
包阅导读总结
1. 关键词:
– Kubernetes
– 数据库
– 高可用
– 资源规划
– 备份恢复
2. 总结:
本文探讨了在 Kubernetes 中运行数据库的相关问题,包括数据库在云提供商中的定位争论,介绍了在 Kubernetes 中成功运行数据库的设计模式,如节点选择、资源规划、实现高可用、备份恢复等,还提到在 Kubernetes 中运行数据库的成本和跨平台优势。
3. 主要内容:
– 关于数据库在 Kubernetes 中运行的争论
– 普遍观点认为数据库应作为云提供商的托管服务。
– 在 Kubernetes 中运行数据库的设计模式
– 利用节点选择器确保数据库 Pod 位于可挂载卷的可用区。
– 规划资源使用,为数据库工作负载运行单独的节点组或节点池。
– 高可用性策略
– 使用 Kubernetes 操作符,如 Zalando Postgres Operator。
– 自服务方法,包括挂载数据卷、设置 Pod 亲和性等。
– 备份和恢复
– 利用服务提供商的磁盘卷定期快照功能。
– 结合数据库专有工具。
– 总结优势
– 成本优势。
– 供应商不可知论,便于跨平台迁移工作负载。
思维导图: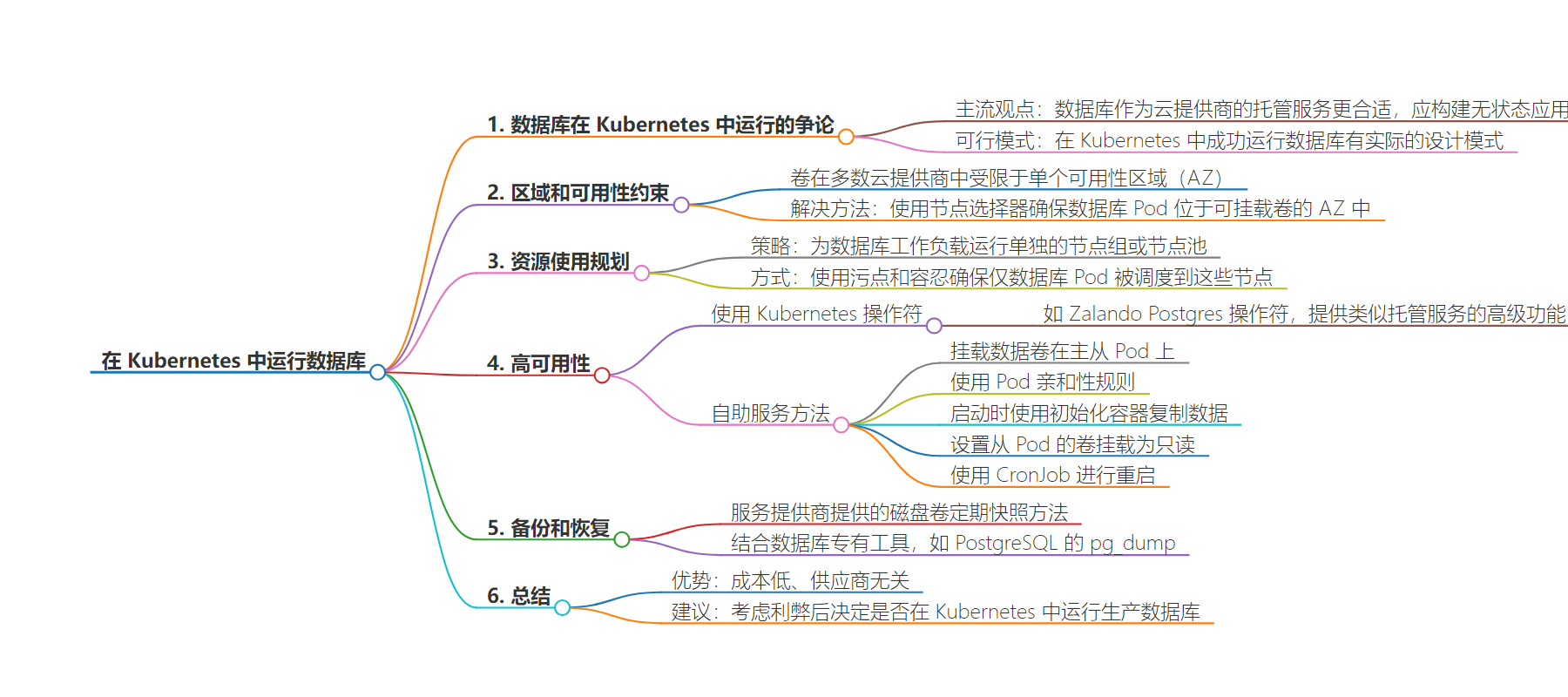
文章地址:https://thenewstack.io/how-to-run-databases-in-kubernetes/
文章来源:thenewstack.io
作者:Kolawole Olowoporoku
发布时间:2024/7/22 20:35
语言:英文
总字数:1098字
预计阅读时间:5分钟
评分:83分
标签:Kubernetes,数据库,高可用性,资源管理,备份策略
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
The debate about where databases should run in Kubernetes has been a hot topic in the tech community. The prevailing argument is about “building stateless applications,” suggesting that databases are best suited as managed services with cloud providers. However, there are practical design patterns for successfully running databases in Kubernetes.
On most cloud providers, volumes are constrained to a single Availability Zone (AZ), which means the databases are also constrained to that AZ by design. Most production clusters are likely regional or multi-AZ, especially for stateless applications. Using node selectors to ensure the database pods are located in the AZs where their volumes can be mounted is important.
Example:
|
nodeSelector: topology.kubernetes.io/zone: europe–west6–b |
This configuration specifies that the database pod should run in the ‘europe-west6-b’ AZ.
Plan Resource Usage
Since our databases are constrained to one AZ, we must carefully plan our node-to-AZ design to avoid scheduling errors and unavailability issues. One effective strategy is to run separate node groups or node pools specifically for database workloads. This ensures that sufficient resources are always available in the required AZ.
Example:
- Create a dedicated node pool for database workloads.
- Use taints and tolerations to ensure only database pods are scheduled on these nodes.
|
# Taint nodes to be dedicated to databases
spec: taints: – key: “dedicated” value: “database” effect: “NoSchedule”
# Toleration in the DB pod spec spec: tolerations: – key: “dedicated” operator: “Equal” value: “database” effect: “NoSchedule” |
High Availability
Managed database services often provide built-in high availability and failover capabilities. To achieve similar resilience in Kubernetes, meticulous planning for recovery and availability strategies is essential. Here are two approaches:
Using Kubernetes Operators:
Kubernetes operators like the Zalando Postgres Operator offer advanced features like read replicas and automatic failovers, similar to managed database services. These operators can significantly simplify the setup and management of high availability for your databases.
The Zalando Postgres Operator allows you to specify the number of read replicas and automatically manages failovers. This operator provides a UI where you can configure these settings, making it an intuitive and powerful tool for managing database high availability in Kubernetes. Here is a list of some other Operators, some of which are managed by their respective communities
Self-Service Approach:
For those who prefer a more hands-on approach, particularly for NoSQL databases, here’s a step-by-step method:
- Mount Data Volumes on Both Pods: Ensure that the data volume is accessible by both the primary and secondary pods.
- Pod Affinity: Use pod affinity rules to ensure that the primary and secondary pods are placed together, respecting volume constraints.
- Init Container: At startup, use an init container in the secondary pod to copy all data from the primary pod.
- Volume Mount Constraint: Set the volume mount on the secondary pod to read-only to prevent data corruption.
- Use cronjob for restarts: Create a simple CronJob that deletes the old pod every six hours, allowing the init container to run and copy new data.
Example Configurations
The example below shows how to set up a Neo4j read replica using pod affinity, an init container for data copying, and mount volumes with read-only constraints to ensure data integrity.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: – labelSelector: matchExpressions: – key: app operator: In values: – primary–db topologyKey: “kubernetes.io/hostname”
initContainers: – name: copy–data image: busybox command: [“sh”, “-c”, “cp -r /data/* /backup/”] volumeMounts: – name: data–volume mountPath: /data – name: backup–volume mountPath: /backup
volumes: – name: data–volume persistentVolumeClaim: claimName: primary–db–pvc – name: backup–volume persistentVolumeClaim: claimName: secondary–db–pvc
containers: – name: secondary–db image: neo4j:latest volumeMounts: – name: backup–volume mountPath: /data readOnly: true |
Backups and Restore
Many service providers offer ways to schedule recurring snapshots on disk-based volumes. This is often the preferred method because it is easier to set up, and the recovery process is faster. We can back up the volumes hosting the DB data regularly in this scenario.
Another approach involves combining the database’s proprietary tools, such as pg_dump for PostgreSQL.
Here is an example Configuration for PostgreSQL using Kubernetes Cron Jobs to backup to s3
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
apiVersion: batch/v1beta1 kind: CronJob metadata: name: postgres–backup spec: schedule: “0 0 * * *” jobTemplate: spec: template: spec: containers: – name: backup image: postgres command: [“sh”, “-c”, “pg_dumpall -c -U $PGUSER | gzip > /backup/db_backup.gz && aws s3 cp /backup/db_backup.gz s3://your-bucket/db-backup-$(date +\%F).gz”] volumeMounts: – name: backup–volume mountPath: /backup restartPolicy: OnFailure volumes: – name: backup–volume emptyDir: {} |
Summary
Even though the initial setup or learning curve might be steep, running your database in Kubernetes provides plenty of advantages. One not-so-talked-about benefit is cost. Running a db.m4.2xlarge (4vCPUs, 32GB RAM) instance in RDS costs approximately $1200/month, while running a similarly sized EC2 instance costs around $150/month. A node in Kubernetes will likely also run more than one pod, further optimizing resource use.
Vendor agnosticism is another key motivation for many people running databases in Kubernetes. Moving your workloads across any platform with minimal tweaks is incredibly appealing.
In conclusion, consider the pros and cons before deciding where to run your production database. Many people successfully run their databases in Kubernetes, and the number of such deployments is growing daily.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.