
包阅导读总结
1. 关键词:OHTA、手部化身、单张图像、数据驱动、VR
2. 总结:
CVPR 2024 上,字节跳动 PICO 交互感知团队提出 OHTA 方法,仅需单张图像即可创建高保真手部化身,解决了现有技术数据需求大的问题,支持多种下游任务,在 VR 等领域有应用前景。
3. 主要内容:
– 背景
– 传统手部建模方法依赖昂贵扫描数据或高超建模技巧
– 数据驱动方法创建手部虚拟化身有显著限制
– OHTA 旨在提供便捷通用的单张图像构建手部化身方法及支持多样下游任务
– 方法
– 总体是数据驱动的神经渲染算法,有独立对象编码表示形状和纹理信息
– 采用两阶段策略,先学习手部先验知识,再通过单张图像构建手部化身
– 创新网络结构,提出多分辨率场概念,更好捕获纹理与阴影细节
– 实验结果与应用
– 在开放场景有强鲁棒性,支持多种下游编辑应用
– 单图化身生成与驱动效果好,优于其他方法
– 能进行手型几何与肤色纹理编辑、文本生成手部虚拟化身
思维导图:
文章地址:https://mp.weixin.qq.com/s/KL0UADrqV5ZFzz5QjthD3w
文章来源:mp.weixin.qq.com
作者:闻超、郑晓铮
发布时间:2024/6/19 8:48
语言:中文
总字数:2297字
预计阅读时间:10分钟
评分:88分
标签:虚拟现实,化身创建,计算机视觉,数据驱动方法
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
VR 中虚拟化身的进步正在逐渐融合真实与虚拟世界,并重塑我们的日常生活。虚拟化身构建需要精细渲染人体的各个部分,其中,手部在人机交互体验中发挥着核心作用。因此,将手部转换成数字形式至关重要,这样就可以在虚拟环境中创建个性化、可控制且高度写实的虚拟化身。
快速和个性化的手部虚拟化身创建的需求变得越来越重要,但现有技术通常需要大量输入数据,在某些情况下可能会很麻烦甚至不切实际。因此,通过轻量级的输入甚至是单张图像,快速构建手部模型是一个亟待解决的问题。

在近日召开的计算机视觉与模式识别会议(CVPR)2024 会议中,来自字节跳动 PICO 交互感知的研究团队发表了论文《OHTA: One-shot Hand Avatar via Data-driven Implicit Priors》。该论文提出了一种新方法 OHTA(One-shot Hand avaTAr),该方法仅需一张图像即可创建高保真度的手部化身。OHTA 通过学习和利用数据驱动的先验来解决虚拟化身构建在数据有限情况下的固有困难。
论文链接:https://arxiv.org/abs/2402.18969
项目主页:https://zxz267.github.io/OHTA/
代码链接:https://github.com/bytedance/OHTA/
背景
传统的手部外观建模方法依赖于纹理贴图和三维网格模型。然而,个性化手部网格和纹理贴图的构建通常需要昂贵的扫描数据或高超的建模技巧。近年来,研究重心逐渐转向使用数据驱动的方法来创建手部虚拟化身。
尽管隐式手部表示最近取得了显著进展,但仍存在需要大量连续或多视图图像才能获得高保真、可驱动手部虚拟化身的显著限制。对于普通用户来说,获取如此密集的输入数据往往非常费力且不切实际。
OHTA 旨在提供一种便捷的、基于单张图像构建手部化身的通用方法,并支持多样的下游任务。
方法
总体来看,OHTA 是一种使用数据驱动的神经渲染算法。对于每个人的手部,都有独立的对象编码(ID code)来表示形状和纹理信息。为了达到更高的真实感,OHTA 对纹理、阴影和几何信息进行了分解,并通过体积渲染创建手部的虚拟化身。
为了在推理时实现一致性和个性化的手部表示,OHTA 采用了两阶段的训练和推理策略。训练阶段在有标注的大量数据中学习手部先验知识,而推理阶段仅需用户提供一张图像或一段文字。
训练和推理创新:两阶段策略
现有技术往往只能针对单人进行训练,无法泛化,显然不适用于单图构建虚拟化身的场景。为了解决这一问题,OHTA 提出了先验学习与个性化优化的两阶段策略。
首先,让模型学习到手部的先验,包括纹理、几何以及不同动作时手部自遮挡导致的阴影。
其次,实现个性化的手部化身创建,保证先验学习的结果能和输入手部图像完美匹配,让单张图像中的手部动起来。
OHTA 的两阶段策略
具体流程如下:
-
第一阶段(训练):手部先验知识学习
-
使用包含不同对象、手势和视角的大量带标注手部训练数据。
-
利用这些数据对手部先验网络进行训练。
-
第二阶段(推理):单张图像构建手部化身
-
使用现有的手部姿态估计器,得到单张图像对应的手部标注。
-
利用手部先验网络的逆向匹配(inversion)与优化微调(finetune),得到单张输入图像对应的手部化身。
-
逆向匹配仅调整对象编码(ID code),优化微调(finetune)则同步更新部分网络权重。
网络结构创新:多分辨率场
为了更好捕获手部的纹理与阴影细节,区别于常见的体积渲染所使用的网络结构与神经辐射场表示,OHTA 算法创新性地提出了多分辨率场的概念。多分辨率场以显式与隐式结合的形式连接了手部网格与体积渲染中的空间采样点。
OHTA 中使用手部网格作为特征编码的脚手架(mesh scaffold),将网格表面采样的点作为锚点(anchor points),通过不同分辨率的锚点插值得到不同分辨率的特征,构建多分辨率场。通过融合多分辨率的特征,OHTA 能够更好的捕捉手部的细节变化。
此外,仅需要改变网络模块的输入数据形式,这种表示形式就可以分别建模纹理与阴影。
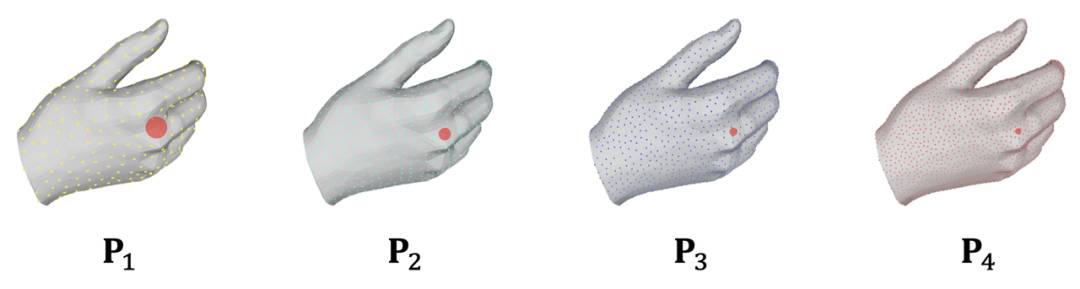
不同分辨率的锚点
实验结果与应用
OHTA 在开放场景(in-the-wild)展现了非常强的鲁棒性,并且支持多种下游的编辑应用。
单图化身生成与驱动
无论是何种肤色、何种手势,仅需要一张图像就能够生成个性化的手部化身。即使是 in-the-wild 开放场景也能准确捕捉手部图像的纹理与形状细节,让手部图像动起来。

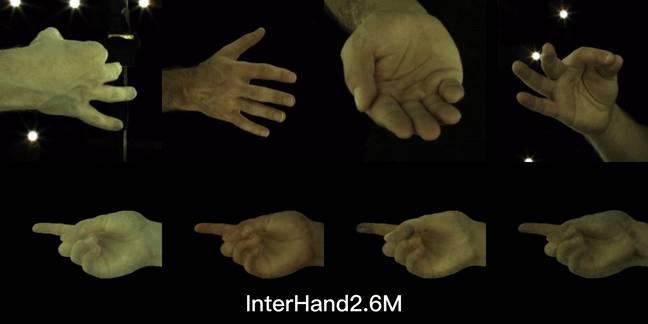

与其他方法在公开数据集 Interhand2.6M 上的对比,黑框所示图为输入的单张图像
手型几何 & 肤色纹理编辑


纹理编辑 & 文本生成手部虚拟化身
