
包阅导读总结
1. 关键词:Vector Databases、Similarity Search、Use Cases、Building Applications、Challenges
2. 总结:本文是初学者关于向量数据库的指南,介绍了其核心概念,包括向量、相似性搜索等,列举了多种应用场景,如图像和视频搜索、推荐系统等,阐述了构建应用的要点,还提到面临的挑战及最佳实践,指出其带来范式转变但也有局限。
3. 主要内容:
– 理解向量数据库:
– 向量是由数字组成,可代表多种信息,维度越多能表示的信息越复杂。
– 向量数据库擅长相似性搜索,不同于传统数据库的精确匹配。
– 与传统数据库对比,向量数据库专为处理非结构化数据设计。
– 具有速度、可扩展性、灵活性和准确性等优点。
– 向量数据库的应用场景:
– 图像和视频搜索,包括相似搜索、对象检测等。
– 推荐系统,如产品和内容推荐、用户相似性识别。
– 欺诈检测,如异常检测等。
– 自然语言处理,包括语义搜索等。
– 其他行业应用,如电商、金融等。
– 构建向量数据库应用:
– 选择数据库时要考虑开源与管理、可扩展性等因素。
– 数据准备和向量化,包括数据清洗等步骤。
– 索引和查询优化,考虑索引类型等。
– 与其他系统集成,如数据管道等。
– 挑战和考虑因素:
– 局限性包括硬件要求、数据量处理等。
– 挑战有数据准备、索引选择等。
– 最佳实践包括保证数据质量等。
– 结论:向量数据库带来范式转变,要了解其优缺点,精心准备和优化以实现最佳性能和准确性。
思维导图: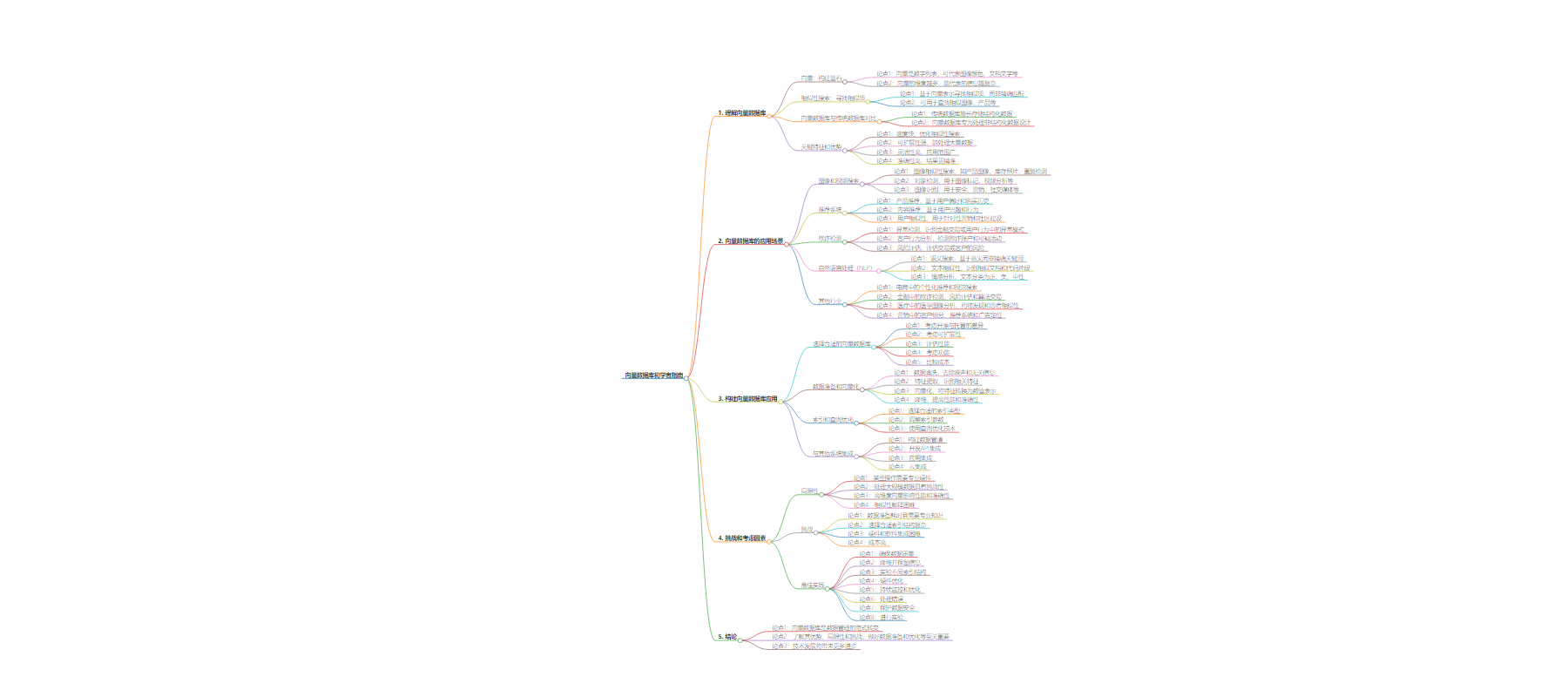
文章地址:https://www.javacodegeeks.com/2024/08/diving-into-vector-databases-a-beginners-guide.html
文章来源:javacodegeeks.com
作者:Eleftheria Drosopoulou
发布时间:2024/7/29 12:11
语言:英文
总字数:1403字
预计阅读时间:6分钟
评分:87分
标签:矢量数据库,数据管理,相似搜索,人工智能应用,机器学习
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Vector databases are emerging as a critical tool for handling complex data structures and enabling advanced search functionalities. Unlike traditional relational databases that store structured data, vector databases excel at storing and searching data represented as numerical vectors. This guide will introduce you to the world of vector databases, explaining their core concepts, use cases, and how to get started with building your first vector database application.
Whether you’re a seasoned data engineer or a curious developer, this article will provide you with a solid foundation to explore the potential of vector databases.
1. Understanding Vector Databases
Vectors: The Building Blocks
Imagine a vector as a list of numbers. These numbers can represent anything from the color of an image to the words in a document. For example, a vector for an image might look like this: [0.1, 0.2, 0.3, …]. Each number in the list is called a dimension. The more numbers (or dimensions) a vector has, the more complex the information it can represent.
Similarity Search: Finding What’s Similar
The magic of vector databases lies in their ability to find items that are similar to each other. Instead of searching for exact matches, like you would with a traditional database, vector databases can find items that are “close” to each other based on their vector representation. This is called similarity search. For instance, you could find images similar to a given image, or products similar to one a customer liked.
Vector Databases vs. Traditional Databases
Traditional databases store information in rows and columns, perfect for structured data like names, addresses, or numbers. But they struggle with unstructured data like images, text, or audio. Vector databases, on the other hand, are designed specifically to handle this kind of data. They store data as vectors and can quickly find similar items based on their vector representation.
Key Features and Benefits of Vector Databases
- Speed: Vector databases are optimized for similarity search, making them incredibly fast at finding similar items.
- Scalability: They can handle massive amounts of data and billions of vectors.
- Flexibility: They can be used for a wide range of applications, from image search to recommendation systems.
- Accuracy: They often deliver more accurate results than traditional search methods.
In essence, vector databases are like a new tool in the data scientist’s toolbox. They open up possibilities for innovative applications that were previously difficult or impossible to achieve.
2. Use Cases for Vector Databases
Vector databases have a wide range of applications across various industries. Let’s explore some of the most common use cases.
Image and Video Search
- Image similarity search: Find visually similar images, such as product images, stock photos, or duplicate detection.
- Object detection: Identify objects within images or videos, enabling applications like image tagging, video analysis, and augmented reality.
- Image recognition: Recognize faces, landmarks, or other objects in images for security, marketing, or social media applications.
Recommendation Systems
- Product recommendations: Suggest products based on user preferences, purchase history, and item similarity.
- Content recommendations: Recommend articles, videos, or music based on user interests and behavior.
- User similarity: Identify users with similar preferences for targeted marketing or community building.
Fraud Detection
- Anomaly detection: Identify unusual patterns in financial transactions or user behavior to detect fraudulent activities.
- Customer behavior analysis: Detect fraudulent accounts or suspicious activity based on user behavior patterns.
- Risk assessment: Evaluate the risk associated with transactions or customers.
Natural Language Processing (NLP)
- Semantic search: Find documents or information based on meaning rather than exact keywords.
- Text similarity: Identify similar documents or code snippets.
- Sentiment analysis: Analyze text sentiment and classify it as positive, negative, or neutral.
Drug Discovery
- Molecular similarity: Find molecules with similar properties for drug discovery.
- Protein structure analysis: Analyze protein structures to identify potential drug targets.
Other Industries
- E-commerce: Personalized product recommendations, visual search.
- Finance: Fraud detection, risk assessment, algorithmic trading.
- Healthcare: Medical image analysis, drug discovery, patient similarity.
- Marketing: Customer segmentation, recommendation systems, ad targeting.
These are just a few examples of how vector databases can be applied across different industries. The possibilities are vast, and as technology advances, we can expect to see even more innovative use cases emerge.
3. Building a Vector Database Application
Selecting the appropriate vector database is crucial for the success of your project. Key factors to consider include:
- Open-source vs. managed: Open-source databases offer flexibility and control, while managed services provide scalability, maintenance, and support.
- Scalability: Consider your expected data volume and growth rate. The database should be able to handle increasing amounts of data efficiently.
- Performance: Evaluate query latency and throughput requirements. Some databases are optimized for specific workloads.
- Features: Assess the database’s capabilities, such as indexing techniques, similarity search algorithms, and integration options.
- Cost: Compare pricing models and total cost of ownership for both open-source and managed options.
Data Preparation and Vectorization
Before feeding data into a vector database, it needs to be transformed into numerical vectors. This process involves:
- Data cleaning: Removing noise, inconsistencies, and irrelevant information from the data.
- Feature extraction: Identifying relevant features or attributes from the data.
- Vectorization: Converting features into numerical representations.
- Dimensionality reduction: Reducing the number of dimensions in vectors to improve performance and accuracy.
Indexing and Query Optimization
Efficient indexing is essential for fast similarity search. Key considerations include:
- Index type: Choose the appropriate index structure (e.g., HNSW, Annoy) based on your data characteristics and query patterns.
- Index parameters: Fine-tune index parameters to optimize search performance.
- Query optimization: Use techniques like filtering, ranking, and approximate nearest neighbor search to improve query efficiency.
Integrating Vector Search with Other Systems
To leverage the power of vector databases, you often need to integrate them with other systems. Consider the following:
- Data pipelines: Build pipelines to ingest and process data before feeding it into the vector database.
- API integration: Develop APIs to expose vector search capabilities to other applications.
- Application integration: Integrate vector search into your application’s logic.
- Cloud integration: Utilize cloud platforms for infrastructure, storage, and compute resources.
By carefully considering these factors, you can build a robust and efficient vector database application that delivers value to your users.
4. Challenges and Considerations
While vector databases offer significant advantages, they also come with certain limitations and challenges.
Limitations
- Specialized hardware: Some vector database operations can be computationally intensive, requiring specialized hardware like GPUs or specialized processors for optimal performance.
- Data volume: Handling massive datasets can be challenging, requiring efficient storage and indexing strategies.
- Dimensionality: High-dimensional vectors can impact search performance and accuracy.
- Explainability: Understanding why certain items are returned as similar can be difficult, especially in complex models.
Challenges
- Data preparation: Transforming data into high-quality vector representations can be time-consuming and requires domain expertise.
- Index selection: Choosing the right index structure for optimal performance can be complex.
- Hardware and software integration: Integrating vector databases with existing systems and infrastructure can be challenging.
- Cost: Deploying and maintaining a vector database can be expensive, especially for large-scale applications.
Best Practices for Vector Database Implementation
| Best Practice | Description |
|---|---|
| Data Quality | Ensure data is clean, consistent, and relevant to avoid impacting vector quality. |
| Dimensionality Reduction | Apply techniques like PCA or t-SNE to reduce dimensionality while preserving information. |
| Index Selection | Experiment with different index structures (HNSW, Annoy, IVF) to find the best fit for your data and query patterns. |
| Hardware Optimization | Leverage specialized hardware like GPUs or vector processing units for performance gains. |
| Monitoring and Optimization | Continuously monitor system performance and adjust parameters as needed. |
| Error Handling | Implement robust error handling mechanisms to prevent data loss and system failures. |
| Security | Protect sensitive data with appropriate security measures. |
| Experimentation | Test different approaches and configurations to find the optimal solution for your specific use case. |
By addressing these challenges and following best practices, you can maximize the benefits of vector databases and build successful applications.
5. Conclusion
Vector databases represent a paradigm shift in data management, offering powerful capabilities for handling complex, unstructured data. By understanding the core concepts, exploring diverse use cases, and effectively implementing vector databases, organizations can unlock new insights and create innovative applications.
While vector databases offer significant advantages, it’s essential to be aware of their limitations and challenges. Careful data preparation, index optimization, and hardware considerations are crucial for achieving optimal performance and accuracy.
As technology continues to evolve, we can expect even more advancements in vector database capabilities. By staying informed about emerging trends and best practices, you can harness the full potential of vector databases to drive business growth and innovation.