
包阅导读总结
1. 关键词:前端、文件上传、base64、formData、大文件处理
2. 总结:
本文介绍了前端文件上传的操作,包括与后端交互的方式(base64 和 formData),前端文件操作相关对象(files、blob、fileReader),还通过实例展示了获取文件信息、图片预览和发送给服务器的实现,最后探讨了大文件处理中的切片上传、上传进度、断点续传和秒传等。
3. 主要内容:
– 前端与后端的交互方式
– base64 表示二进制数据的方法及特点
– formData 键值对格式传输数据,可添加二进制数据
– 前端文件操作相关的对象
– files:通过 `` 上传文件得到的信息对象列表
– blob:不可变二进制内容,有操作方法
– fileReader:用于将文件读取为特定形式
– 使用案例
– 获取文件信息,限制上传文件大小和类型
– 图片预览,使用 FileReader 读取文件内容
– 发送给服务器,通过 formData 对象
– 大文件处理
– 切片上传,按指定大小分割文件
– 上传进度,根据切片数量计算
– 断点续传,用 hash 值标记文件
– 秒传,服务器根据 hash 值判断文件是否已上传
思维导图:
文章地址:https://mp.weixin.qq.com/s/5IDPnM7cd9ILloA5KALO3g
文章来源:mp.weixin.qq.com
作者:loftyamb
发布时间:2024/6/24 10:49
语言:中文
总字数:2437字
预计阅读时间:10分钟
评分:86分
标签:前端,文件上传,Web 开发,JavaScript,文件处理
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
点击关注公众号,“技术干货”及时达!
前端与后端的交互方式
前端上传文件时,可以通过两种方式与后端进行交互:
-
base64是一种基于64个可打印字符来表示二进制数据的表示方法,由于 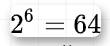 ,因此一个base64字符可以表示6位的二进制数据,对应的,3个字节的二进制数据可以用4个base64字符来表示
,因此一个base64字符可以表示6位的二进制数据,对应的,3个字节的二进制数据可以用4个base64字符来表示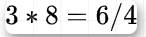
-
字符串或文件的 Base64 版本通常比其原来的内容大大约三分之一(确切的大小增加取决于各种因素,如字符串的绝对长度、它除以 3 的长度余数,以及是否使用填充字符)
-
在前端中,我们可以用formData来传输数据,它是一种键值对格式的数据,formData能添加二进制数据进去
前端文件操作相关的对象
前端在进行文件操作时,通常会有以下几种对象:
-
files:通过<input type="file">元素上传文件后,得到的文件信息对象列表,它是一个file数组,而file继承自blob -
blob:表示不可变的二进制内容,包含很多操作方法 -
fileReader:多用于将文件读取为某一形式,如base64,text文本
使用案例
接下来,我们用一个例子来演示它们具体的作用:
<inputtype="file"name=""id="uploader">
<script>
constuploader=document.querySelector('#uploader')
uploader.addEventListener('change',(event)=>{
constfile=event.target.files[0]
console.log('选择的文件更改后触发的事件',file);
})
</script>
在页面中:

获取文件信息
当我们选择了一个文件上传之后,将看到浏览器控制台中的打印信息:
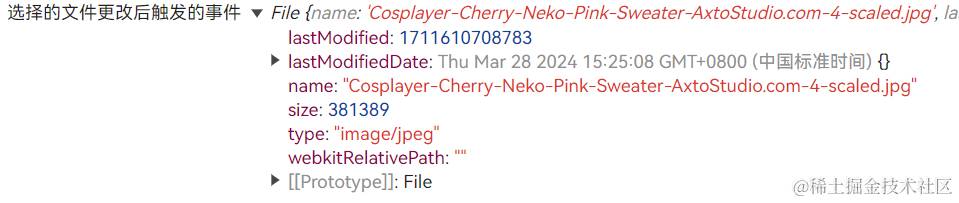
可以看到,打印出来的file对象中包含了已选择文件的基本信息(大小、类型、名称、修改时间等)
因此,我们可以通过编写相应的逻辑来限制用户上传的文件大小、类型等:
uploader.addEventListener('change',(event)=>{
constfile=event.target.files[0]
console.log('选择的文件更改后触发的事件',file);
if(file.size>10*1024*1024){
returnwindow.alert('上传文件的大小不能超过10M')
}
if(!['image/jpeg','image/png'].includes(file.type)){
returnwindow.alert('上传文件类型必须为png、jpg、jpeg其中一种格式')
}
})
图片预览
那么,如果我们希望用户在选择完图片之后,在页面中显示图片的略缩图,我们要怎么做呢?
答:使用FileReader可以帮助我们在前端读取文件内容,它需要一个接收blob对象(同样的,file对象也可以)
具体实现如下:
<inputtype="file"name=""id="uploader">
<imgsrc=""alt=""id="preview"style="width:200px;">
<script>
constuploader=document.querySelector('#uploader')
uploader.addEventListener('change',(event)=>{
constfile=event.target.files[0]
console.log('选择的文件更改后触发的事件',file);
if(file.size>10*1024*1024){
returnwindow.alert('上传文件的大小不能超过10M')
}
if(!['image/jpeg','image/png'].includes(file.type)){
returnwindow.alert('上传文件类型必须为png、jpg、jpeg其中一种格式')
}
readFilePreview(file)
})
constpreview=document.querySelector('#preview')
functionreadFilePreview(file){
constfileReader=newFileReader()
fileReader.onload=(event)=>{
console.log('读取完成',event.target.result);
preview.src=event.target.result
}
fileReader.readAsDataURL(file)
}
</script>
在上面的代码中:
-
我们创建了一个 FileReader实例,并为其添加了onload事件处理,随后调用了readAsDataUrl方法,它需要传入一个blob对象,之后会将blob对象对应的文件内容读取为包含base64编码格式内容的Data URL -
我们可以将得到的Data URL传入到元素的 src中,在页面中显示用户选择上传的图片预览

发送给服务器
通过formData对象我们可以给服务器发送二进制数据,具体做法如下:
constformData=newFormData()
formData.append('file',file)
axios.post('http://localhost:3002/upload',formData,{
headers:{
'Content-Type':'multipart/form-data'
}
}).then(res=>{
console.log('响应结果',res);
})
对象之间的关系
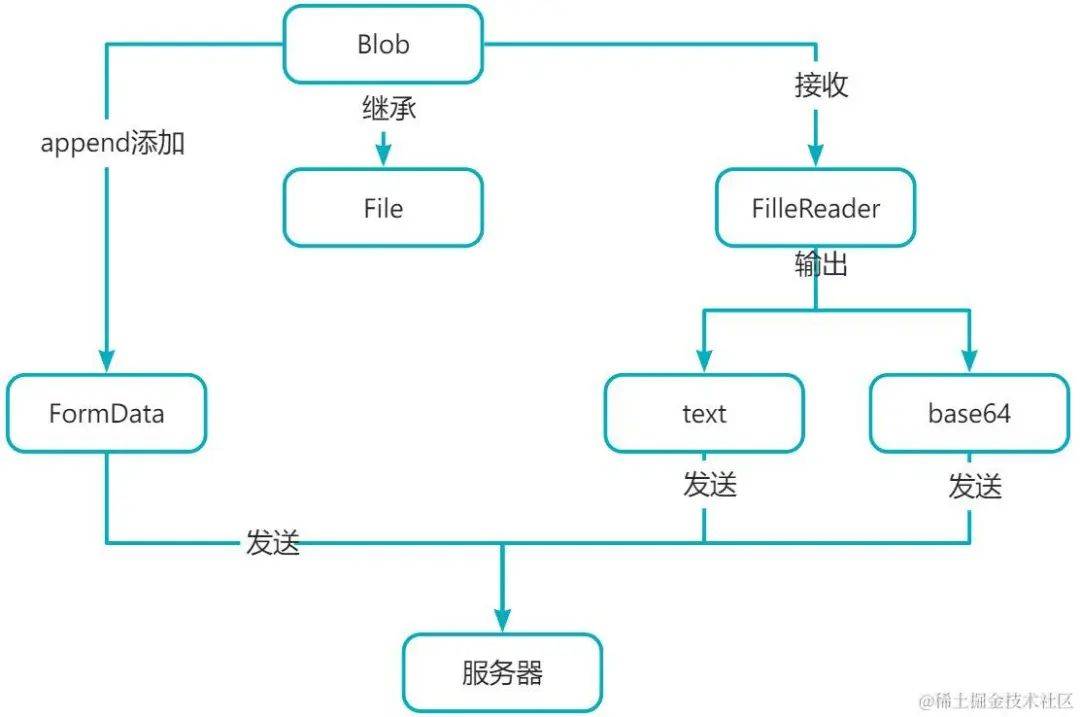
大文件处理
在实际开发中,我们会遇到前端需要上传大文件的场景,这种情况下,如果直接将一个大文件一次性发送到服务器中,会面临以下的问题:
-
当由于网络原因导致上传中断时,需要重新上传整个文件,用户体验不好
切片上传
对此,我们常用的做法是对大文件进行切片上传,具体做法如下:
functionfileToChunks(file,chunkSize=10*1024*1024){
constfileSize=file.size
constchunks=[]
letcurrent=0
//判断上一次截取的位置是否将文件截取完了
while(current<fileSize){
chunks.push(file.slice(current,current+chunkSize))
current+=chunkSize
}
returnchunks
}
备注:文件的切片操作速度是很快的,因为它只是对文件信息进行处理,而不是直接对文件中包含的数据进行处理
上传进度
上传进度的实现很简单,因为我们已经可以得知大文件被切片的数量了,通过已上传到服务器成功的数量就可以计算出上传进度
断点续传
大文件上传会面临的一个问题是由于网络等原因导致只上传了一部分文件,这时候,我们需要实现的一个功能为:断点续传,也就是在大文件上传中断后,之后如果再次上传只需要上传没有上传成功的那部分,而不需要再次上传已经上传成功的部分
那么,我们需要如何判断这个文件的一部分是已经上传过的呢?
很显然,我们需要让它有一个标记,来表明它和之前上传的文件属于同一份
那么,应该采用什么来标记它呢?是文件名?文件路径?还是其它?
答案是hash值,它会根据文件的内容来计算出一个无法被逆推的字符串,具体有很多种hash算法,这里我们采用md5:
functiongetFileChunksHash(chunks){
returnnewPromise((resolve)=>{
constspark=newSparkMD5.ArrayBuffer()
constfileReader=newFileReader()
letindex=0
fileReader.onload=(event)=>{
console.log(event.target.result);
spark.append(event.target.result)
index++
if(index===chunks.length){
returnresolve(spark.end())
}
_read()
}
_read()
function_read(){
fileReader.readAsArrayBuffer(chunks[index])
}
})
}
在上面的代码中:
-
我们使用了 spark-md5库,并采用增量算法来得到某个文件最终的hash值,所谓的增量算法就是对指定文件的切片分别进行hash计算,最后再得到整个文件的hash -
由于hash的计算需要先读取文件以及进行hash算法的运行,因此它是一个CPU密集型的操作,如果文件过大,就会导致hash值的计算需要等待很久,因此我们还可以将hash计算放到Web Worker中进行
对于B站这样的平台,它们在对于超大文件的上传时,还会做进一步的处理,例如:
-
先将这个超大文件进行切片,切成多个大切片,先计算其中一个大切片的hash值,再对这个大切片进行进一步切片,切成小切片进行上传
秒传
所谓的秒传,即用户在上传文件的时候,服务器会先判断是否该文件已经被其它用户上传过来(同样是根据hash值比较),如果该文件已经被上传过来,那么用户就无需上传了,服务器直接返回文件上传成功的结果给用户,从用户视角来看,文件的上传速度是很快的。