
包阅导读总结
1. 关键词:
– RAG
– 函数调用
– 电商公司
– 向量数据库
– 联邦语言模型
2. 总结:
本文介绍了如何构建结合 RAG 和函数调用的电商分析代理,包括启动数据库和 API 服务器、索引 PDF 并存储向量、运行代理的步骤,还提及可扩展为使用联邦语言模型,最后引导关注相关频道。
3. 主要内容:
– 构建基于 RAG 和函数调用的代理
– 结合二者优势,依靠外部知识库准确检索数据和执行特定功能高效完成任务。
– 为电商公司产品经理构建分析销售和产品组合的代理
– 利用检索器从 PDF 提取无结构数据的上下文,调用 API 获取销售信息。
– 代理能访问工具集和向量数据库,根据情况执行工具或在向量数据库中检索并获取上下文。
– 配置代理的步骤
– 克隆仓库。
– 启动数据库和 API 服务器,暴露四个 API 端点。
– 索引 PDF 并将向量存储在 ChromaDB 中。
– 运行 RAG 代理。
– 扩展 RAG 代理
– 提及可依靠联邦模型避免向云 LLM 发送上下文,使用本地 LLM 响应查询,并预告相关内容。
思维导图:
文章地址:https://thenewstack.io/how-to-build-an-ai-agent-that-uses-rag-to-increase-accuracy/
文章来源:thenewstack.io
作者:Janakiram MSV
发布时间:2024/7/29 19:19
语言:英文
总字数:1215字
预计阅读时间:5分钟
评分:88分
标签:AI 代理,RAG,函数调用,电子商务,大型语言模型
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
The combination of retrieval augmented generation (RAG) and function calls can greatly improve the capabilities of LLM-based applications. RAG agents based on function calling combine the benefits of both approaches, relying on external knowledge bases for accurate data retrieval and executing specific functions for efficient task completion.
Function calling within the RAG framework enables more structured retrieval processes. For example, a function can be predefined to extract specific information based on user queries, which the RAG system will retrieve from a comprehensive knowledge base. This method ensures that the responses are both relevant and precisely tailored to the application’s requirements.
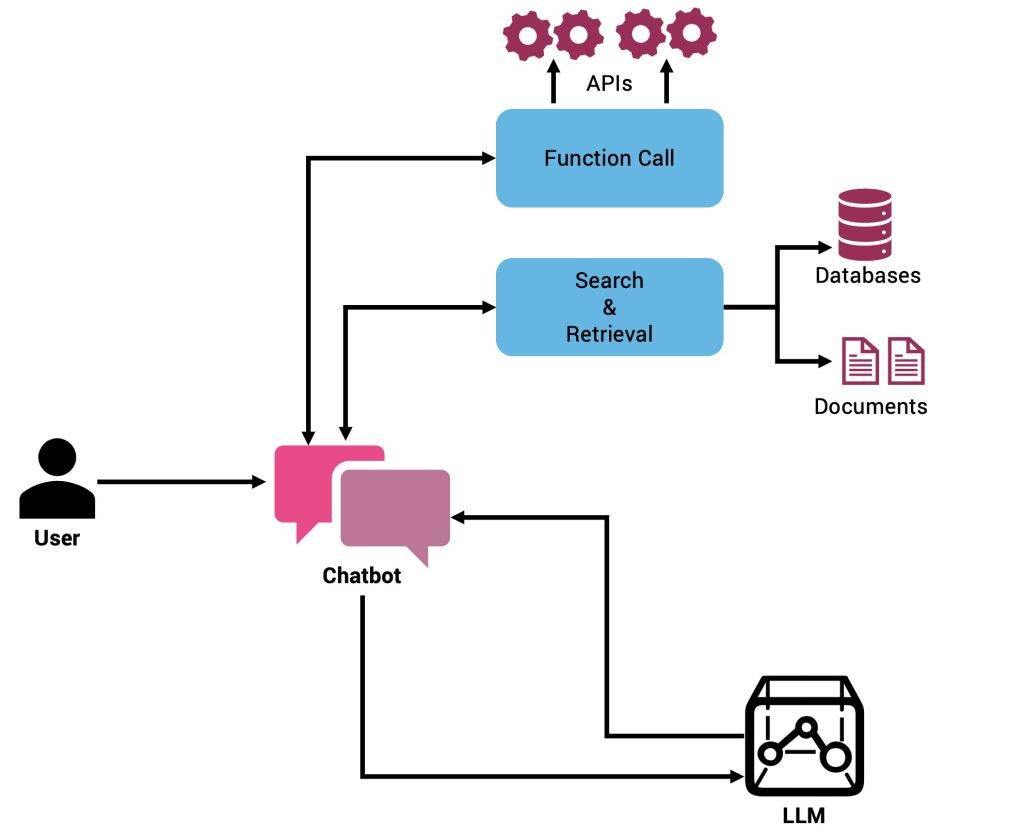
In this tutorial, we will build an agent that’s designed to help the product manager of an ecommerce company analyze sales and the product portfolio. It uses a retriever to extract context from unstructured data stored in PDFs, while invoking an API to get sales information.
The agent has access to a set of tools and also to a vector database. The initial prompt and the registered tools are sent to the LLM. If the LLM response includes a subset of tools, the agent executes them and collects the context. If the LLM doesn’t recommend executing any of the tools, the agent then performs a semantic search in the vector database and retrieves the context. Irrespective of where the context is gathered from, it is added to the original prompt and sent to the LLM.
To simplify the configuration, I created a Docker Compose file to run the MySQL database and Flask API layers. The PDFs are indexed separately and ingested into ChromaDB. It’s assumed that you have access to the OpenAI environment.
Start by cloning the Git repository and follow the steps below to configure the agent on your machine.
|
git clone https://github.com/janakiramm/rag–agent.git |
Step 1: Launch the DB and the API server
Switch to the api directory and run the Docker Compose file to launch the database and the corresponding API server.
|
docker compose up –d —build |
The API server exposes four API endpoints:
get_top_selling_productsget_top_categoriesget_sales_trendsget_revenue_by_category
You can invoke these endpoints from curl.
|
curl “http://localhost:5000/api/sales/top-products?start_date=2023-04-01&end_date=2023-06-30” |
|
curl “http://localhost:5000/api/sales/top-categories?start_date=2023-04-01&end_date=2023-06-30” |
|
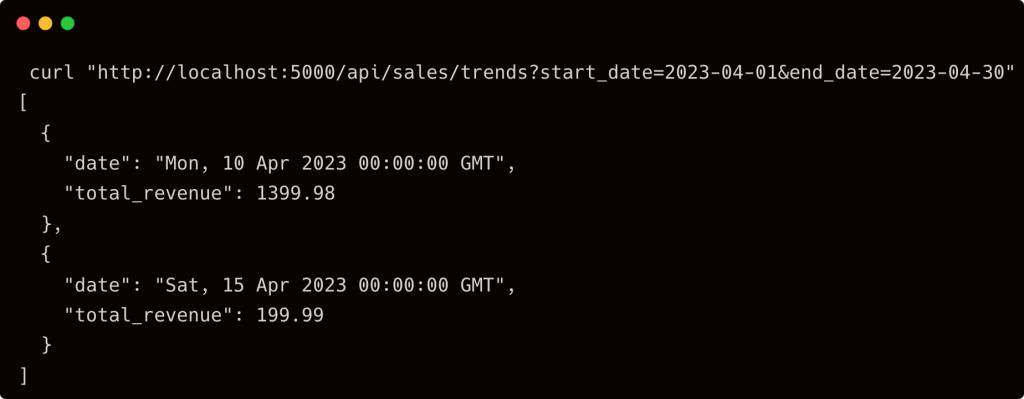
curl “http://localhost:5000/api/sales/trends?start_date=2023-04-01&end_date=2023-06-30” |
|
curl “http://localhost:5000/api/sales/revenue-by-category?start_date=2023-04-01&end_date=2023-06-30” |
Step 2: Index PDFs and Store Vectors in Chroma DB
Under the data directory, you will find a PDF that contains a description of a few products from the electronics category. Our task is to index it and store the embedding vectors in Chroma.

For this, launch the Index-Datasheet Jupyter Notebook and run all the cells.
This loads the PDF, performs chunking, generates the embeddings and finally stores the vectors in ChromaDB.
The last cell of this Notebook performs a simple semantic search to validate the indexing process.
Now, we have two entities that can help us get the context: 1) API, and 2) vector database.
Step 3: Run the RAG Agent
The agent code is available in the RAG-Agent Jupyter Notebook. Launch it and run all the cells to see it in action.
This Notebook contains the logic to decide between executing the tools and performing a semantic search.
I wrapped the REST API calls within the tools.py which is available in the root directory of the repo, which we import into the agent.
|
from tools import ( get_top_selling_products, get_top_categories, get_sales_trends, get_revenue_by_category ) |
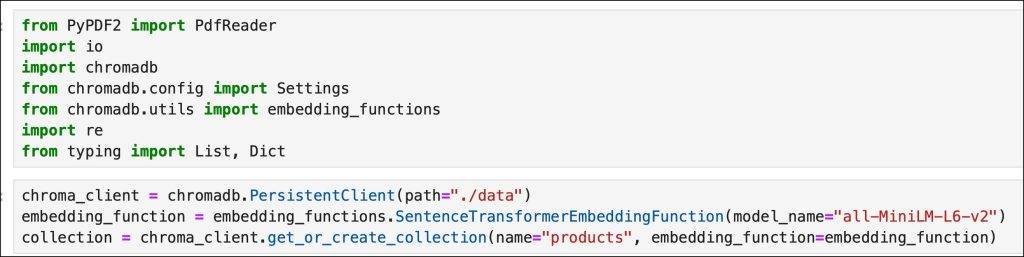
Since we decided to persist the Chroma collection from the indexing process performed in the previous step, we will simply load it.
|
chroma_client = chromadb.PersistentClient(path=“./data”) embedding_function = embedding_functions.SentenceTransformerEmbeddingFunction(model_name=“all-MiniLM-L6-v2”) collection = chroma_client.get_or_create_collection(name=“products”, embedding_function=embedding_function) |
Based on the available tools, we pass them along with the prompt to the LLM to map. The LLM then recommends the right functions to invoke. Below is a partial code snippet from the map_tools function.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
…. messages = [{“role”: “user”, “content”: prompt}] response = llm.chat.completions.create( model=model, messages=messages, tools=tools, tool_choice=“auto” )
# Ensure response has valid tool_calls response_message = response.choices[0].message tool_calls = getattr(response_message, ‘tool_calls’, None)
functions = [] if tool_calls: for tool in tool_calls: function_name = tool.function.name arguments = json.loads(tool.function.arguments) functions.append({ “function_name”: function_name, “arguments”: arguments })
return functions |
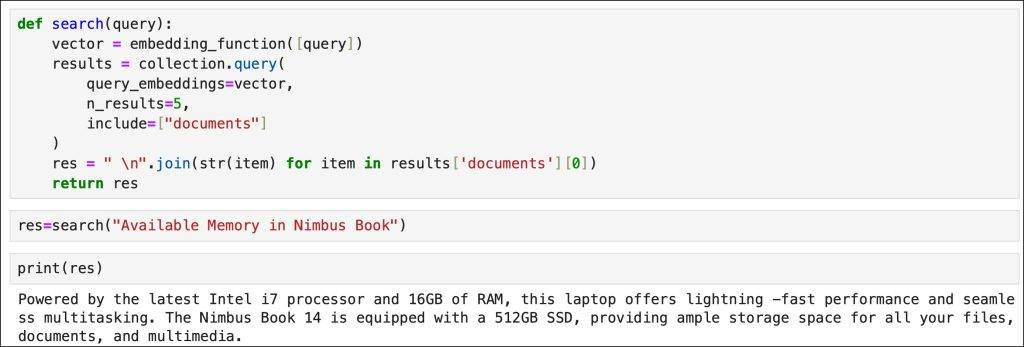
Similarly, we have a retriever responsible for extracting the context from the vector database.
|
def retriever(query): vector = embedding_function([query]) results = collection.query( query_embeddings=vector, n_results=5, include=[“documents”] ) res = ” \n”.join(str(item) for item in results[‘documents’][0]) return res |
We have a simple helper function to send the gathered context and the original prompt to the LLM.
|
def generate_response(prompt,context): input_text = ( “Based on the below context, respond with an accurate answer. If you don’t find the answer within the context, say I do not know. Don’t repeat the question\n\n” f“{context}\n\n” f“{prompt}” ) response = llm.chat.completions.create( model= model, messages=[ {“role”: “user”, “content”: input_text}, ], max_tokens=150, temperature=0 )
return response.choices[0].message.content.strip() |
The job of the agent is to first check whether the LLM recommends any tools and then execute them to generate the context. If not, it relies on the vector database to generate the context.
|
def agent(prompt): tools = map_tools(prompt)
if tools: tool_output = execute_tools(tools) context = json.dumps(tool_output) else: context = retriever(prompt)
response = generate_response(prompt, context) return response |
In the below screenshot, the first response is coming from the tools/API and the second from the vector database.

Extending RAG Agent to Use Federated Language Models
In this scenario, we relied on OpenAI’s GPT-4o for mapping the function calls and generating the final response based on the context. By relying on the idea of federated models, we can entirely avoid sending the context to the cloud-based LLM and use a local LLM deployed at the edge to respond to queries.
In my next post (the last and final part of this series), we will see how to combine the idea of the RAG agent with federated language models. Stay tuned.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.