
包阅导读总结
1.
– `Figma`、`ECS`、`Kubernetes`、`Cost Savings`、`Migration`
2.
Figma 在不到 12 个月内将其计算平台从 ECS 迁移到 Kubernetes,以利用 CNCF 生态系统、降低成本、改善开发者体验和增强弹性,迁移过程中采取了一些策略确保成功。
3.
– Figma 的计算平台迁移
– 从 AWS ECS 迁移到 Kubernetes(EKS)
– 原因包括利用 CNCF 生态、节约成本、改善开发者体验和增强弹性
– 早期使用 ECS 但遇到限制
– 迁移过程与策略
– 确定迁移范围,最小化服务变更
– 实现特定改进,如简化资源定义等
– 利用 Karpenter 进行节点自动缩放优化成本
– 迁移的保障措施
– 组建团队推动迁移
– 进行负载测试
– 采用增量切换机制
– 解决服务一致性和维护问题
– 迁移结果与后续
– 初始迁移少于 12 个月
– 迁移核心服务后开展后续活动,简化开发者工具
思维导图: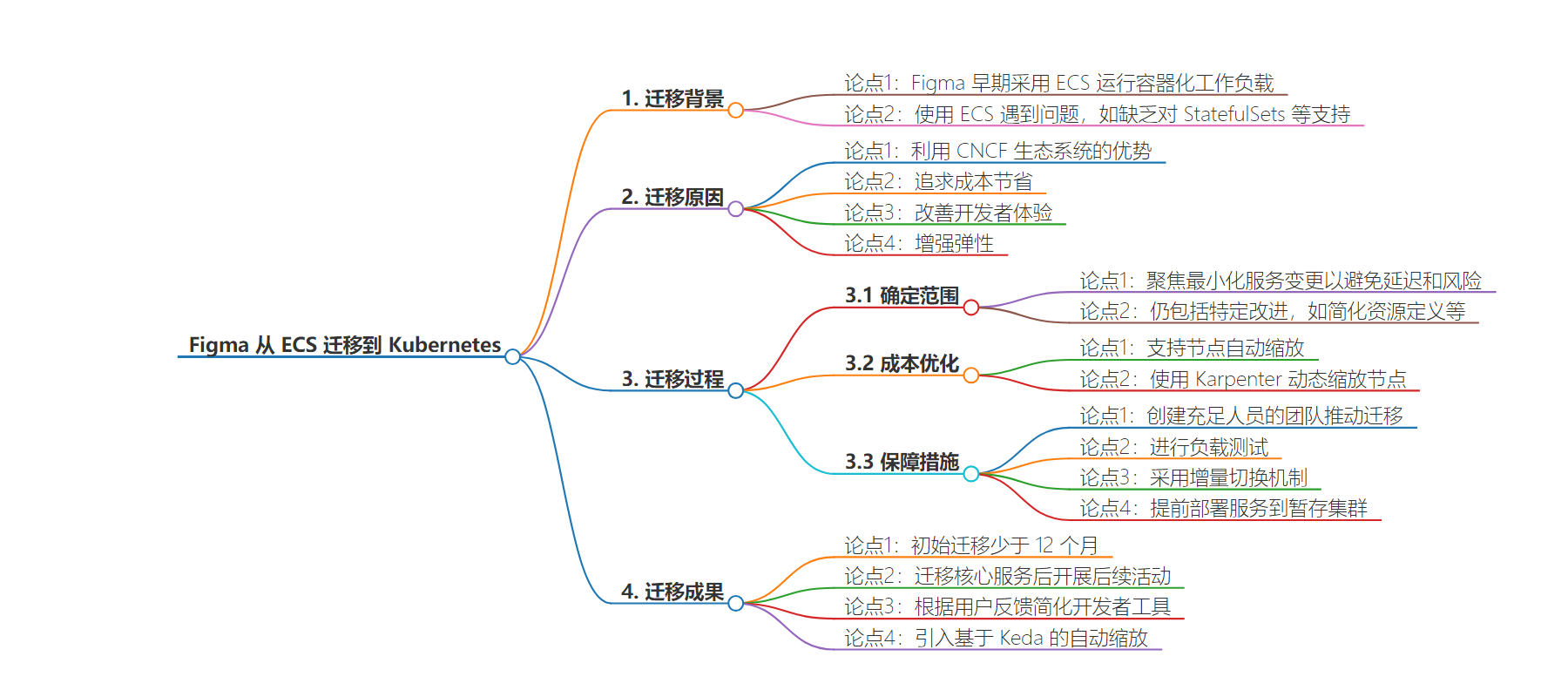
文章来源:infoq.com
作者:Rafal Gancarz
发布时间:2024/9/2 0:00
语言:英文
总字数:515字
预计阅读时间:3分钟
评分:87分
标签:Kubernetes,AWS ECS,CNCF,成本优化,开发者体验
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Figma migrated its compute platform from AWS ECS to Kubernetes (EKS) in less than 12 months with minimal customer impact. The company decided to adopt Kubernetes to run its containerized workloads primarily to take advantage of the large ecosystem supported by the CNCF. Additionally, the move was dictated by pursuing cost savings, improved developer experience, and increased resiliency.
Figma moved to run application services in containers and adopted Elastic Container Service (ECS) as its container orchestration platform by early 2023. Using ECS allowed the company to quickly roll out containerized workloads, but since then, engineers have run into problems with certain limitations of using ECS, mainly the lack of support for StatefulSets, Helm charts, or the ability to easily run OSS software like Temporal.
Moreover, the company recognized it was missing out on the wide range of capabilities offered for Kubernetes within the CNCF community, including advanced autoscaling using Keda or Karpenter, service mesh using Istio/Envoy, and numerous other tools and features. The organization also considered the substantial engineering effort required to customize ECS for its needs and the availability of engineers experienced with Kubernetes on the job market.
/filters:no_upscale()/news/2024/09/figma-ecs-kubernetes-eks/en/resources/1figma-ecs-k8s-1725279367947.jpeg)
Kubernetes Migration Timeline (Source: Figma Engineering Blog)
After deciding to switch to Kubernetes (EKS), the team agreed on the scope of the migration, focusing on minimizing changes required to services to avoid delays and risks. Despite limiting the project’s scope, the company wanted to include specific improvements, like simplified resource definitions to improve developer experience and improved reliability by splitting the deployment into three Kubernetes clusters to avoid the impact of bugs and operator errors.
Ian VonSeggern, software engineering manager at Figma, discussesthe cost optimization goals of the migration project:
We didn’t want to tackle too much complex cost-efficiency work as part of this migration, with one exception: We decided to support node auto-scaling out of the gate. For our ECS on EC2 services, we simply over-provisioned our services so we had enough machines to surge up during a deploy. Since this was an expensive setup, we decided to add this additional scope to the migration because we were able to save a significant amount of money for relatively low work. We used the open-source CNCF project Karpenter to scale up and down nodes dynamically for us based on demand.
To ensure a successful project outcome, Figma created a well-staffed team to drive the migration effort and engage with the broader organization to get their buy-in. The engineers prepared for the production rollout by conducting load testing of the Kubernetes setup to avoid surprises, implementingan incremental switchover mechanism using weighted DNS entries, and deploying services into the staging Kubernetes cluster early in the process to iron out any issues. The compute platform team has worked with service owners to provide a golden path and ensure consistency and ease of maintenance.
The initial migration took less than 12 months, and after migrating core services, the team started looking at follow-up activities like introducing Keda-based autoscaling. Additionally, based on user feedback, engineers simplified developer tooling to work with three Kubernetes clusters and new fine-grained RBAC roles.