
包阅导读总结
1. 关键词:Delta Live Tables、Serverless Compute、ETL、Cost-effective、Reliability
2. 总结:
本文介绍了 Delta Live Tables(DLT)管道的无服务器计算,强调其在成本效益、性能和可靠性方面的优势,包括简化开发与操作、提供端到端增量处理、降低总拥有成本等,且目前已可用并将持续优化。
3. 主要内容:
– Delta Live Tables 与无服务器计算
– 宣布无服务器计算在 Notebooks、Workflows 和 DLT 管道的全面可用
– 解释 DLT 管道如何受益于无服务器计算
– DLT 管道的优势
– 简单性
– 自动化大部分操作复杂性
– 声明式编程构建批处理和流处理管道
– 简单的 API 处理变更数据捕获
– 保证数据质量和强大的可观测性
– 水平自动扩展和自动升级
– 无服务器基础设施垂直自动扩展
– 性能
– 提供端到端增量处理
– 快速启动
– 提高吞吐量
– 高效变换
– 低总拥有成本
– 增量处理降低成本
– 弹性计费
– 具体能力
– 端到端增量处理
– 处理分为摄入和转换阶段
– 支持流媒体表摄入和物化视图转换的增量刷新
– 更低成本和更好的数据新鲜度
– 自动处理物化视图的增量刷新
– 内部基准显示性能提升
– 更快、更便宜的摄入
– 流管道提高加载文件和事件的吞吐量
– 支持内存密集型 ETL 工作负载
– 自动垂直缩放计算和内存资源
– 无服务器 DLT 现状与未来
– 现已可用
– 即将到来的增强功能包括多云支持、成本和性能优化、私有网络和出口控制、可执行归因等
思维导图: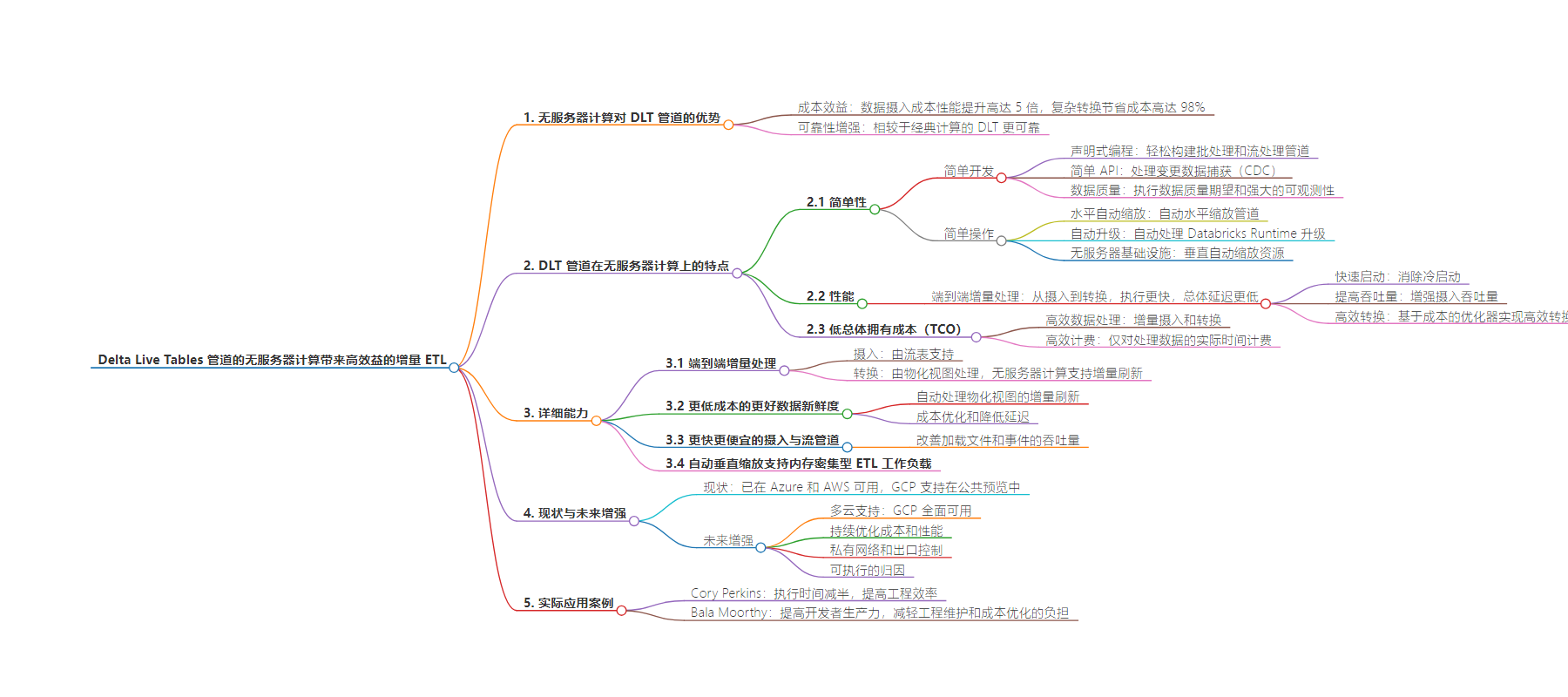
文章来源:databricks.com
作者:Databricks
发布时间:2024/8/27 10:27
语言:英文
总字数:1387字
预计阅读时间:6分钟
评分:82分
标签:Delta Live Tables,无服务器计算,ETL 管道,数据处理,增量处理
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
We recently announced the general availability of serverless compute for Notebooks, Workflows, and Delta Live Tables (DLT) pipelines. Today, we’d like to explain how your ETL pipelines built with DLT pipelines can benefit from serverless compute.
DLT pipelines make it easy to build cost-effective streaming and batch ETL workflows using a simple, declarative framework. You define the transformations for your data, and DLT pipelines will automatically manage task orchestration, scaling, monitoring, data quality, and error handling.
Serverless compute for DLT pipelines offers up to five times better cost-performance for data ingestion and up to 98% cost savings for complex transformations. It also provides enhanced reliability compared to DLT on classic compute. This combination leads to fast and dependable ETL at scale on Databricks. In this blog post, we’ll delve into how serverless compute for DLT achieves outstanding simplicity, performance, and the lowest total cost of ownership (TCO).
DLT pipelines on serverless compute are faster, cheaper, and more reliable
DLT on serverless compute enhances throughput, improving reliability, and reducing total cost of ownership (TCO). This improvement is due to its ability to perform end-to-end incremental processing throughout the entire data journey—from ingestion to transformation. Additionally, serverless DLT can support a wider range of workloads by automatically scaling compute resources vertically, which improves the handling of memory-intensive tasks.
Simplicity
DLT pipelines simplify ETL development by automating most of the operational complexity. This allows you to focus on delivering high-quality data instead of managing and maintaining pipelines.
Simple development
- Declarative Programming: Easily build batch and streaming pipelines for ingestion, transformation and applying data quality expectations.
- Simple APIs: Handle change-data-capture (CDC) for SCD type 1 and type 2 formats from both streaming and batch sources.
- Data Quality: Enforce data quality with expectation and leverage powerful observability for data quality.
Simple operations
- Horizontal Autoscaling: Automatically scale pipelines horizontally with automated orchestration and retries.
- Automated Upgrades: Databricks Runtime (DBR) upgrades are handled automatically, ensuring you receive the latest features and security patches without any effort and minimal downtime.
- Serverless Infrastructure: Vertical autoscaling of resources without needing to pick instance types or manage compute configurations, enabling even non-experts to operate pipelines at scale.
Performance
DLT on serverless compute provides end-to-end incremental processing across your entire pipeline – from ingestion to transformation. This means that pipelines running on serverless compute will execute faster and have lower overall latency because data is processed incrementally for both ingestion and complex transformations. Key benefits include:
- Fast Startup: Eliminates cold starts since the serverless fleet ensures compute is always available when needed.
- Improved Throughput: Enhanced ingestion throughput with stream pipeline for task parallelization.
- Efficient Transformations: Enzyme cost-based optimizer powers fast and efficient transformations for materialized views.
Low TCO
In DLT using serverless compute, data is processed incrementally, enabling workloads with large, complex materialized views (MVs) to benefit from reduced overall data processing times. The serverless model uses elastic billing, meaning only the actual time spent processing data is billed. This eliminates the need to pay for unused instance capacity or track instance utilization. With DLT on serverless compute, the benefits include:
- Efficient Data Processing: Incremental ingestion with streaming tables and incremental transformation with materialized views.
- Efficient Billing: Billing occurs only when compute is assigned to workloads, not for the time required to acquire and set up resources.
“Serverless DLT pipelines halve execution times without compromising costs, enhance engineering efficiency, and streamline complex data operations, allowing teams to focus on innovation rather than infrastructure in both production and development environments.”
— Cory Perkins, Sr. Data & AI Engineer, Qorvo
“We opted for DLT namely to boost developer productivity, as well as the embedded data quality framework and ease of operation. The availability of serverless options eases the overhead on engineering maintenance and cost optimization. This move aligns seamlessly with our overarching strategy to migrate all pipelines to serverless environments within Databricks.”
— Bala Moorthy, Senior Data Engineering Manager, Compass
Let’s look at some of these capabilities in more detail:
End-to-end incremental processing
Data processing in DLT occurs at two stages: ingestion and transformation. In DLT, ingestion is supported by streaming tables, while data transformations are handled by materialized views. Incremental data processing is crucial for achieving the best performance at the lowest cost. This is because, with incremental processing, resources are optimized for both reading and writing: only data that has changed since the last update is read, and existing data in the pipeline is only touched if necessary to achieve the desired result. This approach significantly improves cost and latency compared to typical batch-processing architectures.
Streaming tables have always supported incremental processing for ingestion from cloud files or message buses, leveraging Spark Structured Streaming technology for efficient, exactly-once delivery of events.
Now, DLT with serverless compute enables the incremental refresh of complex MV transformations, allowing for end-to-end incremental processing across the ETL pipeline in both ingestion and transformation.
Better data freshness at lower cost with incremental refresh of materialized views
Fully recomputing large MVs can become expensive and incur high latency. Previously in order to do incremental processing for complex transformation users only had one option: write complicated MERGE and forEachBatch() statements in PySpark to implement incremental processing in the gold layer.
DLT on serverless compute automatically handles incremental refreshing of MVs because it includes a cost-based optimizer (“Enzyme”) to automatically incrementally refresh materialized views without the user needing to write complex logic. Enzyme reduces the cost and significantly improves latency to speed up the process of doing ETL. This means that you can have better data freshness at a much lower cost.
Based on our internal benchmarks on a 200 billion row table, Enzyme can provide up to 6.5x better throughput and 85% lower latency than the equivalent MV refresh on DLT on classic compute.
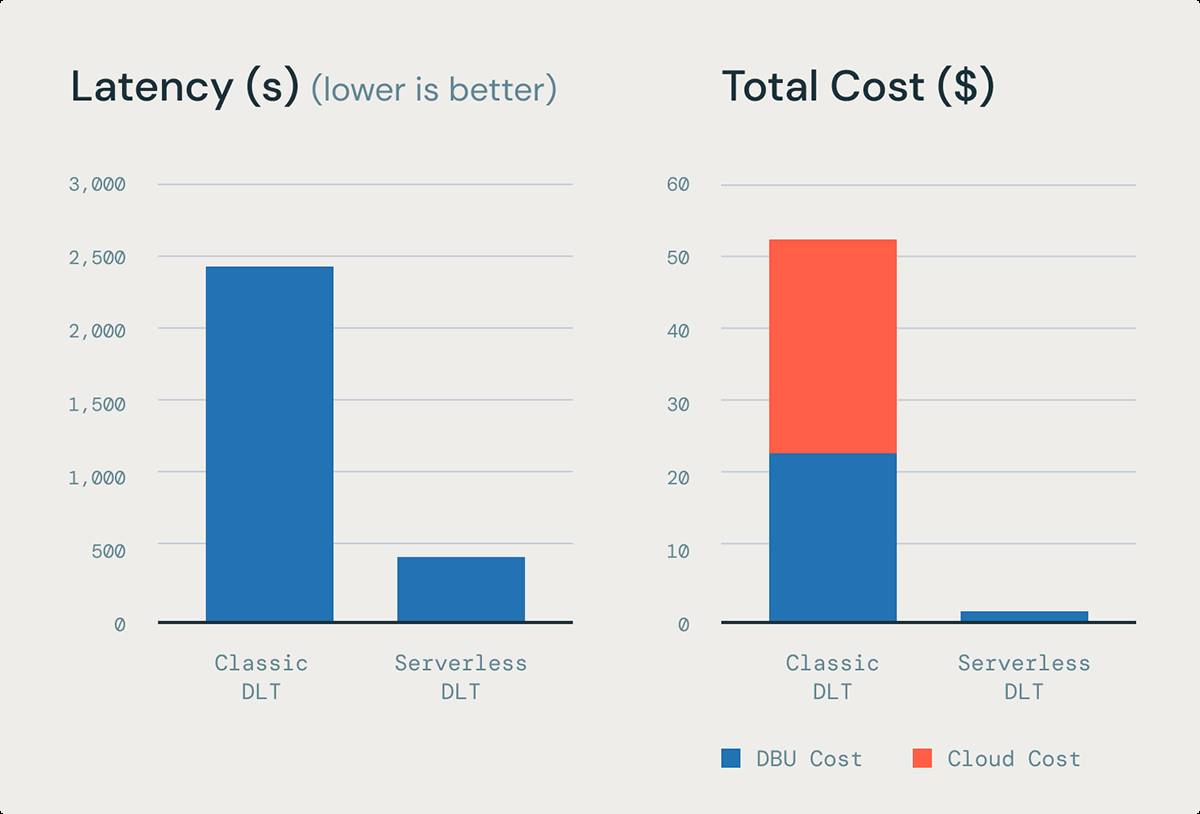
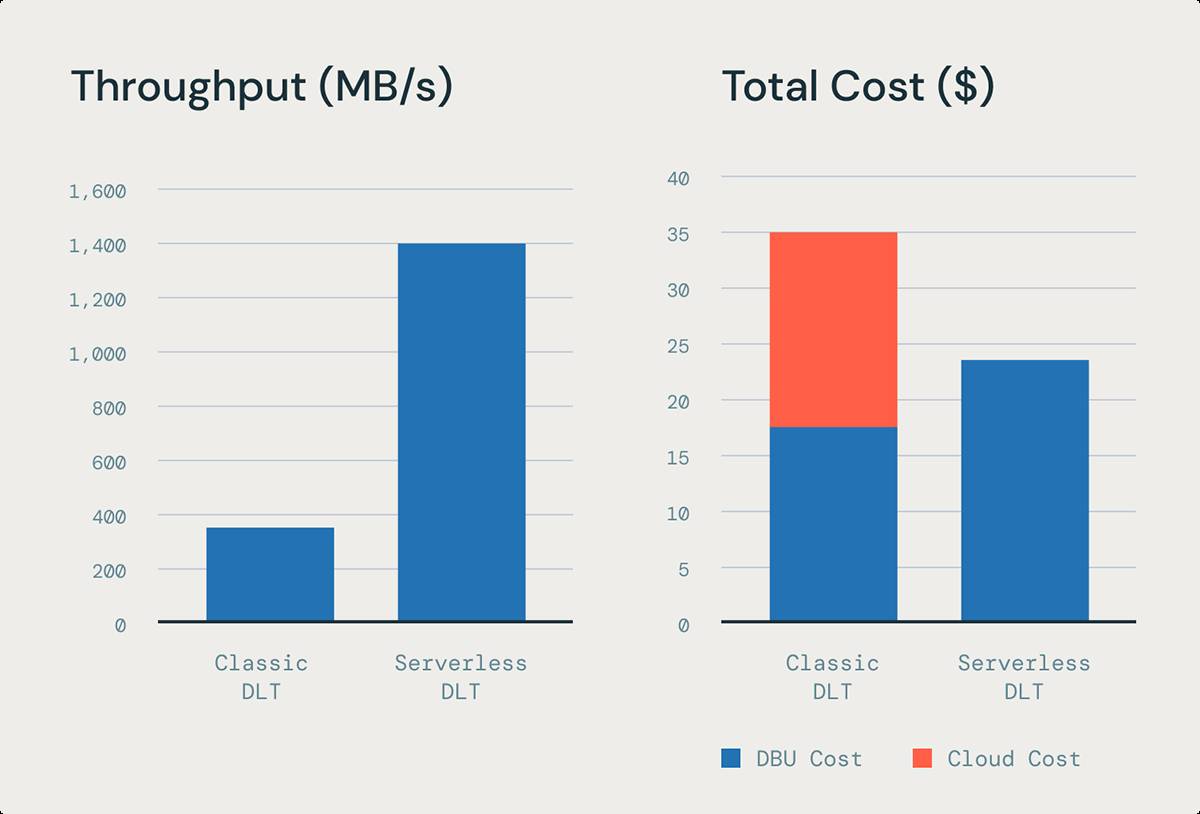
Faster, cheaper ingestion with stream pipelining
Streaming pipelining improves the throughput of loading files and events in DLT when using streaming tables. Previously, with classic compute, it was challenging to fully utilize instance resources because some tasks would finish early, leaving slots idle. Stream pipelining with DLT on serverless compute solves this by enabling SparkTM Structured Streaming (the technology that underpins streaming tables) to concurrently process micro-batches. All of this leads to significant improvements of streaming ingestion latency without increasing cost.
Based on our internal benchmarks of loading 100K JSON files using DLT, stream pipelining can provide up to 5x better price performance than the equivalent ingestion workload on a DLT classic pipeline.
Enable memory-intensive ETL workloads with automatic vertical scaling
Choosing the right instance type for optimal performance with changing, unpredictable data volumes – especially for large, complex transformations and streaming aggregations – is challenging and often leads to overprovisioning. When transformations require more memory than available, it can cause out-of-memory (OOM) errors and pipeline crashes. This necessitates manually increasing instance sizes, which is cumbersome, time-consuming, and results in pipeline downtime.
DLT on serverless compute addresses this with automatic vertical auto-scaling of compute and memory resources. The system automatically selects the appropriate compute configuration to meet the memory requirements of your workload. Additionally, DLT will scale down by reducing the instance size if it determines that your workload requires less memory over time.
DLT on serverless compute is ready now
DLT on serverless compute is available now, and we are continuously working to improve it. Here are some upcoming enhancements:
- Multi-Cloud Support: Currently available on Azure and AWS, with GCP support in public preview and GA announcements later this year.
- Continued Optimization for Cost and Performance: While currently optimized for fast startup, scaling, and performance, users will soon be able to prioritize goals like lower cost.
- Private Networking and Egress Controls: Connect to resources within your private network and control access to the public internet.
- Enforceable Attribution: Tag notebooks, workflows, and DLT pipelines to assign costs to specific cost centers, such as for chargebacks.
Get started with DLT on serverless compute today
To start using DLT on serverless compute today: