
包阅导读总结
1.
关键词:Observability、Disaggregated Stack、Data、Flexibility、Cost Efficiency
2.
总结:本文探讨了可观测性(Observability )及传统 o11y 栈的不足,指出分散式 o11y 栈的兴起。介绍了典型 o11y 栈的构成,阐述了分散式栈在灵活性、数据复用和成本效益方面的优势,还分析了各层面临的问题及分散式栈的应对策略。
3.
主要内容:
– Observability 与传统 o11y 栈
– 介绍 Observability 及传统 o11y 栈的构成,包括代理(Agents)、收集(Collection)、存储和查询(Storage and Query)、可视化(Visualization)层。
– 指出传统 o11y 栈的灵活性和成本问题。
– 分散式栈的兴起
– 强调其带来的关键优势,如灵活性、可复用性和成本效率。
– 分析现有 o11y 解决方案的问题。
– 分散式栈各层的分析
– 代理层:供应商特定代理的成本和数据治理要求问题,OpenTelemetry 标准带来可能性。
– 收集层:面临数据量、多样性和网络成本挑战,Kafka 等系统是流行选择。
– 存储和查询层:缺乏灵活性、成本和性能问题,选择存储系统要考虑与实时源集成、高效存储指标和日志数据等。
思维导图: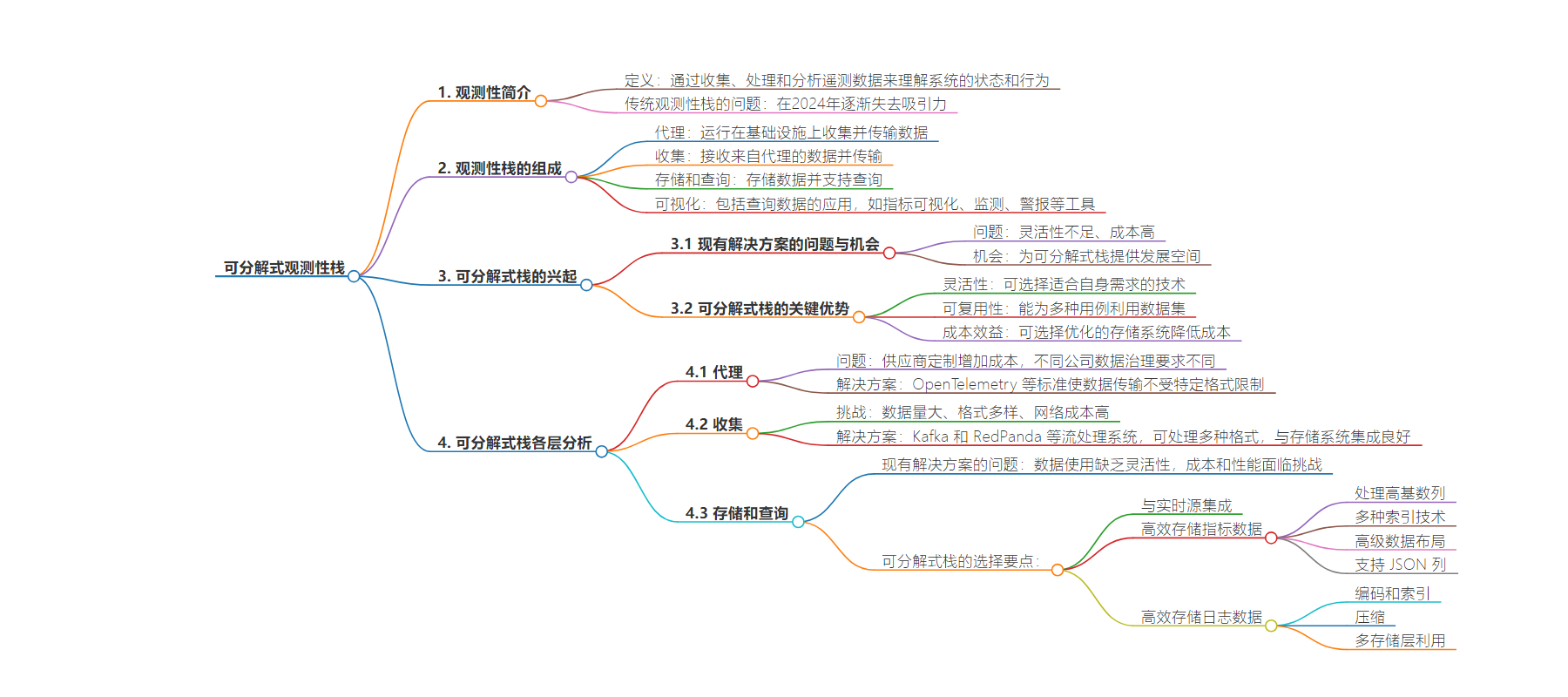
文章地址:https://thenewstack.io/reimagining-observability-the-case-for-a-disaggregated-stack/
文章来源:thenewstack.io
作者:Neha Pawar
发布时间:2024/8/29 20:52
语言:英文
总字数:2234字
预计阅读时间:9分钟
评分:85分
标签:可观测性,解耦堆栈,数据架构,成本效益,灵活性
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Observability, often abbreviated as o11y, is crucial for understanding the state and behavior of systems through the collection, processing, and analysis of telemetry data. Yet in 2024, I’ve observed the traditional o11y stack is losing traction, and it’s time for a disaggregated o11y stack.
There are key benefits of disaggregation, such as flexibility, data autonomy, extensibility, and cost-effectiveness. Additionally, there are actionable recommendations and blueprints for data teams on structuring their data architectures to embrace this disaggregated model.
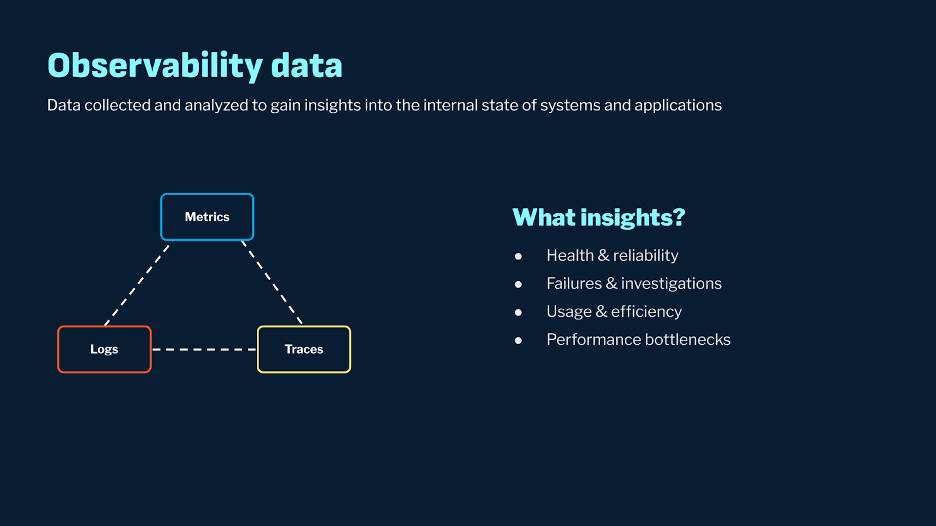
The Observability Stack
Here’s what a typical o11y stack looks like:
- Agents: These processes run on your infrastructure alongside your microservices and applications, collecting o11y data and shipping it to a central location for further analysis.
- Collection: This layer collects the incoming data from all the various agents and facilitates its transfer to the subsequent layers.
- Storage and Query: This layer stores the data from the collection step and makes it available for querying.
- Visualization: This includes applications for querying this data, such as tools for metrics visualization, monitoring, alerting, log exploration, and analytics.
Prominent solutions in the o11y space today include technologies like Datadog and Splunk.
Rise of the Disaggregated Stack
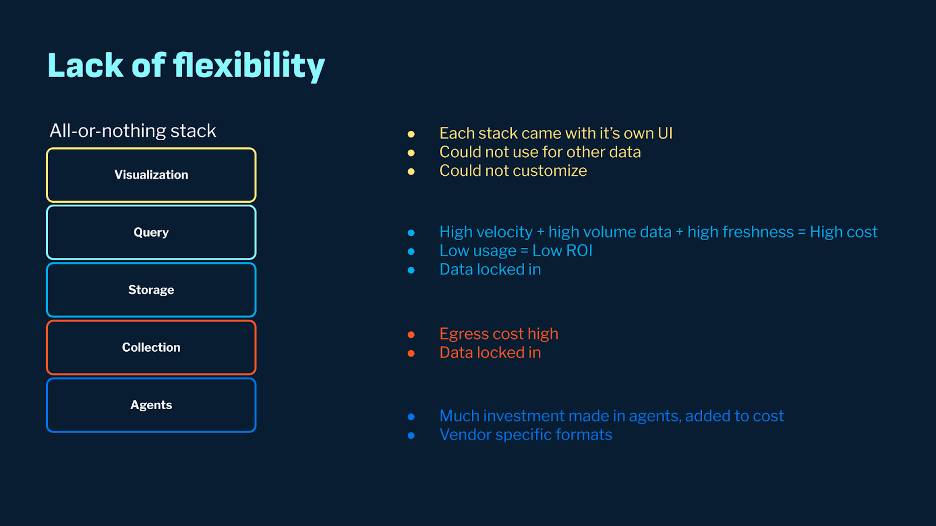
The Problem and the Opportunity
The two main problems with the o11y solutions available today are more flexibility and high cost. These issues arise because providers typically offer an all-or-nothing solution. For instance, although Datadog provides comprehensive monitoring capability, we cannot use that platform to generate real-time insights with the same data. Similarly, some of these solutions focus on the end-to-end solution and may need to be optimized for efficient storage and query computation, thus trading off simplicity with cost.
Many companies today are leaning towards a disaggregated stack, which provides the following key benefits:
- Flexibility: Companies often have a highly opinionated data stack and can choose specific technologies in each layer that suit their needs.
- Reusability: Data is the most essential commodity for any company. With a disaggregated stack, they can build one platform to leverage their datasets for various use cases (including observability)
- Cost Efficiency: A disaggregated stack allows a choice of storage-optimized systems that lower the overall service cost.
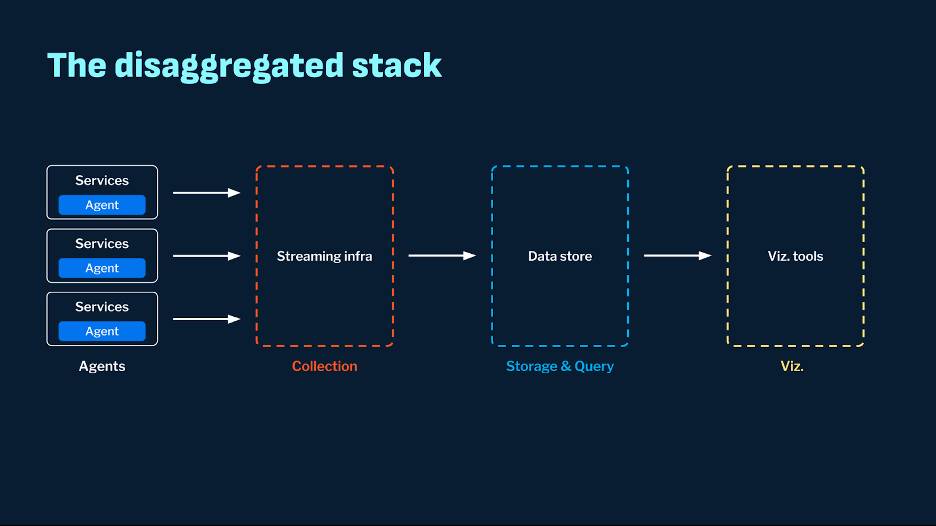
Review each layer and understand how a disaggregated stack can help overcome corresponding issues.
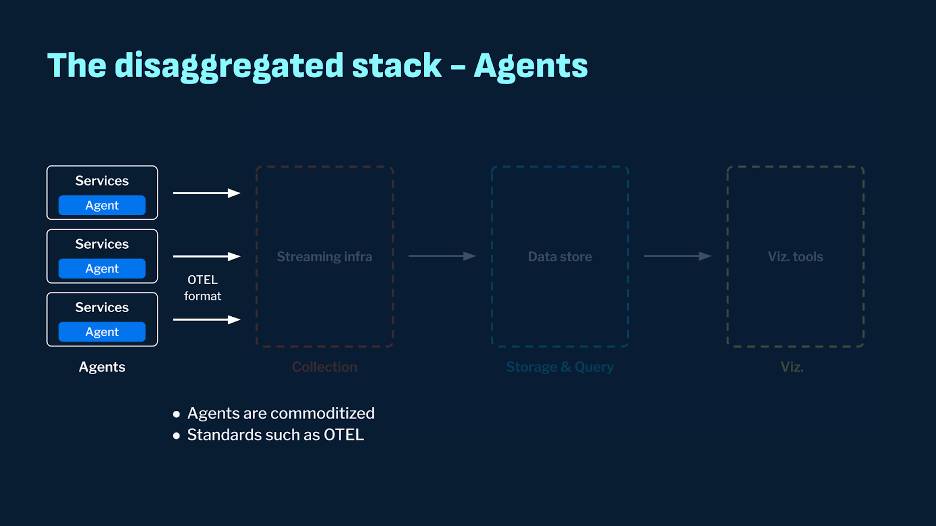
Agents
Vendors have invested significantly in their agents, tailored to their stacks with specific formats. This specificity increases the overall cost of the solution. In addition, different companies have varied data governance requirements, which may require additional work to accommodate proprietary agents.
At the same time, observability agents have become commoditized, with standards like OpenTelemetry emerging. These standards make it easy to ship data to various backends, removing the constraint of specific formats tied to specific backends and opening up a world of possibilities for the rest of the stack.
Collection
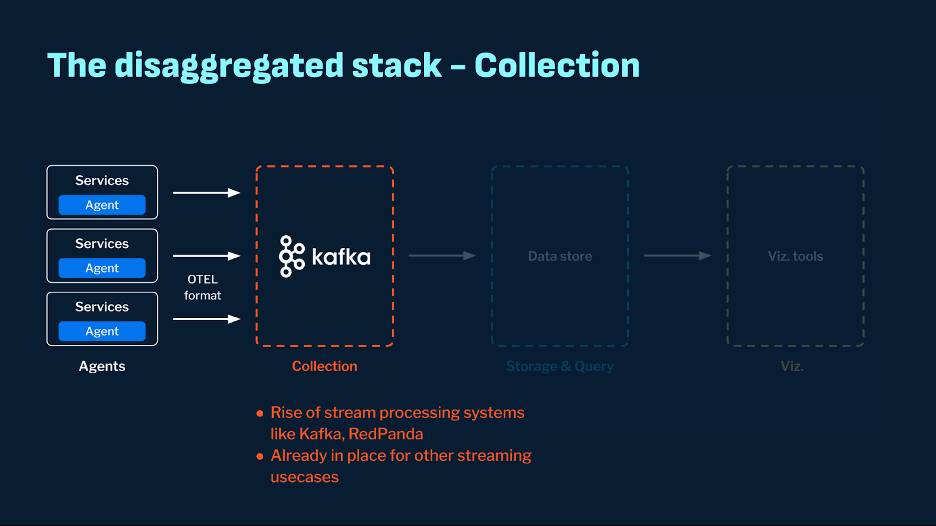
Vendor-specific collection systems need to be able to handle the following challenges
- Volume: Companies of all sizes generate a very high data volume for logs and metrics. Tens or hundreds of terabytes of data are expected to be generated daily.
- Variety: Metrics, logs, and traces come in various formats and may need special handling.
- Network Cost: These proprietary collection systems typically reside in a different cloud VPC, thus driving up egress costs.
In a disaggregated stack, streaming systems such as Kafka and RedPanda are popular choices for the collection layer and are often already deployed as a part of the data ecosystem. Several prominent organizations have tested these systems at scale for high-throughput, real-time ingestion use cases. For instance, Kafka has been known to reach a scale of 1 million+ events per second at organizations such as LinkedIn and Stripe. These systems are agnostic to agent formats and can easily interface with OTEL or other formats. They also have good connector ecosystems and native integrations with storage systems.
Storage and Query
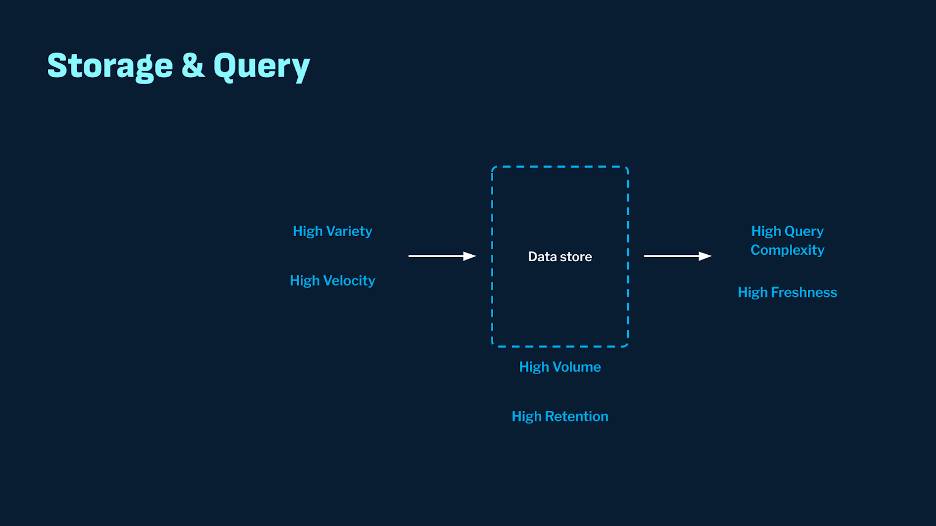
The storage and query layer is the most challenging part, significantly impacting the system’s cost, flexibility, and performance. One of the significant problems with the storage and query layer of present-day solutions is the lack of flexibility to use one’s data for other purposes. In an all-or-nothing solution, once one’s data is in the vendor’s stack, it’s essentially locked in. You can’t use the data stores to build additional applications on top of it.
Another aspect is the cost and performance at the o11y scale. The storage & query system must handle the extremely high volume of data at a very high velocity. The variety of data means you’ll see many more input formats, data types, and unstructured payloads with high cardinality dimensions. This variety makes ingestion into these systems complex, and the need for optimal storage formats, encoding, and indexing becomes high.
In case of a disaggregated stack, choosing the right storage system is extremely important. Here are some of the things to consider when making this choice.
Integration With Real-Time Sources
The system must integrate seamlessly with real-time streaming sources such as Kafka, RedPanda, and Kinesis. A pluggable architecture is crucial, allowing for the easy addition of custom features like decoders for specialized formats such as Prometheus or OTEL with minimal effort. This flexibility is particularly important for o11y data, as it requires support for a wide variety of data formats from different agents.
Ability To Store Metrics Data Efficiently
Here’s an example of a typical metrics event that contains a timestamp column representing the timestamp of the event in milliseconds granularity, a metric name and value column representing the metrics emitted by your system, and a labels column.
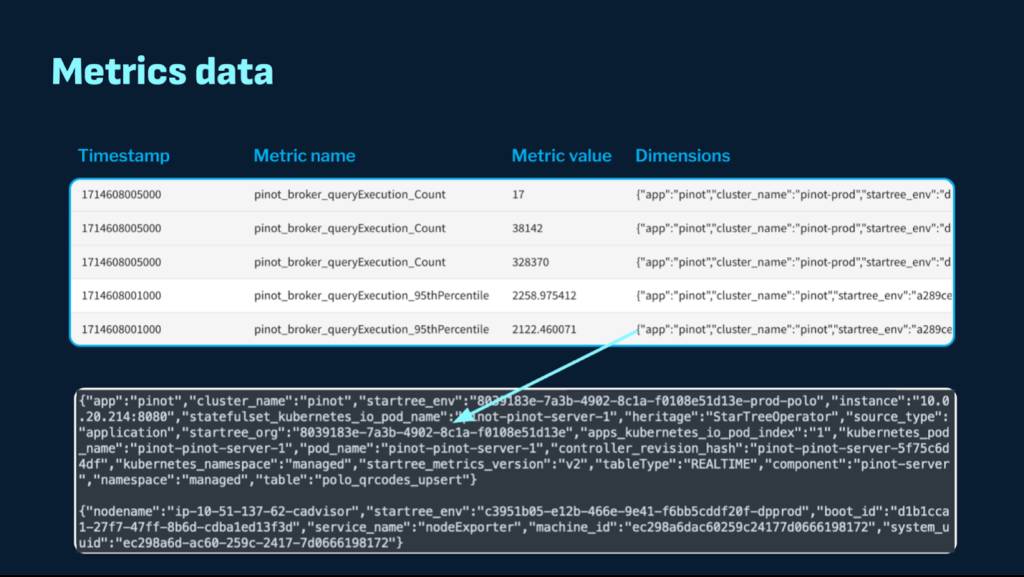
There are several challenges associated with such datasets:
- High cardinality columns: They need special handling like Gorilla encoding for efficient compression.
- Various Indexing techniques: Range index, Inverted or sorted index for efficient lookup and filtering of timestamps, high variability metric values and metric names.
- Advanced data layout: The ability to partition on frequently accessed columns to minimize work done during query processing (only process certain partitions).
- JSON column support: The “labels” column is typically represented as a JSON map containing a variety of dimension name-value pairs (eg: values for server IP, Kubernetes version, container ID and so on). Ingesting data as is will put the onus on query processing which then needs to do runtime JSON extraction. On the other hand — materializing all such keys at ingestion time is also challenging since the keys are dynamic and keep changing.
Existing technologies have some workaround to overcome these challenges. For instance, Prometheus treats each key-value pair as a unique time series which simplifies JSON handling but runs into scalability issues. In some systems, like DataDog, costs increase as more top-level dimensions are added from these labels. If you go with a key-value store, you’ll again face the perils of high combinatorial explosion and loss of freshness when keeping real-time data in sync. Therefore, it is crucial that the storage system you choose can handle such high cardinality, and also complex data types and payloads.
Ability To Store Logs Data Efficiently
A typical log event includes a timestamp and several top-level attributes such as thread name, log level, and class name, followed by a large unstructured text payload, which is the log line. For the timestamp and attributes, you need similar encoding and indexing features to those required for metrics data. The log message itself is completely unstructured text. Querying this unstructured text involves free-form text search queries, as well as filtering by other attributes and performing aggregations. Therefore, robust text indexing capabilities are essential to efficiently handle regex matching and free-form text search.

Storing entire log messages results in extremely high volumes of log data. Logs often require long-term retention due to compliance requirements or offline analysis and retrospection, leading to substantial storage demands (tens of terabytes per day) and significant costs. Practical compression algorithms are crucial. For instance, the Compressed Log Processor (CLP) developed by engineers at Uber is designed to encode unstructured log messages in a highly compressible format while retaining searchability. Widely adopted within Uber’s Pinot installations, CLP achieved a dramatic 169x compression factor on Spark logs compared to raw logs.
Another important feature for managing the high costs associated with large volumes of data is the ability to use multiple storage tiers, such as SSDs, HDDs, and cloud object stores. This tiering should not come at the expense of flexibility or increase operational burden. Ideally, the system should natively handle the complexity of tiering and data movement policies. This is particularly important for o11y data, which often needs to be retained for long periods even though queries beyond the most recent few days or weeks are infrequent. Utilizing more cost-effective storage for older data is crucial in managing these costs effectively.
Some systems, such as Loki, offer 100% persistence to object stores. Others, like Clickhouse and Elastic, provide multiple tiers but rely on techniques like lazy loading, which can incur significant performance penalties. Systems like Apache Pinot offer tiering and apply advanced techniques, including the ability to pin parts of the data (such as indexes) locally and employ block-level fetching with pipelining of fetch and execution, significantly enhancing performance.
Considerations of Trace Data
Now let’s talk about trace events. These events contain a call graph of spans and associated attributes for each span. Due to the semi-structured, nested nature of the payload, challenges similar to metrics data arise in storing these cost-effectively and querying them efficiently. Native support for ingesting and indexing these payloads efficiently is crucial.
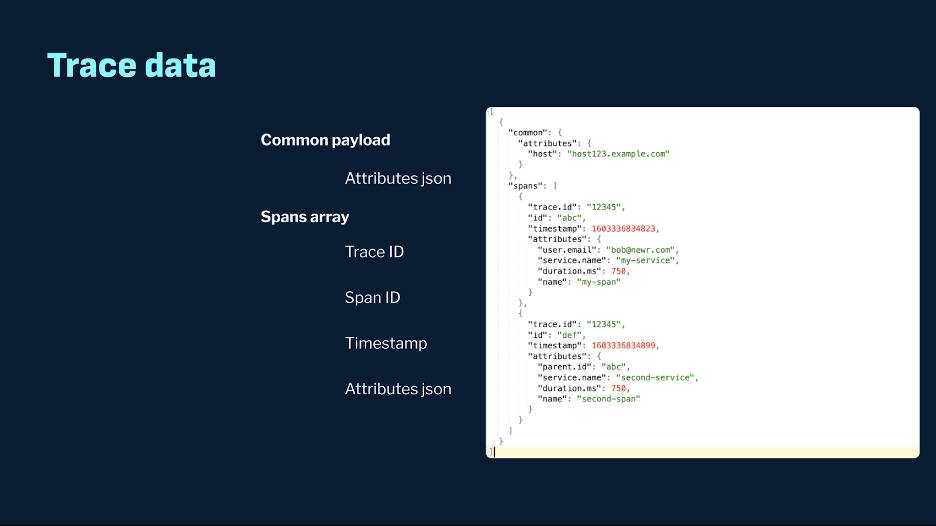
To summarize the challenges, we need a system that can handle petabytes of storage cost-effectively while managing long-term retention. It must ingest various formats at high velocity and serve the data with high freshness and low latency. The system should efficiently encode and store complex semi-structured data. Robust indexing is crucial, as a system that optimizes performance and minimizes workload will scale much more effectively.
Compared to all-in-one solutions, systems purpose-built for low-latency, high-throughput real-time analytics — such as Apache Pinot, Clickhouse, StarRocks, and Apache Druid — are better suited for storage and querying of o11y data (read more about the popular systems in this area here). These systems come with rich ingestion integrations from many real-time data sources, and the recipes have been proven to scale for use cases in different domains. Their columnar storage makes them more efficient in handling storage optimally, offering a variety of encoding and indexing techniques. Many provide good text search capabilities (e.g., Elastic Search is well known for free text search query capabilities). Apache Pinot and Clickhouse also offer native storage tiering capability.
Apache Pinot offers a blueprint for tackling every nuance of o11y, as depicted in the figure below. You can also view this tech talk on the o11y strategy in Apache Pinot.

Fig: Observability capabilities in Apache Pinot.
It also features a plugged architecture, enabling easy support for new formats, specialized data types, and advanced compression techniques. It has a solid indexing story and advanced ones like JSON indexing, enhancing its ability to handle JSON payloads efficiently. Real-world examples of successful implementations include Uber and Cisco, which have leveraged these niche systems to enhance their o11y solutions, demonstrating their effectiveness in managing high volumes of data with high performance and cost-efficiency.
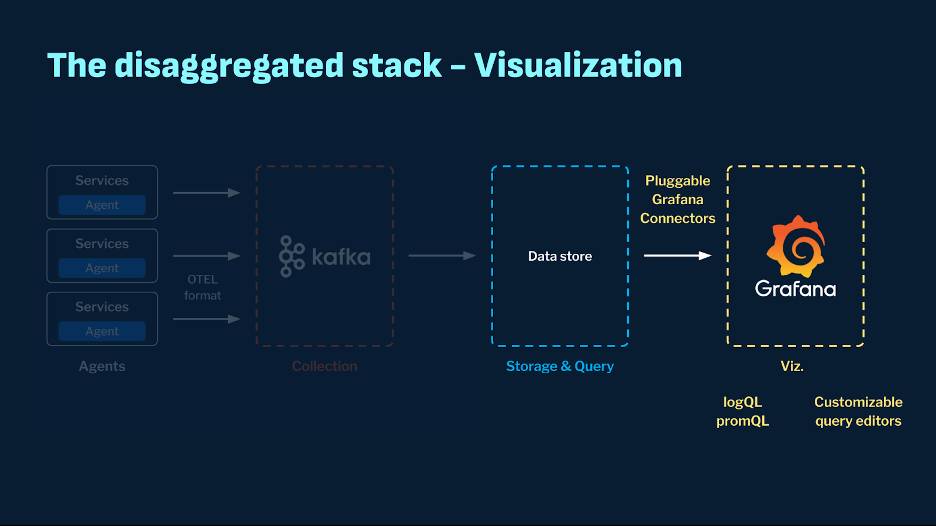
Integration With Visualization Tools
Tools like Grafana are becoming increasingly popular due to their ease of use and rich customization options, allowing users to build comprehensive dashboards. The available widgets range from time series, heatmaps, bar charts, gauges, etc. Additionally, Grafana supports the creation of full-blown applications with extensive custom integrations. It offers flexible, pluggable connectors for different backends, avoiding vendor lock-in. Building a plugin, whether as a whole connector or a panel, is straightforward. Popular storage systems like Clickhouse, Elastic, and Pinot have Grafana plugins. Grafana also supports query protocols like LogQL and PromQL, which are gaining popularity.
Another popular tool is Superset, known for its rich UI widgets and ease of use and customization. Superset integrates seamlessly with many popular databases, allows users to create and share dashboards quickly, and, similar to Grafana, offers extensive charting capabilities.
BYOC
Earlier, we saw that one reason vendor solutions are costly is the high data egress costs when transferring data from agents in your account to the rest of the stack in the vendor’s account. With vendors who support BYOC (Bring Your Own Cloud), this issue is eliminated. The agents and the rest of the stack remain within your account, ensuring that your data doesn’t leave your premises, thereby avoiding additional costs associated with data transfer.
Conclusion
Adopting a disaggregated stack for o11y in modern distributed architectures offers significant benefits in cost-effectiveness and reusability. By decoupling the various components of the o11y stack — such as agents, collection, storage, and visualization — enterprises can choose best-of-breed solutions tailored to specific needs. This approach enhances flexibility, allowing organizations to integrate specialized systems like Kafka, RedPanda, Clickhouse, Pinot, Grafana, and Superset, which have proven capabilities at scale.
The disaggregated model addresses the high costs associated with traditional all-or-nothing vendor solutions by eliminating data egress fees and leveraging more efficient storage solutions. Moreover, the flexibility to use different layers independently promotes reusability and data autonomy, preventing data lock-in and enabling better adaptability to changing requirements.
By embracing a disaggregated o11y stack, organizations can achieve greater agility, optimize performance, and significantly reduce costs while maintaining the ability to scale and adapt their o11y solutions to meet evolving business needs.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.