
包阅导读总结
1. 关键词:谷歌、Gemini、AI 模型、多模态、发展历程
2. 总结:
本文主要介绍了谷歌的 AI 模型 Gemini,包括其核心特点、模型家族、发展历程、内置 Chrome 的使用方法、API 及相关应用示例,强调了其在多模态处理和性能方面的优势,以及在不同场景下的应用。
3. 主要内容:
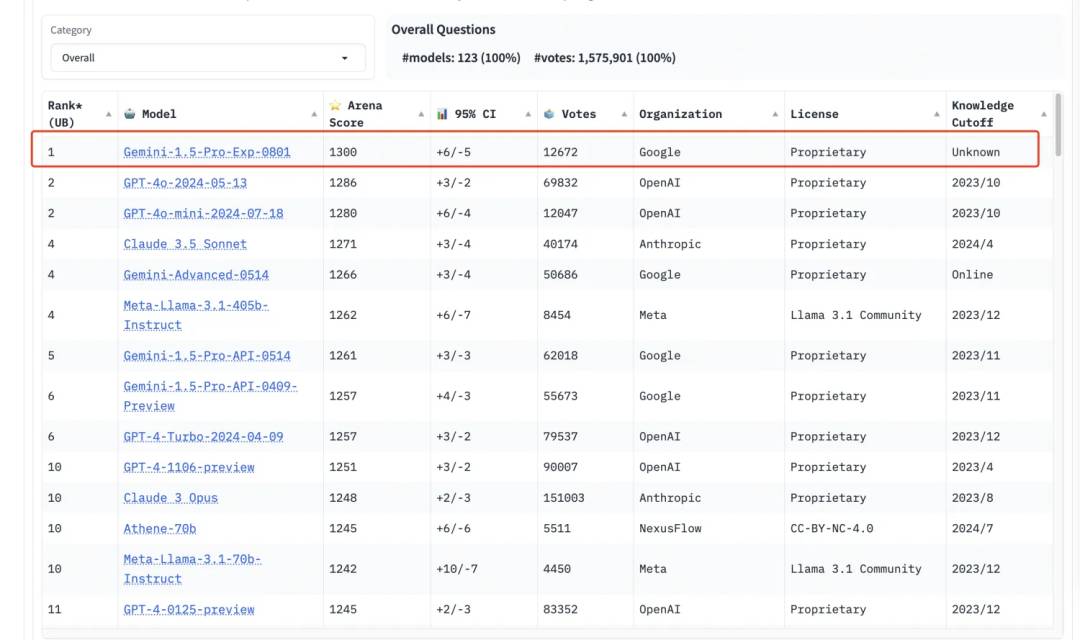
– 背景:2023-2024 年 AI 领域竞争激烈,谷歌发布 Gemini 1.5 Pro(0801),性能超越 ChatGPT-4 夺得榜首。
– 什么是 Gemini:多模态 AI 模型,旨在超越 ChatGPT 4.0,能处理多类型数据,具备强推理等能力。
– 核心特点:多模态能力、更强推理能力、高效适应性、增强 AI 助手。
– 模型家族:包括 Nano、Pro 等,各有特点和应用场景。
– 发展历程:从 Bard 到不断迭代的 Gemini 模型。
– 内置 Chrome:介绍了内置 Chrome 的 Gemini Nano 模型的使用方法、优缺点及前置条件。
– API:提供 Gemini API SDK,支持多种编程语言,有获取密钥和调用的说明。
– 使用示例:包括利用 Chrome 控制台和内置方法实现聊天框,以及通过 API 在 Web 应用中的示例。
思维导图: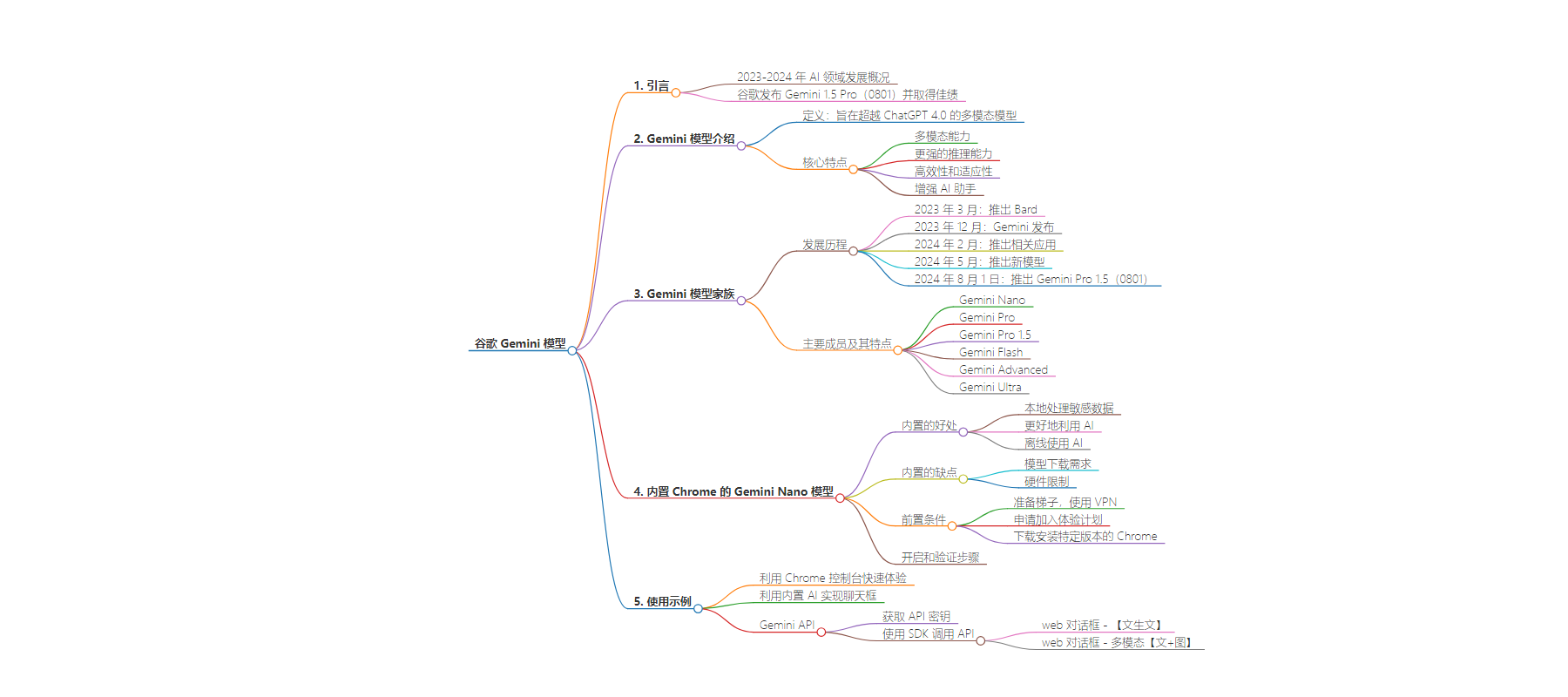
文章地址:https://mp.weixin.qq.com/s/ZjvPWY4ajUkqfsHrc7PYAg
文章来源:mp.weixin.qq.com
作者:韩国芳
发布时间:2024/9/4 11:30
语言:中文
总字数:5924字
预计阅读时间:24分钟
评分:90分
标签:AI模型,多模态,谷歌,推理能力,应用场景
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
2023-2024年是AI领域蓬勃发展的时期,各家科技巨头纷纷推出自家的大模型,竞争激烈。谷歌在AI领域持续深耕,并于2024年8月1日发布了Gemini 1.5 Pro(0801),其卓越的性能超越了ChatGPT-4,使得谷歌夺得lmsys竞技场第一,中文任务也位列榜首。本文将深入探讨Google的AI大模型发展历程,并以实际案例展示Gemini的强大功能。
什么是Gemini?
Gemini 是 Google 推出的多模态 AI 模型,旨在超越 OpenAI 的 ChatGPT 4.0。它不仅拥有强大的文本理解和生成能力,还能处理图像、视频等多模态数据,并进行更深层次的推理和理解,为用户带来更智能、更人性化的交互体验。
Gemini核心特点:
-
多模态能力:Gemini能够处理文本、图像、音频、视频和代码等多种数据类型,使其在信息处理的广度和深度上超越了ChatGPT-4.0,能够更好地理解和响应用户的需求。 -
更强的推理能力:Gemini拥有强大的上下文理解能力,能够处理长文本和复杂代码,进行深入的推理和分析,从而提供更精准、更全面的答案。 -
高效性和适应性: Gemini设计高效,能够在各种平台上运行,从大型数据中心到移动设备,都能提供稳定的性能,满足不同场景下的应用需求。 -
增强AI助手:凭借其先进的功能,Gemini显著增强了AI助手的有效性和可靠性。它支持复杂任务的执行,为用户提供更智能和直观的互动。无论是协助编写代码、生成详细报告,还是创建多媒体内容,Gemini都提升了AI助手的标准。
Gemeni模型家族
为了迎战 ChatGPT,谷歌于 2023 年 3 月推出聊天机器人 Bard,但它的最初产品能力并不足够好、甚至在现场演示时回答出错, 导致股价暴跌。
为了在竞争激烈的AI领域保持领先地位,谷歌不断迭代更新其AI模型。从最初的LaMDA模型,到功能更强大的PaLM模型,再到如今的Gemini模型,谷歌的AI技术一直在不断进步。
模型发展历程:
-
2023年3月: 谷歌推出聊天机器人Bard,最初基于LaMDA模型。 -
2023年12月: Gemini 发布,Bard 宣布将运行在 Gemini Pro 上。 -
2024年2月: 推出 Gemini Pro、Gemini Advanced,Bard 改名为 Gemini,并推出 Gemini 的 Android 和 iOS 应用。 -
2024年5月: 推出 Gemini Pro 1.5、Gemini 1.5 Flash。 -
2024年8月1日: 推出 Gemini Pro 1.5(0801),性能超越 ChatGPT-4。
Gemini模型家族的主要成员及其特点:
| 模型 | 主要特点 | 应用场景 |
|---|---|---|
| Gemini Nano | 轻量级模型,适用于设备端,如内置在移动端、PC端、Mac端,做一些无需强大计算的场景,为用户提供更便捷、实时快速的AI体验。 | 设备端应用,如实时翻译、语音识别等。 |
| Gemini Pro | 强大的通用模型,适用于各种文本处理任务 | 问答、摘要、翻译、代码生成。 |
| Gemini Pro 1.5 | 在 Gemini Pro 的基础上进行改进,性能更强,推理能力更出色 | 更加复杂的文本处理任务,例如长文本理解、代码分析、专业领域的知识问答 |
| Gemini Flash | 在Gemini Ultra和Gemini Pro之间的一个平衡点,兼具能力和效率。能够处理各种各样的任务,从简单的问答到复杂的推理。 | 多种任务,如对话、摘要、翻译等。 |
| Gemini Advanced | 基于 Google 最强大的 AI 模型 Gemini Ultra 1.0,提供更高级的功能和更强大的性能 | 专业的AI应用,例如科学研究、艺术创作、复杂的数据分析 |
| Gemini Ultra | 最强大、最通用的模型,能够处理高度复杂的任务,在许多基准测试中,Gemini Ultra的表现都超越了其他大型语言模型。 | 通用型AI,适用于各种复杂任务。如科学研究、艺术创作等。它能够理解和生成各种形式的内容,包括文本、代码、图像等。 |
此部分相关链接
模型种类介绍:https://deepmind.google/technologies/gemini/
模型进化:https://gemini.google.com/updates
各模型收费信息: https://ai.google.dev/pricing?hl=zh-cn
内置Chrome AI
Gemini Nano模型 将内置到 Chrome 中,供大家免费使用,为用户提供更便捷的AI体验。
使用 chrome 本地模型的好处:
-
本地处理敏感数据:设备端 AI 可以改进您的隐私保护。例如,如果您处理敏感数据,则可以通过端到端加密为用户提供 AI 功能。 -
更好地利用 AI:降低服务器负载,用户的设备可以承担一些处理负载,以换取对功能的更多访问权限。例如,如果您提供高级 AI 功能,则可以使用设备端 AI 来预览这些功能,以便潜在客户可以看到您产品的优势,而无需支付额外费用。这种混合方法还可以帮助您管理推断费用,尤其是针对常用用户流的推断费用。 -
离线使用 AI :即使没有互联网连接,您的用户也可以使用 AI 功能。
使用 chrome 本地模型的缺点:
-
模型下载需求:目前模型1.2G,需要手动打开浏览器配置下载,占用一定存储空间。 -
硬件限制:设备性能差异使得不能保证所有设备都能高效运行复杂的AI模型。
前置条件
-
准备好梯子,使用 VPN 连接到支持 Gemini 的国家。 -
申请加入体验计划,在 Chrome for developer官网(developer.chrome.com/docs/ai/bui…)点击“加入我们的早期预览版计划”。
-
下载安装最新的 Chrome Canary版 或Chrome Dev版,并确认你的版本等于或高于 128.0.6545.0,请在这个页面找到适合自己电脑的版本https://www.chromium.org/getting-involved/dev-channel/
-
如果下载后可用存储空间低于 10 GB,模型将会被删除。请注意,有些操作系统可能会不同地报告实际的可用磁盘空间,例如,是否包括垃圾箱中占用的磁盘空间。在 macOS 上,使用“磁盘工具”来查看有代表性的可用磁盘空间。
开启Gemini Nano和Prompt API
-
打开下载好的Chrome,地址栏输入 chrome://flags/#optimization-guide-on-device-model ,选择 "Enabled BypassPerfRequirement"状态,这将绕过性能检查,这些检查可能会阻碍在你的设备上下载 Gemini Nano。 -
打开 chrome://flags/#prompt-api-for-gemini-nano ,选择 "Enabled"状态; -
开启完前面两项,浏览器就会自动下载大模型,重新启动Chrome。
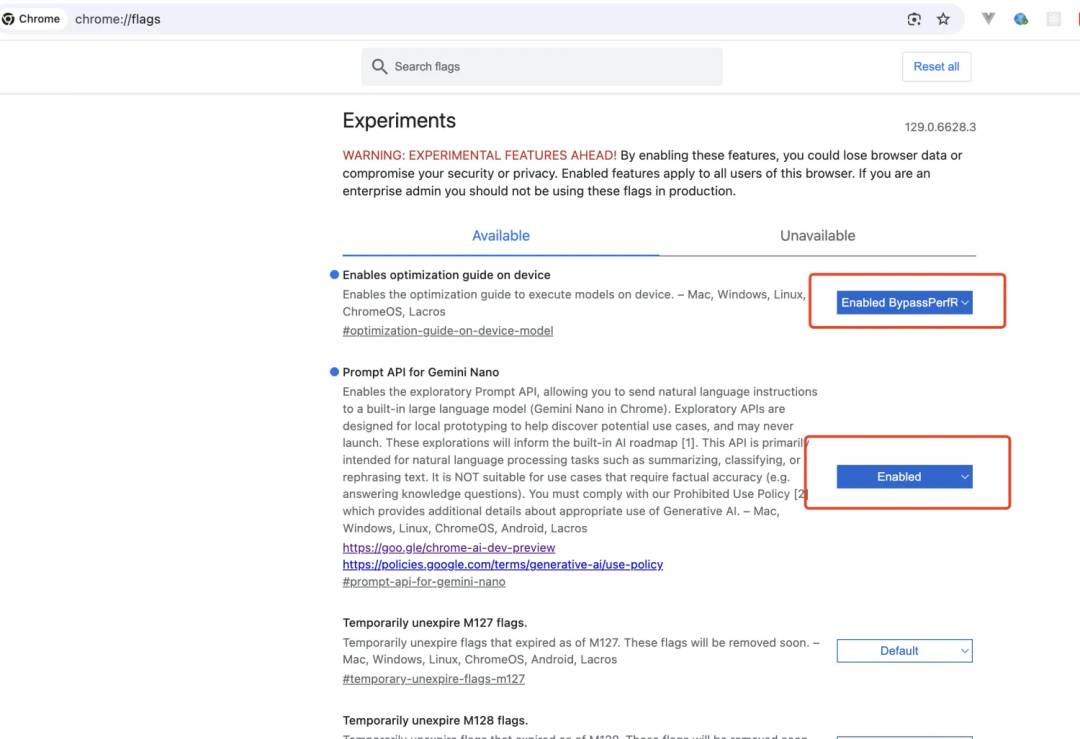
验证 Gemini Nano 的可用性:
-
到了这一步可能很多人会遇到模型下载不下来的情况,所以请确保将梯子🪜节点设置为一个可用国家,以及文章前面所说的前置条件。现在在控制台输入 (await ai.assistant.capabilities()).available;,
如果没有返回 readily,代表失败,请继续以下步骤:
📣🆕强制 Chrome 识别你想使用此 API。为此,打开开发者工具,在控制台中发送await ai.assistant.create();。这可能会失败,但这操作会强制提醒chrome下载模型。
-
控制台执行完 await ai.assistant.create();后,重新启动 Chrome。 -
打开 Chrome 的新标签页,访问 chrome://components
-
确认 Gemini Nano 是否可用或正在下载。 -
你需要看到“Optimization Guide On Device Model”存在,版本大于或等于 2024.5.21.1031。 -
如果没有列出版本,点击“Check for update”强制下载。
-
一旦模型下载完成并且版本高于上述版本,打开开发者工具并在控制台中发送 (await ai.assistant.capabilities()).available;。如果返回 “readily”,那么你就准备好了。
-
否则,重新启动,等待一会儿(模型1.2G,比较大),然后从步骤 1 再试一次。
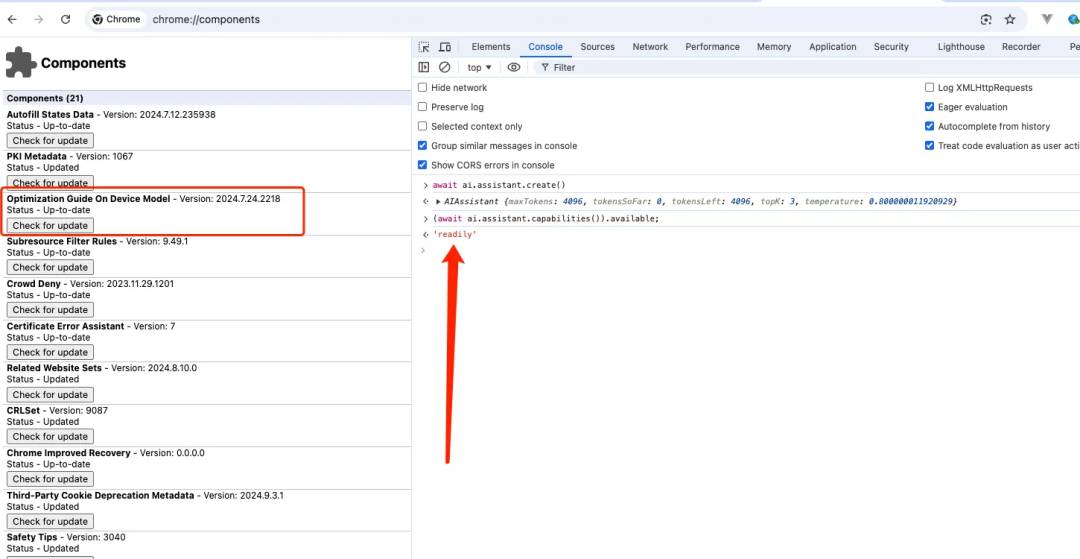
如果组件列表没有Optimization Guide On Device Model,或者(await ai.assistant.capabilities()).available的结果返回不是readily,可以尝试更换其他国家节点、修改浏览器语言为English后,重启浏览器。如果依然还是不行,请卸载干净浏览器,更换为**Chrome Canary版 或Chrome Dev版的另外一个版本尝试。**
官方文档的使用步骤参考:https://developer.chrome.com/docs/ai/built-in?hl=zh-cn#get_an_early_preview
使用示例
利用Chrome控制台快速体验:
1. 控制台输入`const session = await ai.assistant.create();`
2. 接着输入 `const result = await session.prompt("实现一个js防抖函数");`
3. 打印结果` console.log(result)`
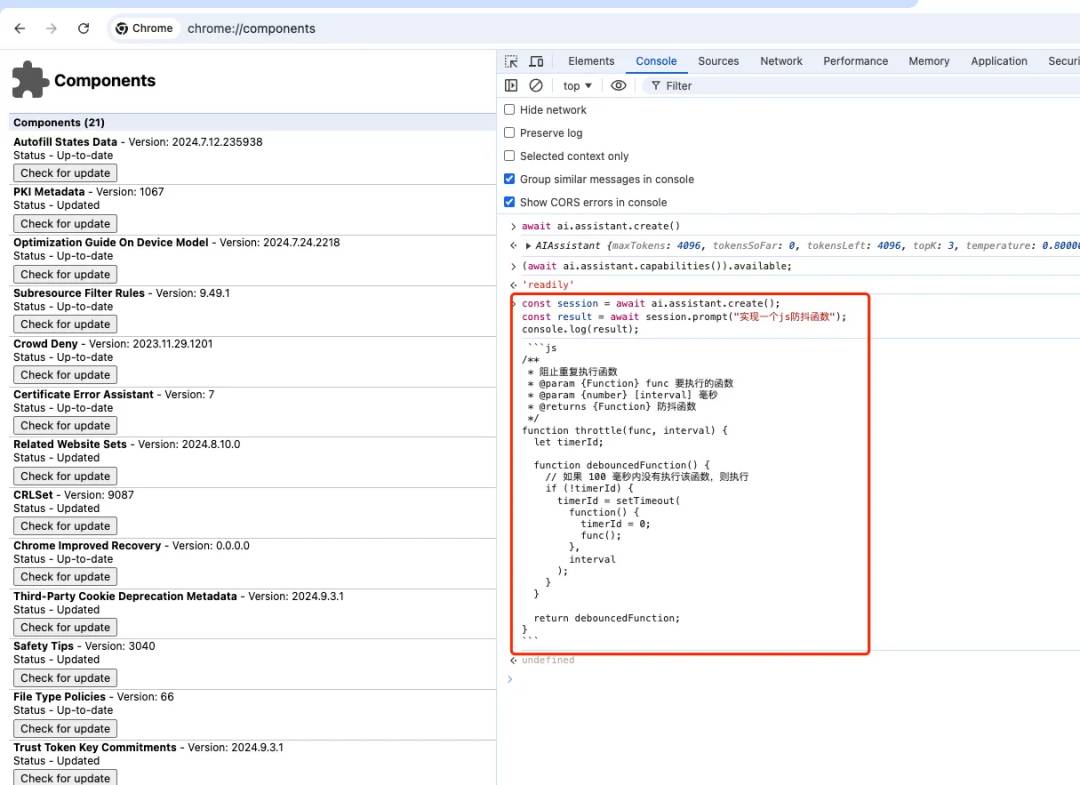
可以看到Chrome将模型能力,加到了window.ai上,我们在web应用就可以随时使用内置AI能力了。
利用内置AI实现一个聊天框
-
首先创建一个聊天组件,使用的是tailwind + react实现。 利用react-syntax-highlighter实现的code语法高亮。
importReact,{useState}from'react';
importReactMarkdownfrom'react-markdown';
import{PrismasSyntaxHighlighter}from'react-syntax-highlighter';
import{solarizedlight}from'react-syntax-highlighter/dist/esm/styles/prism';
constChatBox=({handleSubmit,messages,input,setInput})=>{
return(
<divclassName="w-fullmax-w-3xlmx-automy-10bg-whiteshadow-lgrounded-lgoverflow-hidden">
<divclassName="p-6h-96overflow-y-scroll">
{messages.map((msg,index)=>(
<div
key={index}
className={`flex${msg.type==='user'?'justify-end':'justify-start'}mb-2`}
>
<div
className={`p-2text-leftrounded-lg${msg.type==='user'?'bg-blue-500text-white':'bg-gray-200'}`}
>
<ReactMarkdown
components={{
code:({node,inline,className,children,...props})=>{
constmatch=/language-(\w+)/.exec(className||'');
return!inline&&match?(
<SyntaxHighlighter
style={solarizedlight}
language={match[1]}
PreTag="div"
{...props}
>
{String(children).replace(/\n$/,'')}
</SyntaxHighlighter>
):(
<codeclassName={className}{...props}>
{children}
</code>
);
}
}}
>
{msg.text}
</ReactMarkdown>
</div>
</div>
))}
</div>
<formonSubmit={handleSubmit}className="border-tborder-gray-200">
<divclassName="flexp-4">
<input
type="text"
value={input}
onChange={(e)=>setInput(e.target.value)}
placeholder="askgeminianything"
className="flex-1p-2borderborder-gray-300rounded-lgfocus:outline-nonefocus:ring-2focus:ring-blue-500"
/>
<button
type="submit"
className="ml-2px-4py-2bg-blue-500text-whiterounded-lghover:bg-blue-600focus:outline-nonefocus:ring-2focus:ring-blue-500"
>
发送
</button>
</div>
</form>
</div>
);
};
exportdefaultChatBox;
-
发送消息时,调用浏览器内置方法 window.ai.createTextSession()创建会话。
importReact,{useState}from'react';
importChatBoxfrom'../../componets/ChatBox';
constBuiltIn=()=>{
const[messages,setMessages]=useState([]);
const[input,setInput]=useState('');
consthandleSubmit=async(e)=>{
e.preventDefault();
if(input.trim()){
letnewMessage=[...messages,{text:input.trim(),type:'user'},{text:'Loading...',type:'bot'}]
setMessages(newMessage);
//使用内置AI服务
constsession=awaitwindow.ai.assistant.create();
//以普通的方式返回
constresponse=awaitsession.prompt(input.trim());
newMessage.splice(newMessage.length-1,1,{text:response,type:'bot'});
setMessages(newMessage);
////以流式返回
//conststream=awaitsession.promptStreaming(input.trim());
//forawait(constresponseofstream){
//newMessage.splice(newMessage.length-1,1,{text:response,type:'bot'});
//console.log(response);
//setMessages(newMessage);
//}
setInput('');
}
};
return(
<>
<h1className="text-3xlfont-boldunderlinetext-center">Built-inAI</h1>
<ChatBoxhandleSubmit={handleSubmit}input={input}setInput={setInput}messages={messages}/>
</>
);
};
exportdefaultBuiltIn;
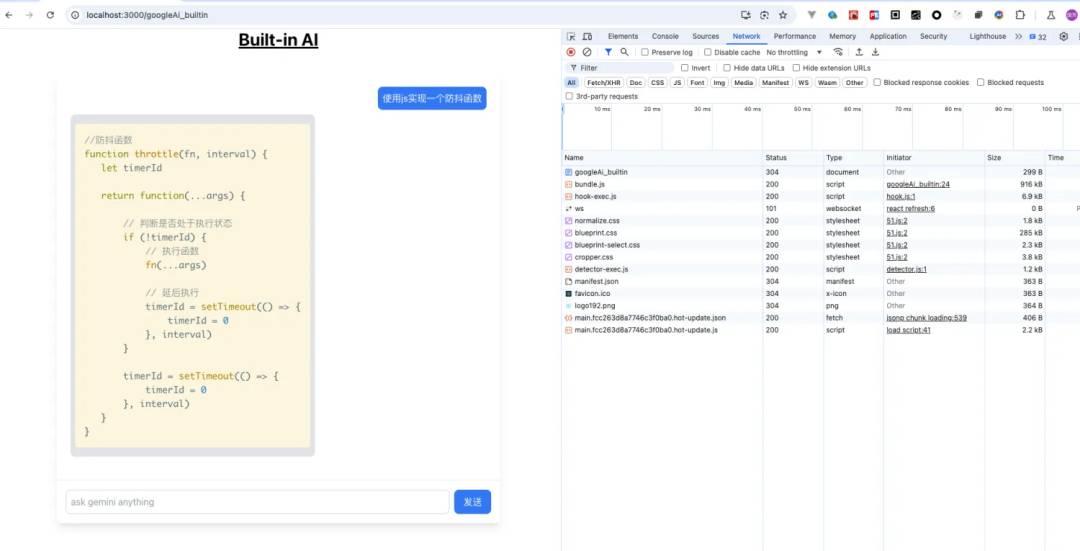
效果如图:
network是没有任何请求的,完全都得本地模型,没有任何网络传输。
Gemini API
Google 提供了 Gemini API SDK,方便开发者将 Gemini 模型集成到自己的应用中。API 支持多种编程语言,包括 Python、Node.js、Web 应用、Dart (Flutter)、Android、Go 和 REST。
使用Gemini API
-
获取 API 密钥: https://aistudio.google.com/app/apikey?hl=zh-cn -
使用 SDK 调用 API: 根据所使用的编程语言选择相应的 SDK,参考官方文档进行集成。
web对话框 – 【文生文】
importReact,{useState}from'react';
importChatBoxfrom'../../componets/ChatBox';
importMultimodalfrom'./Multimodal'
//引入sdk
import{GoogleGenerativeAI}from'@google/generative-ai';
constAPI_KEY='你自己申请的apikey';
constgenAI=newGoogleGenerativeAI(API_KEY);
//选择一个想用的模型这里我选择gemini-1.5-flash
constmodel=genAI.getGenerativeModel({model:"gemini-1.5-flash"});
constGoogleAIWeb=()=>{
const[messages,setMessages]=useState([]);
const[input,setInput]=useState('');
consthandleSubmit=async(e)=>{
e.preventDefault();
if(input.trim()){
//prompt输入的提示文本
constresult=awaitmodel.generateContent(input);
constresponse=awaitresult.response;
consttext=response.text();
setMessages([...newMessage,{text,type:'bot'}]);
setInput('');
}
};
return(
<>
<h1className="text-3xlfont-boldunderlinetext-center">GoogleAIWeb</h1>
{/**聊天框展示*/}
<ChatBoxhandleSubmit={handleSubmit}input={input}setInput={setInput}messages={messages}/>
</>
)
};
exportdefaultGoogleAIWeb;
效果如图:
可以看到此时与Chrome 内置AI助手不一样, network里面有了请求,走的实时的网络大模型数据。

web对话框-多模态【文+图】
importReact,{useState,useRef}from"react";
import{GoogleGenerativeAI}from"@google/generative-ai";
constAPI_KEY="你自己的apikey";
//AccessyourAPIkey(see"SetupyourAPIkey"above)
constgenAI=newGoogleGenerativeAI(API_KEY);
functionApp(){
const[image,setImage]=useState([]);
const[question,setQuestion]=useState("");
const[response,setResponse]=useState("");
consthandleImageUpload=(event)=>{
//这里可能是多张图片
constfiles=event.target.files;
for(leti=0;i<files.length;i++){
constfile=files[i];
if(file){
constreader=newFileReader();
reader.onloadend=()=>{
setImage((prev)=>[...prev,reader.result]);
};
reader.readAsDataURL(file);
}
}
};
consthandleQuestionChange=(event)=>{
setQuestion(event.target.value);
};
//ConvertsaFileobjecttoaGoogleGenerativeAI.Partobject.
asyncfunctionfileToGenerativePart(file){
constbase64EncodedDataPromise=newPromise((resolve)=>{
constreader=newFileReader();
reader.onloadend=()=>resolve(reader.result.split(",")[1]);
reader.readAsDataURL(file);
});
return{
inlineData:{data:awaitbase64EncodedDataPromise,mimeType:file.type},
};
}
consthandleSend=async()=>{
if(image&&question){
try{
//TheGemini1.5modelsareversatileandworkwithbothtext-onlyandmultimodalprompts
constmodel=genAI.getGenerativeModel({model:"gemini-1.5-flash"});
constprompt=question;
constfileInputEl=document.querySelector("input[type=file]");
constimageParts=awaitPromise.all(
[...fileInputEl.files].map(fileToGenerativePart)
);
constresult=awaitmodel.generateContent([prompt,...imageParts]);
constresponse=awaitresult.response;
consttext=response.text();
setResponse(text);
}catch(error){
console.error("Error:",error);
setResponse("Erroroccurredwhilefetchingtheresponse.");
}
}
};
return(
<divclassName="min-h-screenflexflex-colitems-centerjustify-centerbg-gray-100p-4">
<divclassName="bg-whitep-6rounded-lgshadow-lgw-fullmax-w-md">
<h1className="text-2xlfont-boldmb-4">多模态聊天框展示</h1>
<input
type="file"
multiple
onChange={handleImageUpload}
className="mb-4"
/>
{image?.map((item)=>(
<divclassName="mb-4">
<imgsrc={item}alt="Uploaded"className="w-fullh-auto"/>
</div>
))}
{/*{image&&(
<divclassName="mb-4">
<imgsrc={image}alt="Uploaded"className="w-fullh-auto"/>
</div>
)}*/}
<textarea
value={question}
onChange={handleQuestionChange}
placeholder="Askaquestionabouttheimage..."
className="w-fullp-2borderroundedmb-4"
/>
<button
onClick={handleSend}
className="w-fullbg-blue-500text-whitep-2rounded"
>
Send
</button>
{response&&(
<divclassName="mt-4p-2borderroundedbg-gray-50">
<strong>Response:</strong>{response}
</div>
)}
</div>
</div>
);
}
exportdefaultApp;
效果如图:
在这个示例中,我们调用Chrome API const result = await model.generateContent([prompt, ...imageParts]); 同时输入了文字+图片, 大模型为我们返回了响应的结果。

Chrome Dev Tools – AI Assist
在Chrome 125之后的版本里,Chrome支持在控制台里使用Gemini AI分析错误和警告,帮助开发者更高效地调试和修复问题。
详情请查看:https://developer.chrome.com/docs/devtools/console/understand-messages
需要满足以下几个条件:
-
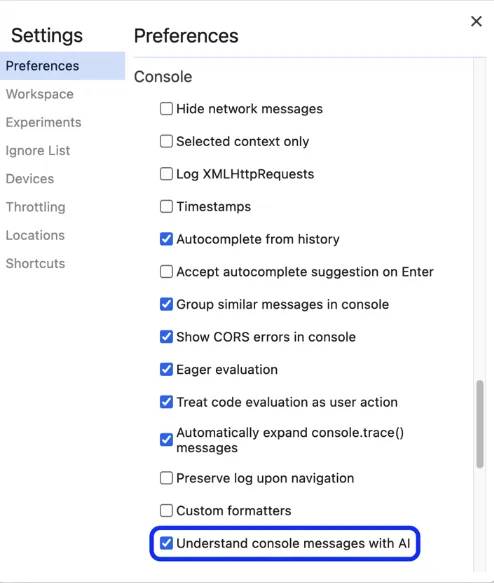
设置语言为英语,Settings > Preferences > Appearance > Language, 选择 English (US) -
在开发者工具中启用了“Understand console messages with AI”。 -
打开开发者工具,然后前往 settings 设置, 点击Preferences > Console, 打开 Understand console messages with AI
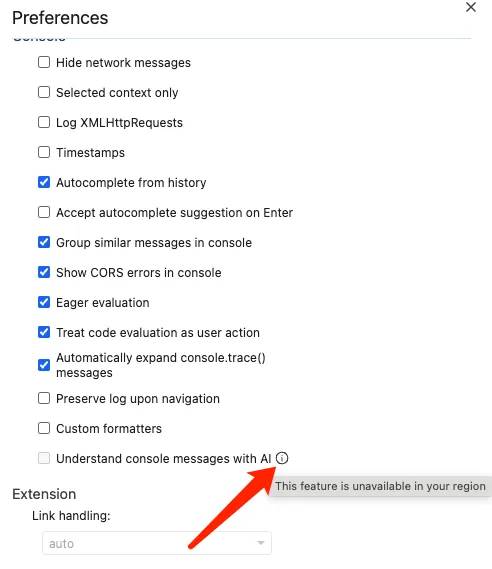
如果
Understand console messages with AI无法开启的话,hover上去会有提示不可开启的原因。如果提示年龄,则需要登录账号,并确保年龄设置大于18岁。如果已经科学上网,并且ip在可以使用的范围内,仍旧提示当前地区不可使用,可以修改下浏览器和系统的语言、地理位置设置,然后重启。
使用示例
-
在组件内,实现一个能触发错误的组件,如下当点击的时候,使用const 声明了一个常量, 并给这个常量做自加,
import{useState}from'react';
exportdefaultfunctionTest(){
const[count,setCount]=useState(0);
constonClick=()=>{
constoldCount=count;
setCount(oldCount++);
};
return(
<div>
<button
className='bg-blue-500text-whitep-2roundedhover:bg-blue-600'
onClick={onClick}
>
点击次数:{count}
</button>
</div>
);
}
-
点击按钮,触发错误;打开控制台,hover到错误信息上,会有一个图标;
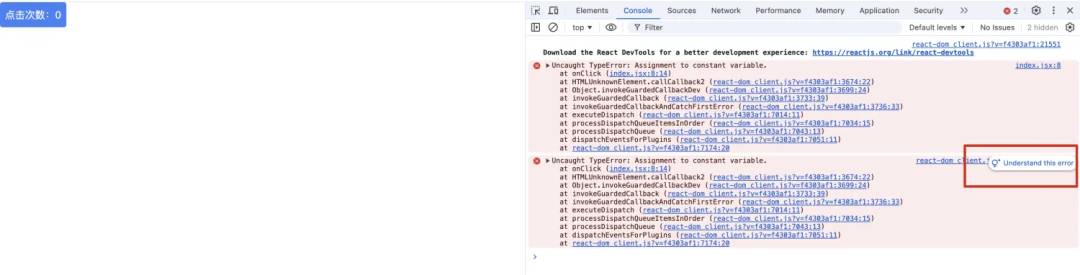
-
点击图标,第一次使用会要求同意协议等,点击下一步、同意协议即可:
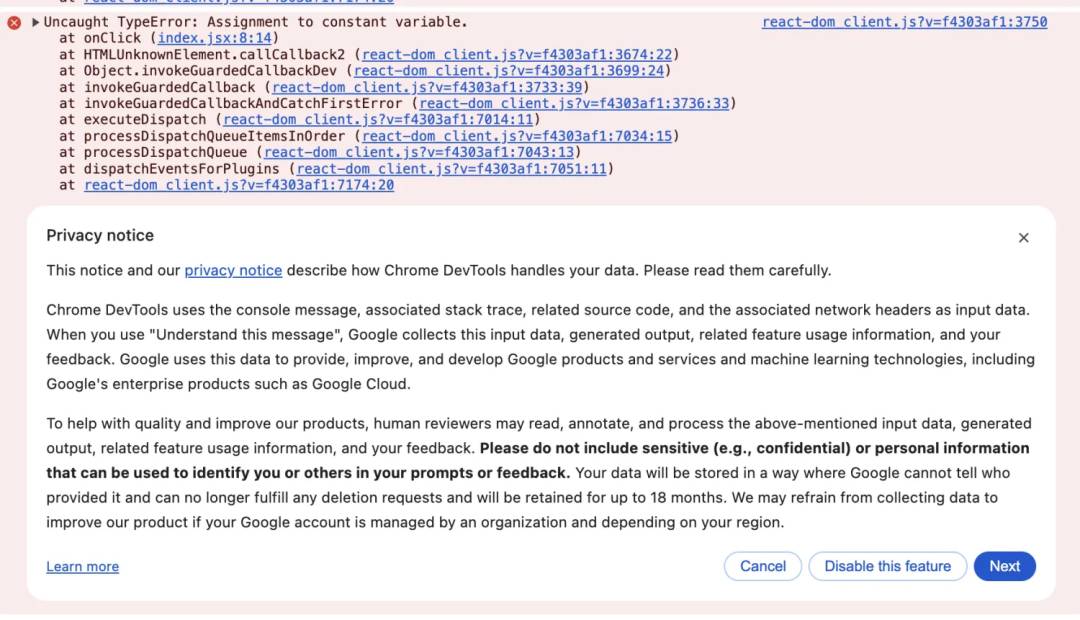
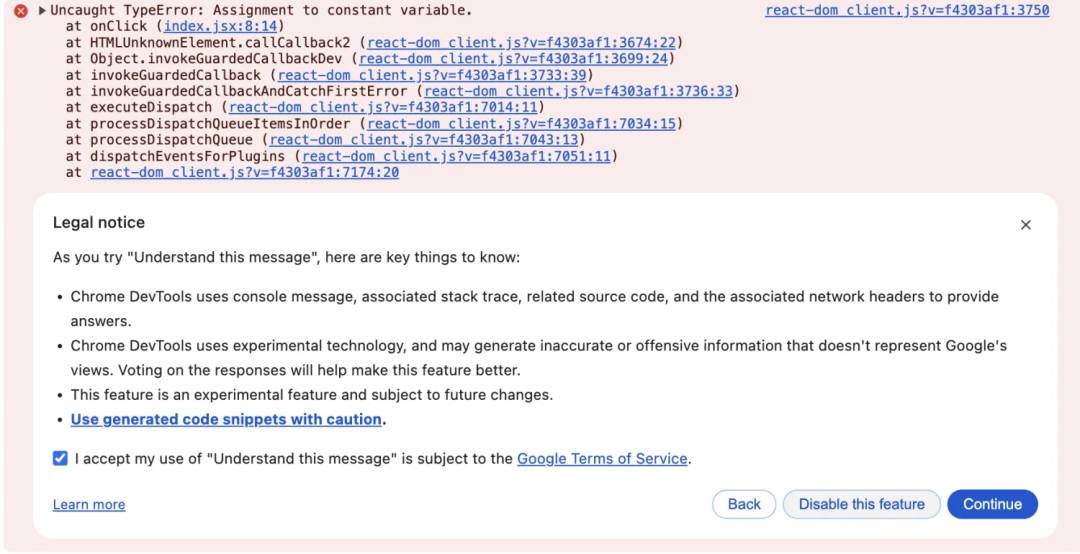

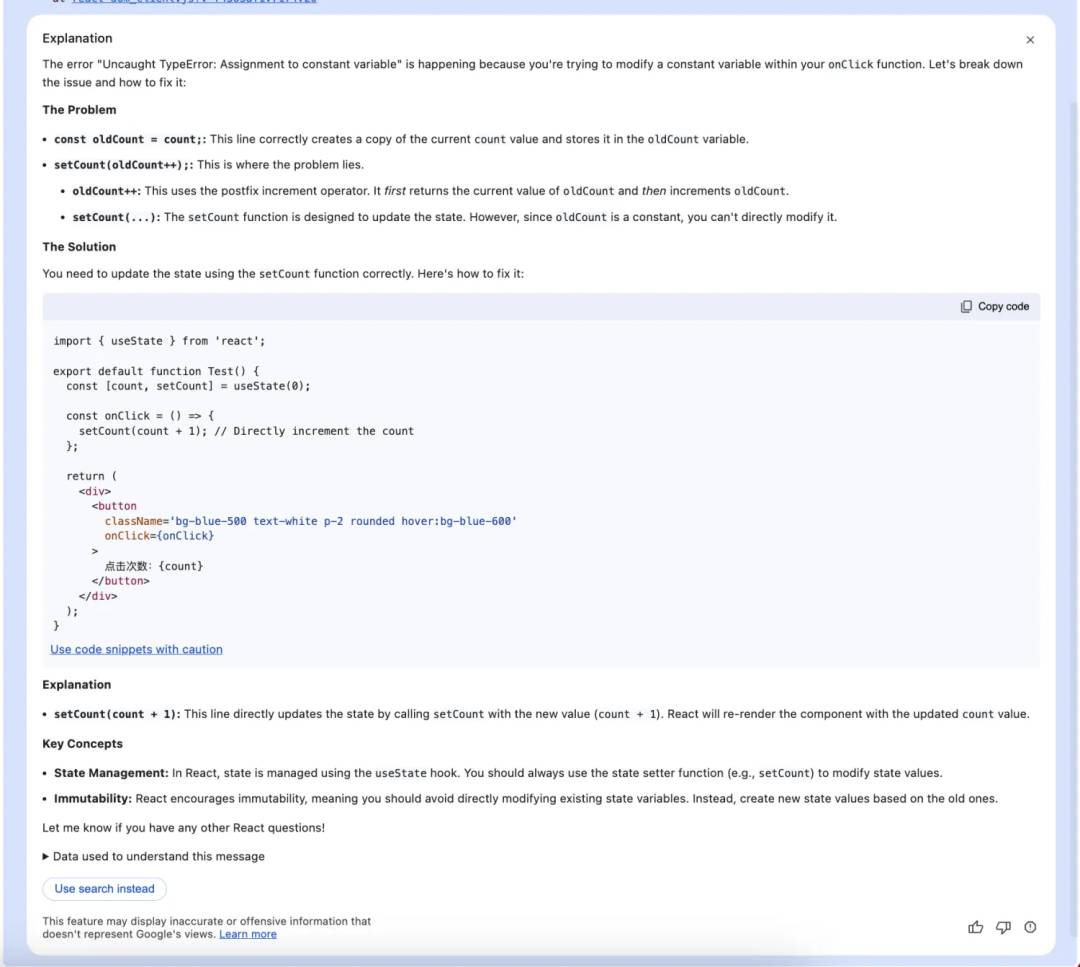
从上面可以看出,不仅给出了问题发生的原因及具体的问题代码,并且还给出了解决方案,这在开发过程中,可以快速的帮我们定位错误。
与ChatGPT对比,及未来展望
各个模型之间对比评测: https://chat.lmsys.org/
Gemini by Google
-
-
多模态能力强: Gemini在处理文本、代码、图像等多种模态数据方面表现出色,能够更深入地理解和生成内容。 -
推理能力出众: 在复杂的推理任务中,Gemini表现出较强的逻辑推理能力和解决问题的能力。 -
强大的数据基础: 依托 Google 的庞大数据资源和技术积累,Gemini 在知识图谱和搜索信息的实时性上有一定优势。能够回答各种各样的问题,并提供高质量的答案。
-
-
-
模型较大: 由于模型参数量巨大,部署和运行成本较高。 -
目前相对较新的产品:与 ChatGPT 等相比,市场成熟度和用户基础相对较低。
-
Chat GPT by Open AI
-
-
强大的语言生成能力:作为目前最流行的聊天 AI 模型之一,ChatGPT 以其语言生成质量高、上下文理解力强而著称。 -
丰富的插件生态:支持插件扩展和 API 接口,可以根据需求自定义功能。 -
开源社区活跃: 拥有庞大的开源社区,有利于模型的改进和发展。
-
-
-
知识更新慢: 模型的知识库更新较慢,可能无法及时回答最新的问题。 -
付费墙和订阅模式:高级功能和模型需要付费订阅才能使用,对普通用户来说可能成本较高。
每种模型都有其独特的优势和不足,选择哪种模型取决于具体的应用场景。
-
如果需要处理多模态数据、进行复杂推理,并且对模型的知识广度有较高要求,那么Gemini是一个不错的选择。 -
如果需要与用户进行自然流畅的对话,并且对开源社区的支持比较看重,那么Chat GPT是一个不错的选择。 -
如果对模型的安全性、无害性有较高要求,那么Claude是一个不错的选择。 -
如果需要提高代码编写效率,那么Copilot是一个不错的选择。
参考链接
模型种类介绍:https://deepmind.google/technologies/gemini/
模型进化:https://gemini.google.com/updates
各模型收费信息: https://ai.google.dev/pricing?hl=zh-cn
在web中使用Gemini API:https://ai.google.dev/gemini-api/docs/get-started/tutorial?lang=web
内置AI开启步骤: https://developer.chrome.com/docs/ai/built-in?hl=zh-cn#get_an_early_preview
Chrome控制台AI助手:https://developer.chrome.com/docs/devtools/console/understand-messages
各个模型之间对比评测: https://chat.lmsys.org/