
包阅导读总结
1. 关键词:Generative Language Models、Transformer Architecture、Pretraining、Alignment Process、Public Communication
2. 总结:本文强调了向大众解释生成式语言模型的重要性,并提出一个简单的三部分框架,包括模型的 Transformer 架构、预训练过程和对齐过程,同时指出要以通俗易懂的方式进行解释。
3. 主要内容:
– 解释生成式语言模型的重要性
– 研究者和工程师需具备向他人传达其创造物细节的能力
– 沟通不畅可能导致公众怀疑或限制立法阻碍发展
– 解释生成式语言模型的框架
– Transformer 架构
– 输入嵌入向量表示的令牌序列
– 包含掩蔽自注意力和前馈变换操作
– 重复堆叠构成神经网络架构
– 语言模型预训练
– 利用自监督学习的下一个令牌预测目标
– 从大型原始文本语料库中采样序列进行训练
– 对齐过程
– 定义对齐标准如有用和无害
– 通过监督微调及从人类反馈的强化学习进行微调
思维导图: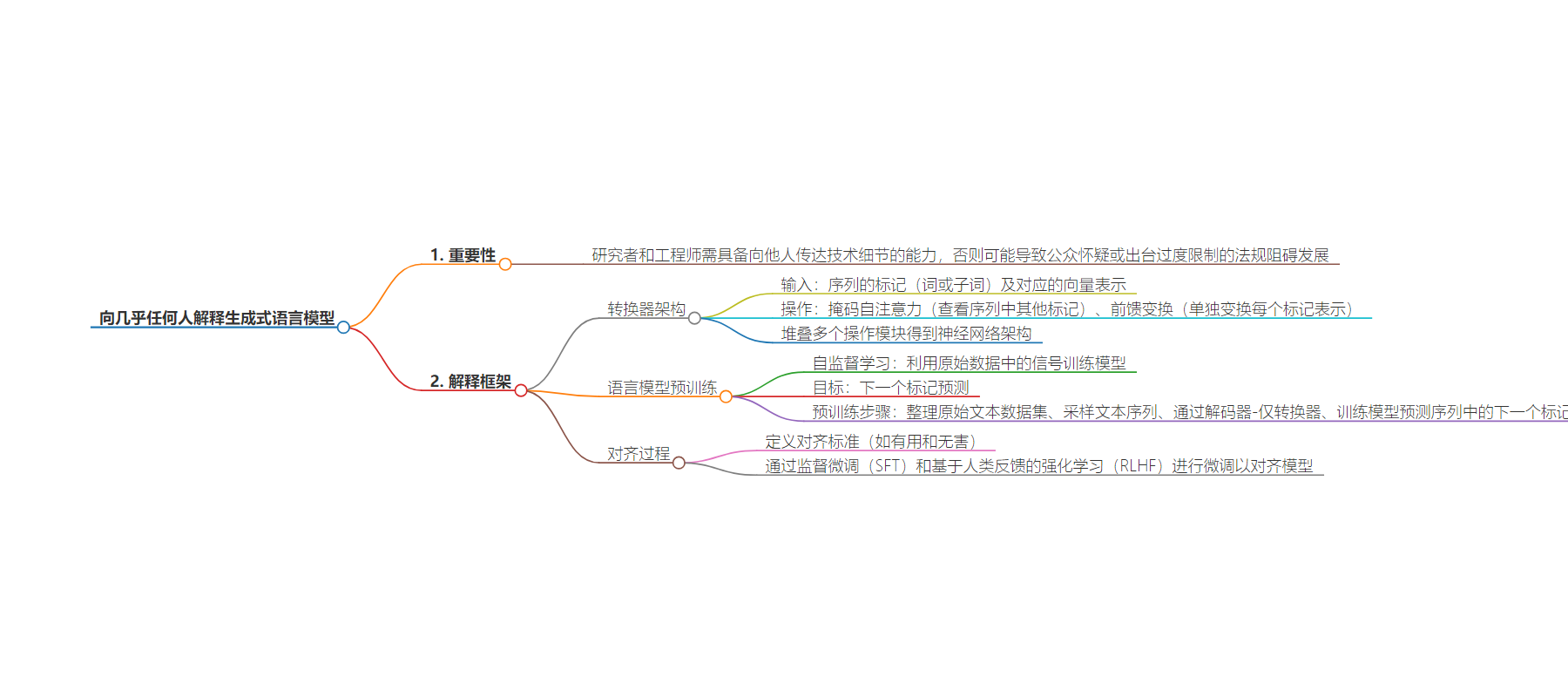
文章地址:https://stackoverflow.blog/2024/06/27/explaining-generative-language-models-to-almost-anyone/
文章来源:stackoverflow.blog
作者:Cameron R. Wolfe,PhD
发布时间:2024/6/27 16:20
语言:英文
总字数:539字
预计阅读时间:3分钟
评分:86分
标签:生成式人工智能,LLM,变压器架构,自监督学习,对齐过程
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Generative AI has now become a popular topic among both researchers and the general public. Now more than ever before, it is important that researchers and engineers (i.e., those building the technology) develop an ability to communicate the nuances of their creations to others. A failure to communicate the technical aspects of AI in an understandable and accessible manner could lead to widespread public skepticism (e.g., research on nuclear energy went down a comparable path) or the enactment of overly-restrictive legislation that hinders forward progress in our field.
Here’s a simple, three-part framework that you can use to explain generative language models to (almost) anyone.
- Transformer architecture: the neural network architecture used by LLMs.
- Language model pretraining: the (initial) training process used by LLMs.
- The alignment process: how we teach LLMs to behave to our liking.
Although AI researchers might know these techniques well, it is important that we know how to explain them in simple terms as well! AI is no longer just a research topic, but rather a topic of public interest.
Most recent generative language models are based upon the transformer architecture. Although the transformer was originally proposed with two modules (i.e., an encoder and a decoder), generative LLMs use a decoder-only variant of this architecture. This architecture takes as input a sequence of tokens (i.e., words or subwords) that have been embedded into a corresponding vector representation and transforms them via two repeated operations:
- Masked self-attention: looks at other tokens in the sequence (i..e, those that precede the current token).
- Feed-forward transformation: transforms each token representation individually.
These two operations each play a distinct and crucial role. By stacking several blocks of masked self-attention and feed-forward transformations on top of each other, we get the neural network architecture that is used by most generative LLMs today.
Self-supervised learning refers to the idea of using signals that are already present in raw data to train a machine learning model. In the case of generative language models, the most commonly-used objective for self-supervised learning is next token prediction, also known as the standard language modeling objective. Interestingly, this objective—despite being quite simple to understand—is the core of all generative language models. To pretrain a generative language model, we first curate a large corpus of raw text (e.g., from books, the web, scientific publications, and much more) to use as a dataset. Starting from a randomly initialized model, we then pretrain the LLM by iteratively performing the following steps:
1. Sample a sequence of raw text from the dataset.
2. Pass this textual sequence through the decoder-only transformer.
3. Train the model to accurately predict the next token at each position within the sequence.
After pretraining, the LLM can accurately perform next token prediction, but its output is oftentimes repetitive and uninteresting. The alignment process teaches a language model how to generate text that aligns with the desires of a human user. To align a language model, we first define a set of alignment criteria (e.g., helpful and harmless). To instill each of these alignment criteria within the model, we perform fine-tuning via supervised finetuning (SFT) and reinforcement learning from human feedback (RLHF), which together form the three-step technique for alignment proposed by InstructGPT.