
包阅导读总结
1. 关键词:Web Speech API、语音文字互转、用户体验、语音识别、语音合成
2. 总结:本文介绍了纯前端语音文字互转的实现,包括 Web Speech API 的基本概念、功能特性、使用方法,如语音识别和合成的属性、事件,还提及了其在实际场景的应用,强调它对提升用户体验和互联网应用创新的重要性。
3. 主要内容:
– 纯前端语音文字互转前言
– 介绍由 @shanLion 分享的文章
– Web Speech API 介绍
– 是改变用户体验的重要技术
– 包括语音识别和语音合成功能
– Web Speech API 的组成和优势
– 包括 SpeechRecognition 和 SpeechSynthesis 两部分
– 具有多语言支持等优势
– 如何使用 Web Speech API
– 语音识别的属性、事件和实现代码
– 语音合成的属性、事件和实现代码
– SpeechGrammar 的定义和使用示例
– 实际应用场景
– 智能助手和语音搜索等
– 总结
– 对互联网应用用户体验提升有重大贡献,为创意提供支持
思维导图: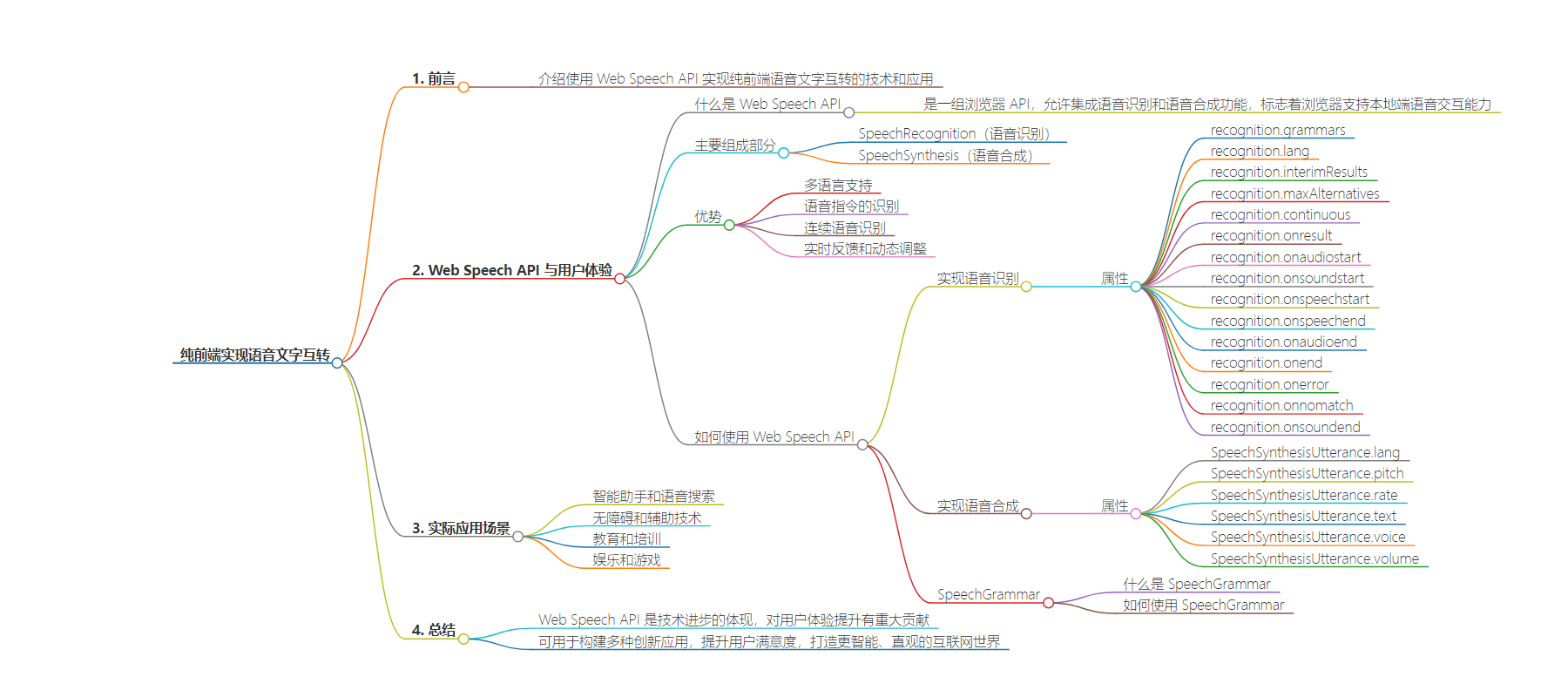
文章地址:https://mp.weixin.qq.com/s/jVT6_OdNUNOsY6PaCnRo1A
文章来源:mp.weixin.qq.com
作者:shanLion
发布时间:2024/8/18 0:07
语言:中文
总字数:2388字
预计阅读时间:10分钟
评分:85分
标签:前端技术,Web Speech API,语音识别,语音合成,JavaScript
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
前言
介绍了如何使用 Web Speech API 实现纯前端语音文字互转的技术和应用。今日前端早读课文章由 @shanLion 分享,公号:奇舞精选授权。
正文从这开始~~
在现代互联网的发展中,语音技术正逐渐成为改变用户体验的重要一环。Web Speech API 的引入使得开发者能够在浏览器中轻松实现语音识别和语音合成功能,为用户带来更加直观和便捷的操作体验。本文将介绍 Web Speech API 的基本概念、功能特性以及如何利用它来构建创新的应用程序。
【第197期】Web Speech Api与用户体验
什么是 Web Speech API?
Web Speech API 是一组浏览器 API,允许开发者在 Web 应用程序中集成语音识别和语音合成功能。这些 API 的引入标志着浏览器开始支持本地端的语音交互能力,不仅改善了用户体验,还为开发者提供了更多创新的可能性。
主要组成部分
Web Speech API 包括两个核心部分:
1、SpeechRecognition(语音识别) :
2、SpeechSynthesis(语音合成) :
优势
-
多语言支持: Web Speech API 支持多种语言,可 0 以通过设置
recognition.lang或utterance.lang来切换不同的语言环境。例如,识别法语、西班牙语等。 -
语音指令的识别:不仅仅是简单的文本转换,可以实现对特定命令或短语的识别,如控制网页的导航、播放媒体等。这需要在识别的事件处理程序中进行语音指令的解析和响应。
-
连续语音识别:设置
recognition.continuous = true,使得语音识别能够持续监听用户的语音输入,而不是单次识别。 -
实时反馈和动态调整:根据识别的实时结果,可以实现实时反馈或动态调整应用程序的行为。例如,在用户说话时动态更新界面或提供即时建议。
如何使用 Web Speech API?
实现语音识别
属性
-
recognition.grammars用于存储一组语法规则,可以通过 addFromString 方法添加语法规则。 -
recognition.lang设置或获取语音识别的语言 -
recognition.interimResults如果设置为 true,则在识别过程中会提供临时结果。如果为 false,则只提供最终结果 -
recognition.maxAlternatives设置语音识别返回的替代结果的最大数量。默认值为 1,表示只返回最可能的结果 -
recognition.continuous如果设置为 true,则识别会持续运行直到显式停止。如果为 false,识别会在单次语音输入后自动停止 -
recognition.onresult当识别结果可用时触发的事件处理程序。事件对象的 results 属性包含识别结果 -
recognition.onaudiostart当开始录制音频时触发的事件处理程序 -
recognition.onsoundstart当检测到声音时触发的事件处理程序 -
recognition.onspeechstart当检测到用户开始说话时触发的事件处理程序 -
recognition.onspeechend当用户停止说话时触发的事件处理程序 -
recognition.onaudioend当音频录制停止时触发的事件处理程序 -
recognition.onend当语音识别结束时触发的事件处理程序 -
recognition.onerror当语音识别发生错误时触发的事件处理程序。事件对象的 error 属性包含错误信息 -
recognition.onnomatch当语音识别没有匹配到任何结果时触发的事件处理程序 -
recognition.onsoundend当检测到的声音停止时触发的事件处理程序
事件
通过以下简单的 JavaScript 代码片段,可以实现基本的语音识别功能:
const recognition = new webkitSpeechRecognition(); // 创建语音识别对象
recognition.lang = 'en-US'; // 设置识别语言为英语
recognition.onresult = function(event) {
const transcript = event.results[0][0].transcript; // 获取识别结果文本
console.log('识别结果:', transcript);
};
recognition.start(); // 开始识别实现语音合成
属性
-
SpeechSynthesisUtterance.lang获取并设置说话的语言 -
SpeechSynthesisUtterance.pitch获取并设置说话的音调(值越大越尖锐,越小越低沉) -
SpeechSynthesisUtterance.rate获取并设置说话的速度(值越大越快) -
SpeechSynthesisUtterance.text获取并设置说话的文本 -
SpeechSynthesisUtterance.voice获取并设置说话时的声音 -
SpeechSynthesisUtterance.volume获取并设置说话的音量
事件
使用 SpeechSynthesis API 实现文本转语音的功能,示例代码如下:
const utterance = new SpeechSynthesisUtterance('Hello, welcome to our website.');
utterance.lang = 'en-US'; // 设置语音合成的语言
window.speechSynthesis.speak(utterance); // 开始语音合成SpeechGrammar
1. 什么是 SpeechGrammar?
SpeechGrammar 对象用于指定一个语法规则,这些规则可以帮助语音识别引擎识别特定的语音输入。它常与 SpeechRecognition 对象结合使用。语法规则可以是简单的文本,也可以是复杂的正则表达式或者语法定义。
2. 如何使用 SpeechGrammar?
要使用 SpeechGrammar,你需要创建一个 SpeechRecognition 对象,并为其添加一个或多个 SpeechGrammar 对象。以下是一个示例:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Speech Grammar Example</title>
</head>
<body>
<button id="startButton">Start Speech Recognition</button>
<div id="output"></div>
<script>
// 确保浏览器支持 SpeechRecognition
const SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;
if (!SpeechRecognition) {
console.error("SpeechRecognition not supported");
} else {
// 创建 SpeechRecognition 实例
const recognition = new SpeechRecognition();
// 定义语法规则
const grammar = '#JSGF V1.0; grammar colors; public <color> = red | green | blue | yellow ;';
// 创建 webkitSpeechGrammarList 实例
const speechGrammarList = new webkitSpeechGrammarList();
speechGrammarList.addFromString(grammar, 1); // 1 是语法的优先级
// 将语法列表应用到 SpeechRecognition 实例
recognition.grammars = speechGrammarList;
// 配置识别选项
recognition.lang = 'en-US'; // 设置语言
recognition.interimResults = false; // 只返回最终结果
recognition.maxAlternatives = 1; // 只返回一个替代结果
// 开始识别
recognition.start();
recognition.onresult = (event) => {
const result = event.results[0][0].transcript;
console.log('识别结果:', result);
};
recognition.onerror = (event) => {
console.error('识别错误:', event.error);
};
}
</script>
</body>
</html>通过合理使用 SpeechGrammar 和 SpeechRecognition,你可以创建更精确的语音识别应用,提升用户体验。
实际应用场景包括但不限于:
-
智能助手和语音搜索:实现类似于 Siri、Google Assistant 等智能助手的语音控制和信息获取功能。
-
无障碍和辅助技术:支持视觉障碍用户的语音导航、文本转语音等辅助功能。
-
教育和培训:提供基于语音的学习和培训工具,如语音答题、学习笔记转录等。
-
娱乐和游戏:实现语音驱动的游戏操作和交互体验,如语音控制角色移动、发声识别等。
总结
Web Speech API 的推出不仅仅是技术进步的体现,更是对互联网应用程序用户体验提升的重大贡献。通过使用这些功能强大的 API,开发者可以为他们的应用程序添加创新的语音交互功能,从而吸引更多用户并提升用户满意度。无论是构建下一代互动游戏、个性化的助手应用,还是革新教育和商业应用,Web Speech API 都将为您的创意提供强大的支持。
探索和利用 Web Speech API,让我们共同打造一个更智能、更直观的互联网世界!
关于本文
作者:@shanLion
原文:https://juejin.cn/post/7397015953453875240

这期前端早读课
对你有帮助,帮”赞“一下,
期待下一期,帮”在看” 一下 。