
包阅导读总结
1. 关键词:供应链大屏、物流系统、数据链路、稳定性、指标建设
2. 总结:本文介绍了物流供应链大屏的设计实践,历经 2 年已成熟稳定。阐述了在复杂业务场景下,结合大数据技术的框架和经验,包括数据加工链路、指标一致性等,还提及稳定性、扩展性设计及数据监控。
3. 主要内容:
– 供应链大屏设计实践
– 经过 2 年打磨,表现成熟稳定
– 为其他核心大屏建设提供思路
– 重点关注方面
– 基于 Flink 和 OLAP 的数据处理
– 保障指标的一致性
– 稳定性建设
– 数据模型存储选型
– Elasticsearch 和 ClickHouse 对比
– 结论:CH 更适合非高并发和全文检索场景
– 整体架构
– 分为 5 层,各层有明确职责
– 指标分层及一致性设计
– 以仓订单指标为例保证一致性
– 通过指标缓存表提升查询性能
– 稳定性设计
– 问题集中在 Flink、CH 环节
– 对易出问题链路进行双流和物理隔离
– 扩展性设计
– 基于 UCC 配置灵活适配业务诉求
– 数据监控
– 多种验证及监控手段组合保证数据准确
思维导图:
文章地址:https://mp.weixin.qq.com/s/zRZtl89bVgWRTnK-YmfNcg
文章来源:mp.weixin.qq.com
作者:京东物流??郑冰
发布时间:2024/7/2 9:09
语言:中文
总字数:3432字
预计阅读时间:14分钟
评分:88分
标签:供应链大屏,实时数据处理,Flink,ClickHouse,稳定性设计
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

在物流系统相关的大屏中,供应链大屏复杂度较高,数据链路较长,稳定性要求较高,当前大屏已经经过2年时间的打磨,整体表现已经相对比较成熟稳定。
本文描述了物流供应链业务较复杂的业务场景下,结合了大数据计算相关技术,总结了实时监控大屏指标建设和服务构建的框架和经验,为后续其他核心大屏的高可用和高实时性建设提供建设思路。以下几点需要重点关注:
1、基于Flink的数据加工链路和OLAP的数据分析引擎
基于目前较为成熟的实时计算Flink,结合ClickHouse搭建基础模型,借助双流和EasyData实现一键切换。
2、指标的一致性
加工和展示分离,可基于单仓原子指标进行区域和品类上卷,既保障了指标的维度一致性(单仓-区域-全国),又保障了同一个数据版本的时间一致性。
同时借助缓存库/表,来满足不同的业务场景。
3、稳定性建设
-
数据链路的稳定性
-
接口服务的兜底
-
指标准确性的验证机制
-
重算机制
本文内容有限,很多设计的小细节未能体现,感兴趣的欢迎交流,希望上述内容对正在从事大屏建设的同学有一些新的启发和思考。
在物流系统相关的大屏中,供应链大屏复杂度较高,数据链路较长,稳定性要求较高,当前大屏已经经过2年时间的打磨,整体表现已经相对比较成熟稳定。
本文描述了物流供应链业务较复杂的业务场景下,结合了大数据计算相关技术,总结了实时监控大屏指标建设和服务构建的框架和经验,为后续其他核心大屏的高可用和高实时性建设提供建设思路。以下几点需要重点关注:
1、基于Flink的数据加工链路和OLAP的数据分析引擎
基于目前较为成熟的实时计算Flink,结合ClickHouse搭建基础模型,借助双流和EasyData实现一键切换。
2、指标的一致性
加工和展示分离,可基于单仓原子指标进行区域和品类上卷,既保障了指标的维度一致性(单仓-区域-全国),又保障了同一个数据版本的时间一致性。
同时借助缓存库/表,来满足不同的业务场景。
3、稳定性建设
-
数据链路的稳定性
-
接口服务的兜底
-
指标准确性的验证机制
-
重算机制
本文内容有限,很多设计的小细节未能体现,感兴趣的欢迎交流,希望上述内容对正在从事大屏建设的同学有一些新的启发和思考。
供应链大屏是供应链事业部重要的看数工具,尤其在大促期间,为业务管理层掌握大促实时动态提供了支撑,为事业部的目标达成、排产提供重要的数据支持。
特点:
方案
2.1 数据模型存储选型
| 比较项 | Elasticsearch | ClickHouse |
|
实现原理 |
基于Lucene的分布式搜索引擎,ES通过分布式技术,利用分片与副本机制,解决了集群下搜索性能与高可用的问题。 | 基于MPP(Massively Parallel Processing)架构的分布式ROLAP(关系OLAP)分析引擎,拥有完备的管理功能,是列式数据库管理系统(DBMS)。通过使用日志合并树,稀疏索引和向量化执行引擎(CPU的SIMD单指令多数据)充分发挥了硬件优势,实现高效的计算。 |
| 写入性能 | 中等,有写入延迟问题 | 较高,吞吐量大,经测试是ES的5倍以上 |
| 查询性能 | 中等 | 高,经测试查询速度比ES快5-30倍以上 |
| 多表联合查询 | 不支持 | 支持 |
| 服务器成本 | 高 | 相同数据占用的磁盘空间只有ES的1/3到1/30,节省了磁盘空间的同时,也能有效的减少磁盘IO;另一方面ClickHouse比ES占用更少的内存,消耗更少的CPU资源 |
| SQL查询 | 不支持 | 支持 |
| 高并发支持 | 较好,经过优化可以支持上万QPS | 官方建议qps为100 |
| 全文检索 | 支持 | 不支持 |
2.2 整体架构
2.3 指标分层及一致性设计
2.4 稳定性设计
由于数据链路长,稳定性较差,问题主要集中在Flink、CH环节,恢复周期长。对于大屏等核心任务,数据的实时性和准确性要求较高,以下是历史发生过的问题:
-
CK分区太多,写入阻塞
-
CK rename操作,节点太多,表结构同步慢,导致写入报错,大量消息积压,丢消息
-
Flink机房网络故障
-
flink 偶发丢消息,未定位到原因
-
checkpoint失败
-
jdq分片不均,单个分区消息增加400倍,消息积压
-
维表数据未更新,导致丢失字段
-
上游运单模型积压,丢失部分字段
-
数据积压
-
加工逻辑复杂,偶发乱序问题
-
state未保存,丢数据
-
CK跨分区字段查询明细,性能较低
-
代码编写使用了Flink序列化未支持的格式、循环过多,导致算子背压严重
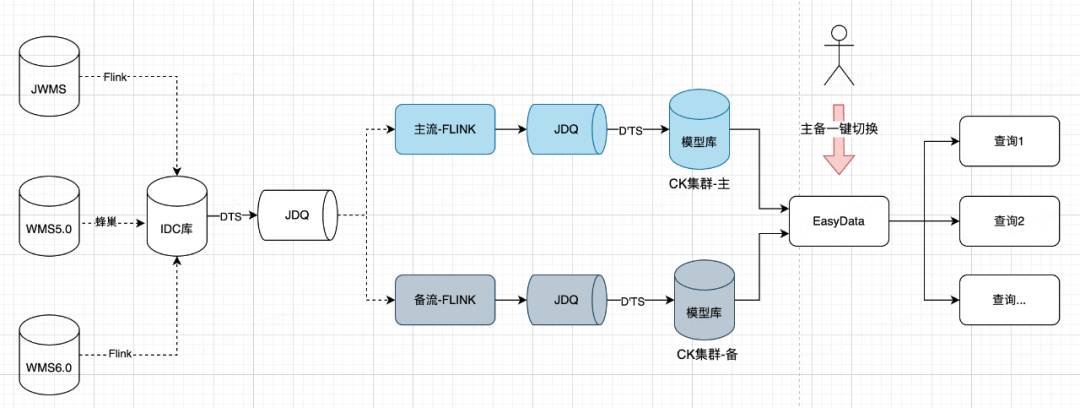
2.5 扩展性设计
基于UCC配置,通过配置灵活适配业务诉求,节约开发成本,方便定位问题和恢复;
(1)28小时模式配置化:可通过配置将任意一天切换为28小时、4小时模式,为业务和研发侧提供了充分的线上验证机会;
(2)阈值开关配置化:可通过阈值开关进行数据兜底逻辑管控,确保数据平稳;
(3)自动刷新白名单配置化:灵活配置大屏自动刷新白名单,支持封版期间人员白名单权限控制;
(4)历史日期配置化:计算预测全天指标使用指定历史日期的单量占比作为对比项,数据库里包含部分历史大促日单量数据,可灵活配置修改对比的历史日期;
(5)重算机制:可基于某一时间段进行数据重算。
参数配置:
{"thresholdEnable": "false","upperLimit": "1.6d","lowerLimit": "0.6d","zyShowFlag": true,"swShowFlag": true,"jjShowFlag": true,"wdShowFlag": true,"todayTradeCleanRateShowFlag": true,"promotionTradeCleanRateShowFlag": true,"isDebug": true,"isCacheOn": true,"isWriteMinuteAndHour": true,"isMinuteWrite": true,"isHourWrite": true,"isMinuteNotice": false,"isHourNotice": false,}
{"sTime": "2023-06-17 00:00:00","eTime": "2023-06-17 19:59:59","tbSTime": "2022-06-17 00:00:00","tbETime": "2022-06-17 19:59:59","hbSTime": "2022-11-10 00:00:00","hbETime": "2022-11-10 19:59:59","showType": "24h","special24hCompDateStr": "2022-06-17","specialCompDateStr": ""}
2.6 数据监控
多种验证及监控手段组合保证数据准确性:
1)前端自动化模型,定时截取每个大屏关键节点截图。
2)自动化抓包,分钟级记录接口调用情况,结合定时截图,便用问题排查及定位。
3)大屏结果分钟级落库,并通过Grafana,创建大屏数据监控看板,持续监控大屏数据,通过异常拐点发现问题点,避免遗漏问题。并结合不同看板分析数据趋势及变化原因。
4)结合大屏计算逻辑,通过京东动力搭建测试模型,做到自由指定时间计算大屏指标明细,验证分析大屏数据。
▪功能支撑:会员成长体系、等级计算策略、权益体系、营销底层能力支持
▪用户活跃:会员关怀、用户触达、活跃活动、业务线交叉获客、拉新促活