
包阅导读总结
1. 关键词:WebAssembly、Isolation、VMs、Scalability、Limitations
2. 总结:演讲者 Tal Garfinkel 介绍了 WebAssembly 作为隔离技术的特点及应用,包括在 Firefox 中的库沙盒、服务器无服务等领域,还对比了其与裸机的差异,提及了突破 Wasm 限制的研究,强调其在软件克服硬件限制方面的作用。
3. 主要内容:
– 演讲者背景:UC San Diego 研究科学家,曾在 VMware 工作多年,见证虚拟化影响。
– 演讲内容概述:
– 介绍 WebAssembly 作为隔离技术及其应用。
– 阐述研究工作,即如何突破 Wasm 限制。
– 隔离技术基础:
– 硬件隔离:基于页表和保护环,速度快但粒度粗、通信慢、启动慢、资源占用大。
– 编程语言内隔离:语言相关,有运行时开销,粒度细、启动快、资源占用小。
– WebAssembly 介绍:
– 是平台独立的 IR,可 AOT 或 JIT,在单个地址空间内隔离组件。
– 从网页标准发展,如今在边缘被采用。
– WebAssembly 的应用:
– 库沙盒:Firefox 用于隔离有缺陷的库。
– 服务器无服务:边缘平台用于超大规模扩展。
– 插件和可扩展性:如服务网格、Shopify 等。
– IoT 领域:屏蔽不同设备细节。
– WebAssembly 的限制与裸机对比:存在性能开销和扩展限制,但仍优于传统硬件解决方案。
思维导图: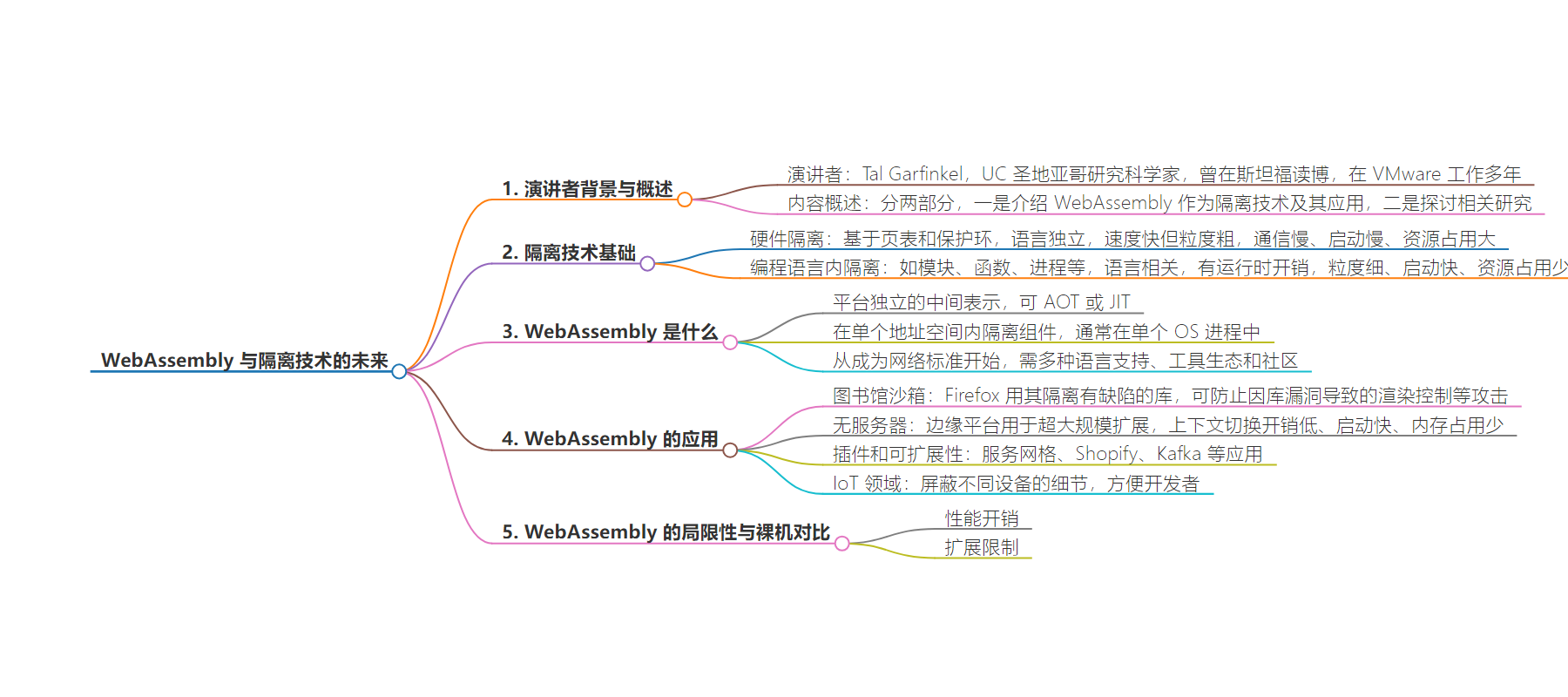
文章来源:infoq.com
作者:Tal Garfinkel
发布时间:2024/6/21 0:00
语言:英文
总字数:6571字
预计阅读时间:27分钟
评分:85分
标签:webassembly 隔离,开发,编程语言,QCon San Francisco 2023,系统编程
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Transcript
Garfinkel: I’m Tal Garfinkel. I’m a research scientist at UC San Diego. Did my PhD at Stanford. During and after, I spent about a decade at VMware, from the pretty early days when we’re just a couple hundred people, till it was about 26,000 people. My formative years were spent seeing the impact that virtualization had on the industry, from the point at which it was laughable that everything would be running in a virtual machine and VMs slowed things down by like 30%, to the point where it was a given that, of course, you’re going to be running in a VM.
Overview
I’m going to be talking about a few different things. I’ve tried to break this into two parts. First, I’m going to talk about, what is WebAssembly as an isolation technology, and how is it being used? What I was hoping for here is that even if you’re not into the gory details of Wasm or you haven’t used it before, you’re all come away with some idea, this is where Wasm might be useful in a project for me, for a security project, for some extensibility piece, for some serverless piece. Someplace where like, this fits, because Wasm is this distinct point in the design space. It’s not containers. It’s not VMs. It’s this other thing that you can use. The second part, I’m going to talk about the research that I’ve been working on recently. This is, how do we push beyond Wasm’s limitations. Wasm is doing something fundamentally unnatural. We’re taking software and we’re using it to overcome the limitations of hardware. Again, this is close to my heart, because of my background in virtualization. If you know the history of virtual machines, VMware when it started out was virtualizing the x86, which was something you could not do. The x86 as an architecture is not virtualizable. Instead, what VMware did was use a combination of low-level hardware features and binary translation to make the x86 virtualizable. This is how we were able to get virtual machines. For the first five years or more, there was no support from the hardware, and this was the only way to do it. Eventually, hardware caught up, and we got to this world where writing a virtual machine monitor is a project for a graduate student. I see this nice parallel between Wasm, where, again, we’re using the compiler and software to overcome the limitations of hardware.
Isolation: Fundamental to How We Organize Hardware
Isolation is fundamental to how we organize systems. We have two different technologies to do this. We have hardware-based isolation which relies on page tables and protection rings. This is what processes, VMs, and containers are built on. It’s language independent, bare metal speed. Unfortunately, it’s designed to be relatively coarse grain. Communication between different protection domains is quite slow. Starting one of these things up is quite slow. It has a relatively large resource footprint. Fundamentally, hardware-based isolation today is not about doing fine-grained things. The other place where we see isolation, we take it for granted, I think often is within programming languages. This could be modules, functions, or in programming languages like Erlang and OTP, and processes, we have soft processes. These are language independent and they impose runtime overheads. They can be very fine grained, where we can start and stop these things in nanoseconds. They have a very small footprint. They really match how we think about things. WebAssembly is based on a technology called software-based fault isolation. Software-based fault isolation is an idea that goes back to the ’90s. This was a few years before I got to Cal as an undergrad. This was in the heyday of extensible operating systems. People were thinking about microkernels. People were thinking about writing kernels in safe languages. There was this, how do we get more flexibility into our systems? One of the ideas that came out of this was instead of using hardware to enforce protection, what if we use the compiler? SFI exists in this liminal space. It is relatively language neutral because it has this model of memory that looks very much like the underlying machine, but it lets us get these nice properties that we usually get from software-based isolation. Orders of magnitude faster context switches than we’re going to get from VMs or containers. Orders of magnitude faster startup time, small resource footprints, massive scalability. This is what makes companies like Cloudflare and Fastly able to do what they do with this hyperscaling that they do with edge based serverless.
What is WebAssembly (Wasm)?
What is WebAssembly? It’s a platform independent IR, that you can AOT or JIT. It isolates components within a single address space, generally like within a single OS process. How is this possible? It takes a lot of work. It started out as a web standard. You have to get all these various languages to target this new VM. You have to grow the ecosystem of tools to support it, and then build a community around it. This is where we are today. We’re about six years into this dream from when this first emerged, and all the major browsers supported it. Now it’s seeing adoption on the edge. A lot of folks are starting to use it in different applications that I’m going to talk about next.
How is Wasm Being Used?
How is Wasm being used? The first example I’m going to talk about, which is not the biggest example, but it’s the one that’s close to my heart, because it’s the stuff that we’ve done is library sandboxing. Firefox uses WebAssembly to isolate buggy libraries. This has been a close to, I think, like five-year project now, from talking to our friends at Mozilla, and recognizing there’s this problem. When you’re using your browser, when you’re going to a website, your browser is rendering all sorts of different content, media, XML, audio, all sorts of different formats. There are dozens of libraries to do this. They use these libraries for spell checking, tons of third-party code, dependencies. These are all written in C. When any one of these has a vulnerability, that can compromise your render. For example, let’s say I send you an image file, that particular library has a buffer overflow in it. I pop that library, now I have control of your render, and I have control of that application. I have control of your email client. I may also have control of everything else in that site, because we do have site isolation in browsers. Maybe I’ve got mail.google.com, but maybe I also have pay.google.com for you. Maybe I also have cloud.google.com for you. It’s a very serious class of attacks. What we found is that it’s actually not easy. We had to build some tooling and infrastructure to enable this, but that with the appropriate tools, we could start sandboxing these libraries. This has been shipping in Firefox since 2020. Today, if you’re using Firefox, a bunch of those libraries are actually sandboxed. This is not particular to Firefox. Every application out there depends on C and C++ libraries. This is where most of your bugs live is in dated code. A majority of our bugs are in these C and C++ libraries. Most of the safe languages that you use rely on these libraries. You may be like, I don’t have to care about this, I’m writing in Rust, or Java, or Python, whatever language you depend on, you probably have a large number of dependencies that are actually just C libraries that have been wrapped by these languages.
What we’re doing now as part of our research is working on, we built these tools for C++, for Firefox, but how do we get this out there and actually into the ecosystem? How do we build this as something that you can opt into, like when you pull a crate on cargo, or when you pull an npm on Node to say, I want to opt into the sandbox version of this library. Again, there’s lots of other examples of how you can use Wasm. A big one of these is serverless. Today, again, edge platforms use this for hyperscaling. This allows them. Every time these guys get a packet, they spin up a new instance, because they can get low context switch overheads where they can run many of these things concurrently without paying the context switch tax. They can start these up in microseconds, and they can use orders of magnitude less memory than they might end up if they’re using a VM. Again, plugins and extensibility. This is a huge area. If you’re using a service mesh, like Envoy and Istio. Shopify has used this for running user code server-side, stored procedures, that way of using this, and Kafka. There are all sorts of places where you’re like, I would like some safe extensibility. I want to put some code close to my data path. Wasm is a great tool for that. Another place that Wasm is really catching on is in the IoT space. Because you have this whole diversity of different devices, and you have your developers that are writing your application code, and you don’t want them to have to worry about all the fancy details of the different compilers, different devices. Wasm’s platform independence is being used as this layer to shield people who are writing the application logic from the particulars of the different IoT devices. I think this is going to be very big, as we see more intelligence embedded in different devices, this model where, whether it’s Microsoft or Amazon or someone else is dealing with software updates, and distribution, all these things for you, and you just build your business logic in Wasm. I think that this is going to be a really important model for using Wasm.
What Are Wasm’s Limitations vs. Bare Metal?
This sounds great. You’ve got this really lightweight isolation technology. How does this compare to running on bare metal? The reality today is there’s a lot of limitations. One of these is performance overheads. Another of these is scaling. Again, out the gate, Wasm is still better at scaling than your traditional hardware solutions. It has some limitations as well. Spectre safety is a big deal. Who knows why the little ghost is carrying a stick? It’s a branch. Finally, compatibility is an issue. Essentially, Wasm is paravirtualization. Back in the day before we had virtualization hardware, it was like, let’s change the operating system. This is what Wasm is doing, but it’s like, let’s change the compiler to output this new IR. Some of that is like, we’re dealing with, and some of that’s fundamental. Just quick review before I get into this. Who all remembers undergrad operating system? Does everybody remember page tables, and TLBs? Page tables are incredibly powerful. They’re like this amazing thing. You can use them for compression. You can use them for live migration. You can use them for overcommit. It’s a really powerful abstraction. Because as we know, in computer science, we can solve any problem with a level of indirection. This is what page tables are. The problem is that our TLB is a bottleneck. It is a bottleneck in terms of how many things we can shove through there, because if we have too much concurrency, it becomes a point of contention. If we want to modify our TLB quickly and dynamically, things get weird.
Something you probably don’t see every day, but again, you probably read about in undergrad. Who all remembers segmentation in x86-32? The other choice we generally have over architecting systems is segmentation. There are other forms of memory management out there, but this is a big candidate. Segmentation works differently. It is one of the earliest forms of memory management. Here we have this notion of base and bounds. It doesn’t have the issues of the TLB, it has its own limitations. Our model is, when we do an address lookup, we do it usually relative to the start of a segment, and this segment has permissions and whatnot. It’s an alternative scheme. Why am I talking about this? A lot of the limitations that VMs and containers have that are fundamental have to do with the fact that you’re dependent on page tables. This limits scale and it limits dynamism. If you want to create these things, if you want to destroy them, if you want to resize them, you will shoot down your TLB. This is expensive. Again, if you end up with many of these things, you wind up contending for your TLB. I review papers and sometimes I get these papers and they’re like, we have address space identifiers, and so we can tag things in our TLB. This is how many of them are. I’m like, the number you’re telling me is actually much larger than your TLB physically is, so you’re going to be flushing your TLB. Again, TLBs are incredibly powerful but they do have these inherent limitations. The other limitation are context switches. Part of this is protection ring crossings, but protection ring crossings are actually not that bad. Maybe they’re in the tens of nanoseconds. The scheduler is pretty expensive. If you have to buy into the OS scheduler, that’s going to cost you. Doing a heavy weight save and restore is going to cost you. There’s also going to be cache pollution. There’s all these fancy things if you have to go back and forth between the operating system, when you want to switch between protection domains, it’s going to get way more expensive than if you can just basically do a function call, which is what’s happening in something like Wasm. I make these comparisons to lambda sometimes. You can spin up a Wasm instance in a couple microseconds. With a lambda, you’re talking like 100 milliseconds. Then there’s OS overheads, there’s language runtime overheads, whatever funny thing you’re doing in the virtualization layer. Recently Microsoft has Hyperlight, their very lighter hypervisor that they’re going to use to run Wasm in. Their startup times they’re saying are like 100 microsecond scale, which is still a couple orders of magnitude off of what we can get with just straight up Wasm.
What is the alternative? The alternative is a software-based fault isolation. To me, software-based fault isolation is poor man segmentation. Where like, we don’t have hardware segmentation, so we’re going to do this in software. How do you do this in software? Two ways. The simplest way that you could think of to do this is just add bounds checks to every load, restore. The problem with this is that this is expensive. You’re adding high cache pressure. You’re adding the cost of executing those checks. You’re tuning up general purpose registers to keep around those bounds. You’re easily looking at a 40% to 100% slowdown on real benchmarks. Of course, you’re not Spectre safe. That’s mostly not what people do. If you look at a production Wasm implementation, if you look at what’s happening in your browser, if you look what’s happening server side, what people are doing is they break the address space up into guard regions and address spaces. In Wasm, I’m doing 32-bit memories in a 64-bit address space. I can break this up into these 8-Gig chunks. The first 4 Gigs is my address space, the second 4 Gigs is a guard region. When I’m doing addressing in Wasm, so if I’m doing 32-bit unsigned loads, I take that, I add that to the beginning of my memory base address. Now I’ve got a 33-bit value, 8 Gigs. It’s either going to land in my address space, or it’s going to land in my guard region. What did this do for me? This lets me get rid of my bounds checks. I still have to do that base addition. I’m still adding an instruction to every load, restore. Every load, restore is going to be base addition, and then the actual load, restore. It helps a lot. It helps like getting us down to maybe 15%, 20% range. It’s a big win. This also has limitations that it brings, though, unfortunately. I’m still involved with the MMU, have not escaped first setting up and tearing down memory.
There are other limitations I got. One of these is the guard regions, they scale poorly. On x86 in user space, I’ve got 2 to the 47 address space. Each of these 8-Gig regions is 2 to the 33. I do my math, I’ve got 2 to the 14, or about 16,000 instances that I can put in here. I can arrange things a little more cleverly, and get about 20,000 instances. This sounds great. The problem is that when I’m using this in a serverless context, again, I’m spinning up one of these every time I get a number of request. Each of them is often running under a millisecond because I don’t have all those funny overheads with lambda anymore. It’s just running my code. Filling up an address space is pretty easy. I fill up one process address space, where I could start another process. Then I’ve got context switch overheads, then I’ve got IPC overheads when I talk to them, if I want to chain functions. I’m getting back into the space that I was trying to get away from. The other thing is the component model. A really great thing about WebAssembly is the component model. It’s this new thing, where instead of running your application in one address space, you’ll be running your application in multiple address spaces so you can have components. You can have your dependencies broken into separate, isolated things. It could be one library. It could be multiple libraries. We’re talking about potentially an order of magnitude or more increase in the number of address spaces per application. We need to do something about the scaling limit. The other problem with this guard region scheme, we can’t use it with 64-bit memories. We’re back to conditional checks. We can’t use it with older processors, we can only play it under these particular conditions. Finally, these tricks that we’re playing still have overheads.
The final limitation, again, is compatibility. This is a big one today, if you’re going to be using Wasm for real projects. I can talk about what you can do now, what you’re going to be able to do in a year, what you can really do in two years. Because you’re presenting this interface to programming languages, to compilers for them to target, so you need to provide a rich enough interface to get them what they need. You also need to provide a rich enough interface that they can exploit all the functionality in the hardware. Some of this is getting better standards. Some of this is just fundamental to how Wasm works, that we’re not going to overcome. For example, I don’t think dynamic code generation is anywhere in the near future. You’re never going to be able to do direct system calls, although a lot of this stuff can be supported by WASI. You’re never going to get your platform specific assembly to magically run in Wasm. Although we have some tricks for dealing with intrinsics.
Doing Better with Current Hardware (Segue and ColorGuard)
Two things. How do we do better with current hardware? Then, how can we extend hardware to overcome these limitations? By extend hardware to overcome these limitations, I mean the limitations that Wasm has, but all the way to, how do we get these properties that Wasm has? Super-fast startup, teardown communication, like all this goodness, without even having to get into Wasm, just for native binaries, for whatever code you run. First, optimizations. I have two things that I’m going to talk about that we’re doing today, using hardware in dirty ways to make things go faster. First one is an optimization called Segue. It’s super simple. It takes about 25% of Wasm’s total tax away. The second one is one called ColorGuard. This addresses that scalability problem I mentioned. It lets you go from the 20k instance max to about a quarter of a million. Back to segmentation. Segmentation was largely removed when we moved to x86-64. Intel was off doing Itanium. AMD was like, never mind, here’s the new standard. As part of that, they dropped segmentation. I’m sure it simplified some things at the microarchitecture level. There were good reasons for doing this. What we’re left with was segment relative addressing, and two segment registers. The rest of our segment registers now don’t do anything. You can still use ES, CS, DS, but they just are base to zero. We still use these segment registers. If you’re using thread-local storage, you’re addressing things using segment relative addressing with one of these registers. It’s going to be FS in Linux, and I believe it’s going to be GS in Windows.
As it turns out, we can use this amazing register for other things. You can actually use both of these for other things. A Wasm runtime, you know when you’re going to be handing control back to something that’s going to be using thread-local storage. The trick is we just take that base addition that we’re doing. With guard regions, we do a base addition, and then we do a load, restore. We move that heap based into a segment register. Then we just do segment relative addressing. One instruction became two. One general purpose register you were burning, you can just use a segment register you weren’t using anyway. You’re getting rid of instruction cache pressure. You can see, our extra instruction goes away, frees up an extra register, frees up some extra flexibility for the compiler. As it turns out, we get this big code size reduction, which was a pleasant surprise to us. We get some nice performance reductions on spec. On specific workloads, we get even bigger jumps that I’ll mention a little bit later. This has actually landed in WAMR, which is Intel’s Wasm compiler and runtime, just recently. I flagged that thing, reduces compilation time of JIT and AOT. I have no idea why it makes it faster. It’s like one of these things when people deploy it, it’s like, “That was great. I didn’t even know we were going to get that.”
The other trick that we came up with is called ColorGuard. ColorGuard takes advantage of a capability on Intel and AMD processors, called memory protection keys. This has been in Intel processors for quite a while and in AMD processors since EPYC Milan. If you’re on older AMD hardware, you might be a little bit sad, but this is relatively widespread. The way that this works is, for every page, you associate a 4-bit tag. We usually think about those tags in terms of colors. Then each core has a tag register. If the color in the register matches the color on that page, then you’re allowed to access it. If it doesn’t match, then you’re not allowed to access it. We have this new cool production mechanism. What I can do with this mechanism is I can eliminate that waste that I had. Going back to that picture that we had in our mind, we have 4-Gig address space, and a 4-Gig guard region. Let’s say we take that 8-Gig region and we break it into colors, then we say 500 Megs is going to be red, the next 500 is yellow, next 500 is blue, next 500 is green, till we fill that up. Now what we can do, is we’re using the address spaces of our other VMs as our guard regions, and we want to context switch, we just switch the color of that register. All of a sudden, we’ve eliminated that waste. Now, again, we’ve got this big win, and we can run order of 12x more instances, in the same amount of space.
Extending Hardware (Hardware Assisted Fault Isolation)
This is fun. This does not address all the performance limitations. It doesn’t even address all the scaling limitations, even with that cool trick, because again, we’re restricted to our 15 colors and our 8 Gigs. It’s nice. How do we go further? After working with this stuff for a few years, and beating our head against the limitations of Wasm, we’re like, we just really want hardware support. What do we want from that? We want three things. Number one, we want a really simple microarchitecture. The reason for this is that it’s really hard to get changes into real processors. There you’ve got a very limited budget in terms of gates, if you’re close to the critical path. We worked with folks at Intel, and we went back and forth a lot in terms of like, can we have this? They’re like, no. We’re like, ok, let’s figure out how to work around that. Another thing we wanted is minimal OS changes. It is really hard to get Linux to do things. It is really hard to get Windows to do things. For example, MDK is not supported in Windows, and I don’t think it’s ever going to be. There are lots of funny, silly things, if you like hang on, on a kernel mailing list, you’ll be like, that is really small. I’m shocked that it is taking this long to get supported. Sort of like, we don’t want to be involved with that. The third thing we want to do is this ability to support both Wasm and other sorts of software-based fault isolation against the other sorts of compiler enforced isolation. For example, V8 now has its own custom way of doing this because the V8 JIT is an area that has lots of bugs. Of course, we want to be able to support unmodified native binaries as well, so kind of the whole spectrum of these things.
Our solution to this is an extension we call hardware-assisted fault isolation. HFI is a user space ISA extension that gives us a few key primitives.
One, it gives us bases and bounds. This ability to say, here’s a set of data regions, or here’s a set of virtual address ranges that I can grant the sandbox access to. I set up my mapping of virtual address regions. I say, I’m going to enter the sandbox. Once I’m in the sandbox, that’s the only memory we can access. I execute my guest code, my sandbox code, and then when it calls exit, it hands control back to our runtime. There’s more details, but that’s the essential idea. It’s dead simple. What HFI provides for us is super-fast isolation. Those bounds checks are executed in parallel with your TLB lookups. They add no overhead to native code. It is what you expect with your page table as well. We get very fast system call interposition. This gives us some forms of Spectre safety. It gives us unlimited scaling. It doesn’t have any of those constraints that we had before. We have a small amount of on-chip state, we context switch that state, and we’re done. We can set up teardown and resize sandboxes very quickly. This is just a change of registers. Finally, of course, this is compatible with existing code, we don’t have to get into the whole huge game that we’re playing with Wasm.
One challenge, so this sounds like a nice idea. You’re like, great, I want to do upper and lower bounds check. I’m going to implement regions as just segmentation. I’m just going to grab 264-bit comparators. I’m going to do an upper bounds check. I’m going to do a lower bounds check. Amazing. We went to an architect and told them, we’re like, this is what we’re going to do. You kind of play kidding, they take away your lollipop and send you home. We’ve got a limited gate count, we cannot slow down existing pipeline stages, because that’ll slow down everything. We can’t put complex circuits in there. We’re right on the data path. This has been described as the Manhattan of chip real estate. How do we do these checks in a way that requires very little silicon? Our answer to this is that you specialize regions to a few different types. We have two different types of regions. Again, going back to the world of x86 segmentation, remember, we used to have segments that apply to all memory accesses, and segments that apply where you use segment relative addressing. Regions are the same way. We have explicit regions where you do relative addressing. The nice thing about this is that we can do this with 132-bit compare, because it’s always like one sided. I get all the expressiveness with my x86 mov instruction, except I’m going to constrain it to say that my index has to be positive. Doing that, I can just do a one-sided comparison. I can do this with very little hardware. This only works, though, if I’m doing relative addressing. The other thing I want is to be able to just apply this to everything. How I’m going to do that is I’m going to give up some granularity. With my explicit regions, I can be like, I have a large region and a small region. With my small regions, where I can address up to 4 Gigs at a time, I’m going to have byte granular addressing. This is really important for doing sandboxing. When we send logs libraries in Firefox, we do not want to change them, somebody else maintains that code. We want to be able to say this is a data structure, here is where it lives in memory. I’m going to map that into my sandbox without changing code for that. I have to have byte granular addressing for larger things. Again, with Wasm, I’m doing things relative to the base of linear memory. Actually, I want this because with Wasm, I can have many linear memories. I’m going to use my region relative addressing for that, but there I only need to grow it in 64k chunks, because I’m growing my heap. Then with implicit regions, I can use this for code, I can use this for static data, I can use this for stack. Because I’m using masking, I have to be power of two aligned and sized. Often, I can deal with that extra slop. What I get for that is very cheap implementation.
Another thing that I really wanted early on with this, was system call interposition. The reason for this, it makes the things a lot simpler. I’ve written probably six different systems that do system call interposition. I’ve done library interposition. I’ve written a new process tracing mechanism for Linux. I’ve used Linux ptrace. All of those experiences were terrible. Modifying the kernel is terrible. Using the existing thing is really expensive and slow. Library interposition is just really fragile. When you can change the processor, you can do something really simple. You can either just change microcode or implement this with conditional logic. You can just say, every time I see a privilege instruction, syscall, sysenter, int 0x80, whatever, turn that into a jump. Just return control back to my runtime. Another thing that we get from this that’s really nice is that we get Spectre safe bounds checks. When we’re doing bounds checks in software, our processor does not know about this, so we’ll happily speculate them past them. Now that we’re doing things in hardware, we can architect this. Whether a memory access is speculative or non-speculative, a bounds check will get enforced. That means we’re never going to speculatively access something outside the bounds of our sandbox. We’ve got our sandbox memory region. Even if I mistrain the processor, it will not speculate beyond the bounds that are being enforced by HFI. This does not solve all of Spectre. There is no easy solution to Spectre. Out of order execution is deeply ingrained in how we build processors. This relies on prediction structures, the PHT, the RSB, the BTB, things like, is this branch going to execute? When is this branch going to execute? Branch prediction is key to how you go fast. You need to keep on going, keep on fetching into your pipeline. We can’t just go and flush those structures. We can’t solve this. Nobody else seems to have a great solution either.
We’ve got these primitives, they work for Wasm and other SFI workloads, and for native binaries. We just use them differently in these different scenarios. Two different uses models, but essentially the same primitives. How does it work in terms of performance? In simulation and in emulation, and in emulation we validate with our simulation. We get a huge speedup over doing bounds checks, which is great for 64-bit memories. Over guard regions, we get a little bit of a speedup, which is nice. We also get all these nice properties in terms of scaling, Spectre resistance, small address spaces. On some workloads, reducing register pressure and high cache pressure, and all those good things I was talking about before. Get some really big wins, like here with image rendering in Firefox.
Questions and Answers
Participant 1: You talk about the lightweightness context switching is, and switching easy. The examples you have, like sandboxing in Firefox, that’s a highly collaborative workflow. You’re going to call a function anyway. You sort of know how much [inaudible 00:37:46]. Essentially, you’re just really estimating them. Is there a scenario where you will have all of like different applications that potentially some are malfunctioning? Is there a need for some sort of a scheduler? How sophisticated does the scheduling need to be? Because in a real kernel, straight away, it will enforce certain kind of resource isolation, if the processes and the order can be interrupted, so things like that. Is this a concern for Wasm as well?
Garfinkel: This is an area that I’m actively working on and interested in. It gets into like, how does user space thread scheduling work? How does concurrency work? Wasm, the core mechanism is just like, it gives you address spaces, it gives you isolation. Then you can put that into the context where you have concurrency, but that’s not part of the standard. The way that most folks do this today, like Fastly, or other folks, is they’re running their Wasm runtime, and then Tokio is running underneath. They’re using Tokio underneath to multiplex this thing. The Wasm runtime will have its own preemption mechanism built in. There are performance challenges associated with that, which is something I’m actively working on.
Participant 2: I wanted to ask about your thoughts on the recent WASIX runtime and what that might mean for multi-threaded applications of Wasm, for being [inaudible 00:39:40]?
Garfinkel: There’s two aspects of threading support. One is like, how do you do atomics and things like that? That’s the Wasm thread standard. It’s pretty far along. The other thing is, how do you create threads? The challenge around that has been, that there’s a difference between, how do you do this in browsers and how do you do this on the host side? Browsers are like, we have web workers. All of us who are more focused on the non-web case, we’re like, that’s great for you, but we need some way to create threads. What’s happened recently is there’s this WASI threads proposal, which is out, and it’s supported now in Wasmtime, probably in some other places too. WAMR has had its own ad hoc support for threads for a while. There are things that I don’t love about the WASI threads proposal, because you actually create a new instance per thread. It really lit a fire under people’s asses to solve the problems we needed to solve to get the right threads proposal. This has to do with how browsers do threads. Because a Wasm context involves not just the linear memory, but also certain tables. You can just say, this is what I can safely share, this is what I cannot safely share. The standard has to make its way along. Threading support is coming along. WASI threads is something that you can use today. If you have a use case where you need threads, I think it’s doable. You’re not totally unsupported. This is a good thing about the ecosystem, there’s the parts where you’re right on the path. There’s the part where it’s a little bit rocky, but you’ll be fine. You’ll get the support you need if you’re doing a real application, and there’s like off in the weeds.
Participant 3: The little examples where the Apple silicon was in the menu of slides. Was there any specific differences?
Garfinkel: In terms of the optimizations?
Participant 3: The general idea was for simplicity, but [inaudible 00:42:21].
Garfinkel: Arm doesn’t have segmentation. That’s not something we can use. Armv9 will have two forms of memory tagging. Armv9 will have something called permission overlays, which is kind of like MPK but a little bit better because it gives us Exe permissions as well. It’s a very cool primitive. It will also have something called memory tagging extensions, where we can tag things at collections of byte granularity, so even finer granularity. We think that we can use both of those to pull off this trick. We haven’t written the code in the paper yet. There is no Armv9 hardware out there, except for I think in mobile phones right now. I think the third-generation Ampere stuff will have it.
Participant 3: Someone wants to start dipping toe, and start working with Wasm, what would you suggest? Where do you go? What tool?
Garfinkel: There’s two tool chains that I think are really solid, and then the third one that we work on, that we use for Firefox, which actually is good for specific things. Wasmtime is super well supported, and I think rock solid from a security standpoint. That’s what Fastly builds on. That’s what a lot of folks build on. I would grab that. There’s WASI Clang for doing C and C++ stuff. Rust has really first-class support. It depends on your language. You need compiler support. You compile whatever your code is to Wasm and then compile your Wasm to your local binary, if you’re AOTing, or you can do your JIT thing for whatever reason you want to do that. I think it’s always good if you have a need ready, you have a project, like something that is cheering on you that you’re like, I need to solve this thing. There’s Bytecode Alliance. Most of the community is on Zulip. You can ask core technology questions there. It’s a pretty tight and pretty supportive community, kind of like the community around various programming languages. If you have an application, I think you’ll definitely find the support that you need around that. If you’re interested in the sandboxing stuff, like sandboxing native code, you should talk to us.
See more presentations with transcripts