
包阅导读总结
1. `GraphQL`、`API`、`Development Tool`、`Implementation`、`Challenges`
2. 本文探讨了 GraphQL 的发展历程、价值主张、面临的问题及可能的改进方向。指出其虽取得一定成功但也面临安全、性能和复杂性等挑战,提出将其重新思考为开发工具,并以编译器方式改进实现方式。
3.
– GraphQL 的起源与发展
– 2012 年由 Facebook 开发,2015 年开源,有一定价值主张。
– 曾带来诸多优势,但可能已过期望峰值,进入平稳期。
– GraphQL 的价值与成功
– 满足了多种开发需求,使前后端等能独立迭代。
– 实现了一些承诺,如按需获取数据等。
– GraphQL 面临的问题
– 安全方面,易受不良行为者攻击。
– 性能方面,可能出现不良表现。
– 复杂性方面,给开发者带来巨大挑战。
– GraphQL 的重新思考
– 可视为开发工具,具有灵活性等优点,也有业务逻辑处理等缺点。
– 以编译器方式实现可解决部分问题,如消除 N+1 问题。
– 但也存在关于数据库暴露等担忧,实际可通过多种方式解决。
思维导图: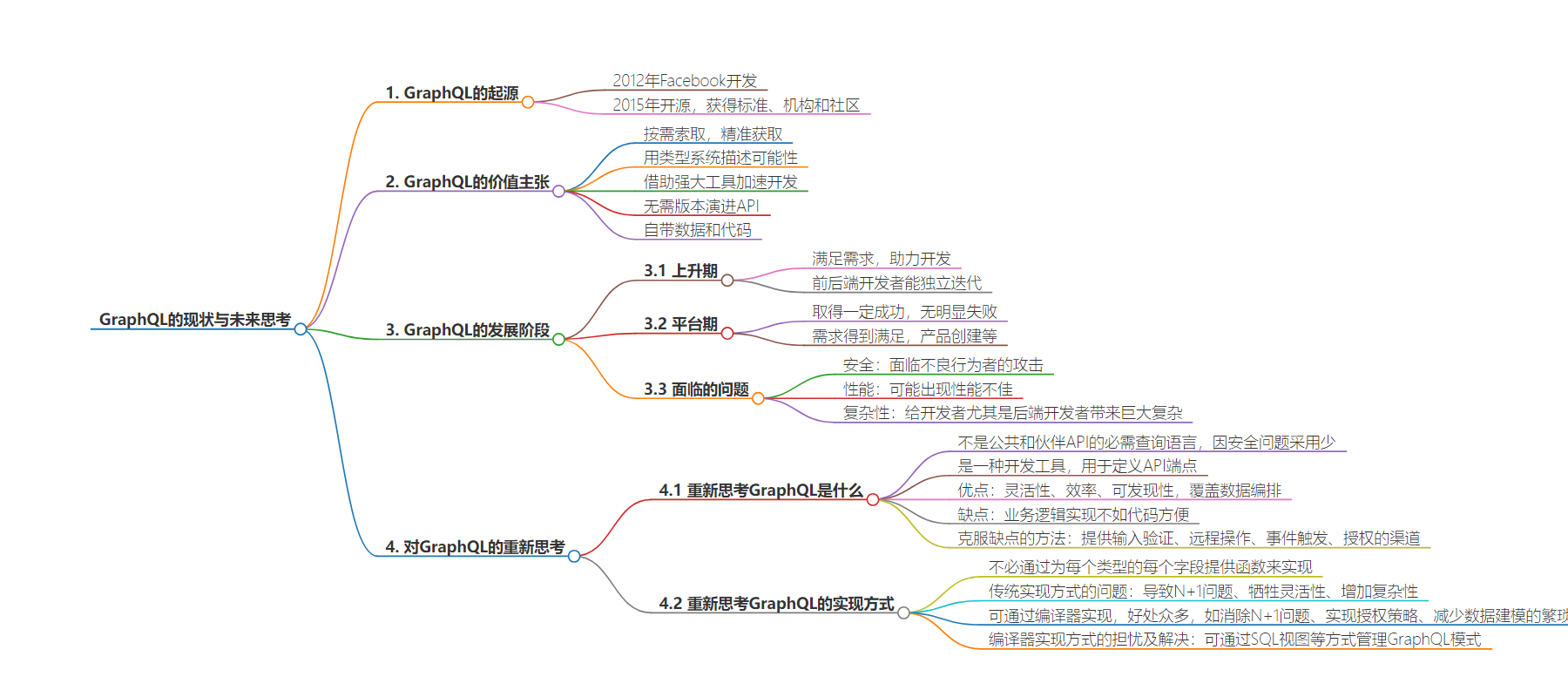
文章地址:https://thenewstack.io/is-graphql-over-or-do-we-just-need-to-rethink-it/
文章来源:thenewstack.io
作者:David A. Ventimiglia
发布时间:2024/7/1 12:43
语言:英文
总字数:2090字
预计阅读时间:9分钟
评分:84分
标签:赞助商-Hasura,资助文章-供稿
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
GraphQL’s origin story is an old one: Developers at Facebook created GraphQL in 2012 as part of the social media giant’s shift from web to mobile. They had a high-performance object-oriented data platform as a foundation. They needed a flexible and expressive web API on top of it to satisfy the needs of nimble mobile developers iterating rapidly on an inherently dynamic, graph-oriented application.
They revamped and open sourced GraphQL in 2015 to great fanfare, with the Facebook marketing might behind it. It got a standard, a standards body, and a community. Along the way, GraphQL’s value proposition settled on a few simple promises.
- Ask for what you need, get exactly that.
- Describe what’s possible with a type system.
- Move faster with powerful developer tools.
- Evolve your API without versions.
- Bring your own data and code.
And, it delivered! GraphQL is a general-purpose query language, giving API consumers the ability to ask in a single request for all the data they need. It gave API producers the ability to say in a single response exactly which data they offer and how. It gave frontend developers the ability to iterate independently of backend developers. It gave backend developers the ability to evolve independently of frontend developers. It gave middleware developers the ability to help both frontend and backend developers without needing to consult with either. And, it gave architects and data governors the ability to fulfill their dreams of harmonic convergence. GraphQL had its Technology Trigger and was on its way up.
Life
GraphQL may have crested the Peak of Inflated Expectations since then, but it’s reached a broad flat plateau where the weather is mild and the terrain is gentle. There have been laudable successes and no overt failures. Needs were met, products were created, wars were fought, and empires were founded.
When plateaus inevitably come to an end, however, pioneers have to plan a difficult descent and journey beyond. The bloom is off the GraphQL rose and not all is a bed of roses. Discontentment rises and disillusionment beckons, and the tools and tricks that got us here may not work for what lies ahead.
Death
Rumors of GraphQL’s demise are greatly exaggerated. GraphQL is far from extinct, but what environmental conditions threaten its path to flourishing? An emerging consensus groups the various grumblings about GraphQL into three main complaints.
- Security — GraphQL exposes public APIs to exfiltration, tampering and denial-of-service from bad actors.
- Performance — GraphQL exposes all APIs to bad performance even from friendly actors.
- Complexity — GraphQL exposes developers – especially backend developers – to enormous complexity.
In short, if GraphQL APIs are a dream to use, they’re a nightmare to create, especially if security and performance needs are to be met. GraphQL’s critics have valid points. Addressing those points and leading it out of a dark wood may require rethinking GraphQL from the ground up.
Rebirth
What is GraphQL and how is it implemented? The GraphQL Foundation answers those questions in this way:
“GraphQL is a query language for your API…[and] is created by …providing functions for each field on each type.”
It’s time to rethink both parts of that answer.
Rethinking What GraphQL Is
GraphQL is not necessarily a “query language for your API.” Public and partner APIs don’t control or even know their clients, can’t control or even anticipate usage patterns, and therefore would benefit from a flexible query language, and yet there are few public and partner GraphQL APIs.
Anecdotal evidence suggests that the security criticisms of GraphQL listed above constitute the main barrier to GraphQL adoption for public APIs. While there do exist GraphQL security measures that can blunt attacks, we should remember that the market for public APIs may be small and may be getting smaller as enthusiasm for public and even partner APIs wanes.
That leaves private APIs. Yet private APIs typically own their clients, know their usage patterns and don’t need a flexible query language. So, what then even is GraphQL in this setting?
GraphQL is a development tool. An emerging rebuttal to the criticisms of GraphQL listed above is to use persisted queries, allow-lists and RESTified-endpoints. That blunts the security criticism against GraphQL APIs largely by removing GraphQL APIs and substituting them with good old-fashioned REST.
GraphQL becomes a way to define API endpoints. It’s an alternative to defining API endpoints in code, but code is a development tool, so then what is GraphQL but a development tool? If GraphQL is a development tool, then what are its benefits (and its drawbacks)?
The benefits of GraphQL over code as a development tool for defining API endpoints accrue to its original strengths: flexibility, efficiency and discoverability. GraphQL is a lingua franca, a ubiquitous-language to mediate conversations among front-end developers, back-end developers, data modelers, and product owners, but it’s also an implementationlanguage for the outcome of those conversations. It covers 80% of what code is being asked to do when building APIs – data marshaling – better than code can do it.
The drawbacks of GraphQL over code as a development tool for defining API endpoints lie in that remaining 20%: “business-logic.” API server code is a convenient if far from ideal arena for implementing business logic.
Business logic, unlike data marshaling, really does benefit from the power of code, and if you’re using code to write your API server, you might as well just use the same code to implement the business logic right in the API server. Never mind that this mixes concerns and leads to tight coupling, it at least has the virtue of being obvious.
But these drawbacks can be overcome by building a GraphQL server that has no intrinsic business logic, but instead offers channels for injecting business logic:
- input-validation — synchronous RPC into the language of your choice for the simple but common case of validating input data
- remote-actions — synchronous RPC into the language of your choice for the less simple but less common general business-logic case
- event-triggers — asynchronous event processor in the language of your choice for the common case of exhibiting side effects
- authorization —elegant strategy for the common but thorny problem of access control
Not only do these features equal the “obvious” strategy for business-logic of writing it right into the server code, they exceed it by freeing it from the language of the server and by separating it from the concerns of the server.
Rethinking what GraphQL is by thinking of it as a development tool frees us from a major impediment to GraphQL’s progress into the future. The other major impediment is removed as we will see by rethinking how GraphQL is implemented.
Listing 1: GraphQL as a development tool: from Hasura GraphQL definition…

Listing 2: GraphQL as a development tool: …to Hasura REST API!
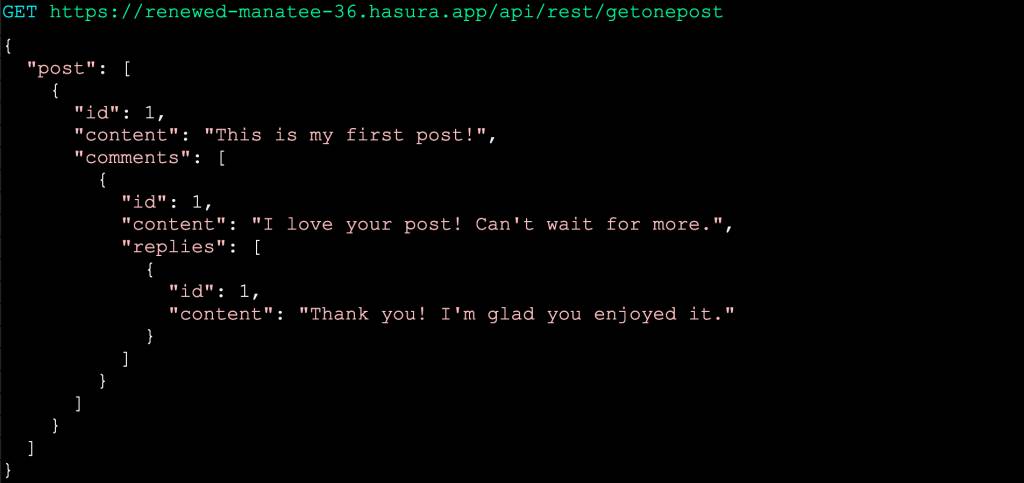
Rethinking How GraphQL Is Implemented
GraphQL need not necessarily be implemented by “providing functions for each field on each type.” Those functions are typically called resolvers. They are units of composition in the way servers typically execute GraphQL operations. Their granularity and composability fulfill the promise of GraphQL flexibility. Yet they also are to blame for the performance criticisms of GraphQL listed above.
Not all servers, GraphQL or otherwise, are over SQL databases, but many are, and if we use SQL databases as a representative case, the granularity and composability of resolvers also gives rise to the N+1 problem: a query graph whose node number grows exponentially with every level leads to a call graph whose resolver function calls grow exponentially, which leads to a batch of SQL statements that grows exponentially.
Never mind that the retrieved data volume also grows exponentially with every level, which imposes a natural limit on how far this can go, this is still a problem. And yet the leading solution to this problem – the data-loader pattern – only diminishes the problem without banishing it, sacrifices much of GraphQL’s flexibility and contributes to the complexity, which is the third criticism listed above. Confronted with this Gordian knot, it’s worth asking another foundational question. Can we implement GraphQL in some other way, and if so, how?
GraphQL can be implemented with a compiler. GraphQL is a general-purpose query language that often, if not always, is over data that ultimately comes from database engines with their own general-purpose query languages. If those engines happen to process their queries with a network of operators that bear more than a passing resemblance to resolvers, that’s their business. All we have to do is compile (or translate, or transpile) our query into theirs and let them handle the rest. Some people in the GraphQL community are finally getting around to this idea. Some of us have been here all along.
The benefits of a compiler approach to GraphQL are many. It eliminates the N+1 problem. It paves the way for a powerful strategy for implementing authorization as discussed above. And, by generating the GraphQL schema from the database schema, it eliminates tedious repetitive boilerplate data modeling that serves high-minded ideals that are impractical at scale.
The drawbacks of a compiler approach to GraphQL are legendary, but in that word’s first meaning rather than its second: “of, relating to, or characteristic of legend or a legend” — folklore.
The fear is that by generating the GraphQL schema from the database schema, the database is exposed and the data modeler’s hands are tied. That would be a problem if it were true, but it isn’t. The GraphQL schema can be curated as much or as little as needed via SQL views, SQL functions, and affordances and configurations within the GraphQL server.
Moreover, the proposed alternative isn’t as different as one might think. Deliberately, thoughtfully, lovingly “designing” a GraphQL data model by meticulously writing resolvers is just making the same choices in code as we recommend through configuration, albeit by taking the long way around.
Rethinking how GraphQL is implemented by thinking of it as a compiler opens up new strategies for addressing old problems. It may not be possible in every case. In Facebook’s OG use case for creating GraphQL, it had a high-performance object-based data model many layers of abstraction away from any databases. That’s a blessing and a curse. There may be no query language to compile to, but on the other hand, you can string together resolvers to your heart’s content and sleep easy at night knowing the high-performance object-based data model’s vast reserves of optimized performance will absorb or neutralize any N+1 performance problems thrown at it. For the rest of us with our puny SQL databases? Let’s just generate our GraphQL schema, compile our GraphQL queries and call it a day.
Listing 1: GraphQL implemented with a compiler: From GraphQL…

Listing 2: GraphQL implemented with a compiler: …to optimized SQL!
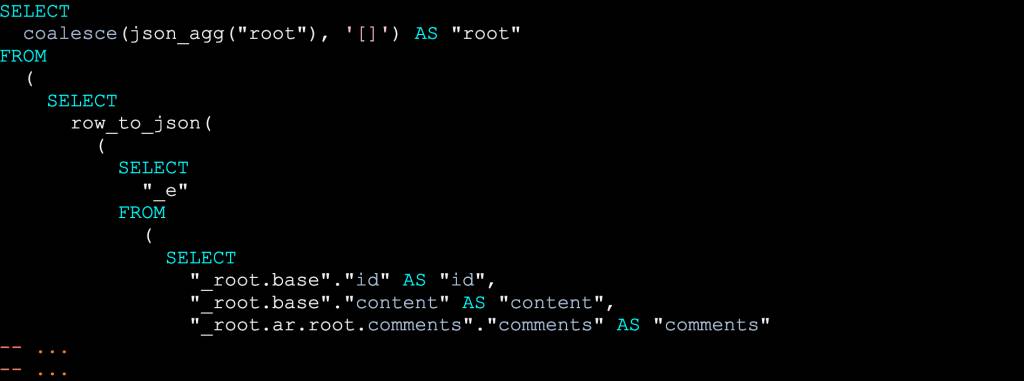
Closing
GraphQL is far from dead but it is entering a threatening woods prowled by three wolves: security, performance and complexity. The good news is there’s a strategy for getting out of the woods: rethink what GraphQL is and rethink how GraphQL is implemented.
GraphQL is a development tool.
Benefit from GraphQL’s promises of independence and nimbleness without sacrificing security, by using GraphQL to develop API endpoints.
GraphQL is implemented with a compiler.
Benefit from GraphQL’s promises of efficiency and type safety without sacrificingperformanceand without confronting complexity by implementing GraphQL with a compiler for the underlying data platform’s native query interface.
Not every use case can be satisfied just with API endpoints, and not every use case has the luxury of an underlying data platform with a native query interface, but many do. Moreover, they’re often the ones most exposed to the perceived problems of security, performance and complexity.
Life is about trade-offs. Choices have to be made. GraphQL has a choice to live or die, but it won’t be made without trade-offs. Cherished ideas about what GraphQL is and how it should be implemented may have to give way to a changing reality. The old ways of thinking about GraphQL may have to die, to give life to new ways of thinking that allow GraphQL to flourish.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.