumption is helpful in quickly recovering from error data scenes in many scenarios or assisting in recovery in some exceptional cases. However, only a few tools currently support this feature.
- Concurrency/limiting speed: Data integration tools need to be highly concurrent when speed is required and effectively reduce the impact on source systems when slow. This has become a necessary feature of integration tools.
- Multitable synchronization/whole-database migration: This refers not only to convenient selection in the interface but also to whether JDBC or existing integration tasks can be reused at the engine level, thereby making better use of existing resources and completing data integration quickly.
Performance Optimization
In addition to core capabilities, performance often represents whether users need more resources or whether the hardware and cloud costs of data integration tools are low enough. However, extreme performance is currently unnecessary, and it is often considered the third factor after interface support and core capabilities.
- Timeliness: Minute-level integration has gradually exited the stage of history, and supporting second-level data integration has become a very popular feature. However, millisecond-level data integration scenarios are still relatively rare, mostly appearing in disaster recovery special scenarios.
- Data scale: Most scenarios currently involve Tb-level data integration, while Pb-level data integration is implemented by open-source tools used by Internet giants. Eb-level data integration will not appear in the short term.
- High throughput: High throughput mainly depends on whether integration tools can effectively utilize network and CPU resources to achieve the maximum value of theoretical data integration. In this regard, tools based on ELT and EtLT have obvious advantages over ETL tools.
- Distributed integration: Dynamic fault tolerance is more important than dynamic scaling and cloud native. The ability of a large data integration task to automatically tolerate errors in hardware and network failure situations is a basic function when doing large-scale data integration. Scalability and cloud native are derived requirements in this scenario.
- Accuracy: How data integration ensures consistency is a complex task. In addition to using multiple technologies to ensure “Exactly Once,” CRC verification is done. Third-party data quality inspection tools are also needed rather than just “self-certification.” Therefore, data integration tools often cooperate with data scheduling tools to verify data accuracy.
- Stability: This is the result of multiple functions. Ensuring the stability of individual tasks is important in terms of availability, task isolation, data isolation, permissions, and encryption control. When problems occur in a single task or department, they should not affect other tasks and departments.
- Ecology: Excellent data integration tools have a large ecosystem that supports synchronization with multiple data sources and integration with upstream and downstream scheduling and monitoring systems. Moreover, tool usability is also an important indicator involving enterprise personnel costs.
Chapter 3: Trends
In the coming years, with the proliferation of the EtLT architecture, many new scenarios will emerge in data integration, while data virtualization and DataFabric will also have significant impacts on future data integration:
- Multicloud Integration: This is already widespread globally, with most data integrations having cross-cloud integration capabilities. In China, due to the limited prevalence of clouds, this aspect is still in the early incubation stage.
- ETL Integration: As the ETL cycle declines, most enterprises will gradually migrate from tools like Kettle, Informatica, Talend, etc., to emerging EtLT architectures, thereby supporting batch-stream integrated data integration and more emerging data sources.
- ELT: Currently, most mainstream big data architectures are based on ELT. With the rise of real-time data warehouses and data lakes, ELT-related tools will gradually upgrade to EtLT tools, or add real-time EtLT tools to compensate for the lack of real-time data support in ELT architectures.
- EtLT: Globally, companies like JPMorgan, Shein, Shoppe, etc., are embedding themselves in the EtLT architecture. More companies will integrate their internal data integration tools into the EtLT architecture, combined with batch-stream integrated scheduling systems to meet enterprise DataOps-related requirements.
- Automated Governance: With the increase in data sources and real-time data, traditional governance processes cannot meet the timeliness requirements for real-time analysis. Automated governance will gradually rise within enterprises in the next few years.
- Big Model Support: As large models penetrate enterprise applications, providing data to large models becomes a necessary skill for data integration. Traditional ETL and ELT architectures are relatively difficult to adapt to real-time, large batch data scenarios, so the EtLT architecture will deepen its penetration into most enterprises along with the popularization of large models.
- ZeroETL: This is a concept proposed by Amazon, suggesting that data stored on S3 can be accessed directly by various engines without the need for ETL between different engines. In a sense, if the data scenario is not complex, and the data volume is small, a small number of engines can meet the OLAP and OLTP requirements. However, due to limited scenario support and poor performance, it will take some time for more companies to recognize this approach.
- DataFabric: Currently, many companies propose using DataFabric metadata to manage all data, eliminating the need for ETL/ELT during queries and directly accessing underlying data. This technology is still in the experimental stage, with significant challenges in query response and scenario adaptation. It can meet the needs of simple scenarios with small data queries, but for complex big data scenarios, the EtLT architecture will still be necessary for the foreseeable future.
- Data Virtualization: The basic idea is similar to the execution layer of DataFabric. Data does not need to be moved; instead, it is queried directly through ad-hoc query interfaces and compute engines (e.g., Presto, TrinoDB) to translate data stored in underlying data storage or data engines. However, in the case of large amounts of data, engine query efficiency and memory consumption often fail to meet expectations, so it is only used in scenarios with small amounts of data.
From an overall trend perspective, with the explosive growth of global data, the emergence of large models, and the proliferation of data engines for various scenarios, the rise of real-time data has brought data integration back to the forefront of the data field.
If data is considered a new energy source, then data integration is like the pipeline of this new energy. The more data engines there are, the higher the efficiency, data source compatibility, and usability requirements of the pipeline will be.
Although data integration will eventually face challenges from Zero ETL, data virtualization, and DataFabric, in the visible future, the performance, accuracy, and ROI of these technologies have always failed to reach the level of popularity of data integration.
Otherwise, the most popular data engines in the United States should not be SnowFlake or DeltaLake but TrinoDB. Of course, I believe that in the next 10 years, under the circumstances of DataFabric x large models, virtualization + EtLT + data routing may be the ultimate solution for data integration.
In short, as long as data volume grows, the pipelines between data will always exist.
How to Use the Data Integration Maturity Model
Firstly, the maturity model provides a comprehensive view of current and potential future technologies that may be utilized in data integration over the next 10 years. It offers individuals insight into personal skill development and assists enterprises in designing and selecting appropriate technological architectures. Additionally, it provides guidance on key development areas within the data integration industry.
For enterprises, technology maturity aids in assessing the level of investment in a particular technology. For a mature technology, it is likely to have been in use for many years, supporting business operations effectively. However, as technological advancements reach a plateau, consideration can be given to adopting newer, more promising technologies to achieve higher business value. Technologies in decline are likely to face increasing limitations and issues in supporting business operations, gradually being replaced by newer technologies within 3-5 years.
When introducing such technologies, it’s essential to consider their business value and the current state of the enterprise. Popular technologies, on the other hand, are prioritized by enterprises due to their widespread validation among early adopters, with the majority of businesses and technology companies endorsing them. Their business value has been verified, and they are expected to dominate the market in the next 1-2 years.
Growing technologies require consideration based on their business value, having passed the early adoption phase, and having their technological and business values validated by early adopters. They have not yet been fully embraced in the market due to reasons such as branding and promotion but are likely to become popular technologies and future industry standards.
Forward-looking technologies are generally cutting-edge and used by early adopters, offering some business value. However, their general applicability and ROI have not been fully validated. Enterprises can consider limited adoption in areas where they provide significant business value.
For individuals, mature and declining technologies offer limited learning and research value, as they are already widely adopted. Focusing on popular technologies can be advantageous for employment prospects, as they are highly sought after in the industry.
However, competition in this area is fierce, requiring a certain depth of understanding to stand out. Growing technologies are worth delving into as they are likely to become popular in the future, and early experience can lead to expertise when they reach their peak popularity.
Forward-looking technologies, while potentially leading to groundbreaking innovations, may also fail. Individuals may choose to invest time and effort based on personal interests. While these technologies may be far from job requirements and practical application, forward-thinking companies may inquire about them during interviews to assess the candidate’s foresight.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.