
包阅导读总结
1.
关键词:Anthropic、API、提示词缓存、成本降低、延迟缩短
2.
总结:Anthropic 在其 API 引入新的提示词缓存机制,可大幅降低长提示成本和延迟。该功能已在部分模型开放测试,有多种优势,虽有一定限制但被认为应成行业标配,代表了 AI 交互效率的重大飞跃。
3.
主要内容:
– Anthropic 的新举措
– 在 API 上引入提示词缓存机制
– 降低长提示成本多达 90%,延迟降低 80%
– 提示词缓存的功能特点
– 记住 API 调用间的上下文,避免重复输入提示内容
– 已在 Claude 3.5 Sonnet 等中以测试版开放,Opus 未支持
– 提示词缓存的优势
– 降低成本,如 Claude 3.5 Sonnet 初次输入和调用缓存成本差异大
– 加快响应速度,更好微调模型响应
– 潜在效果包括降低多种场景成本和延迟等
– 与其他方案比较
– 相比 RAG 等有简单、一致、速度等优势
– 相比具有扩展上下文窗口的模型有成本效益等优势
– 行业反响
– 其他平台也有类似版本
– 网友认为应成行业标配,独立评估显示成本节省显著
思维导图: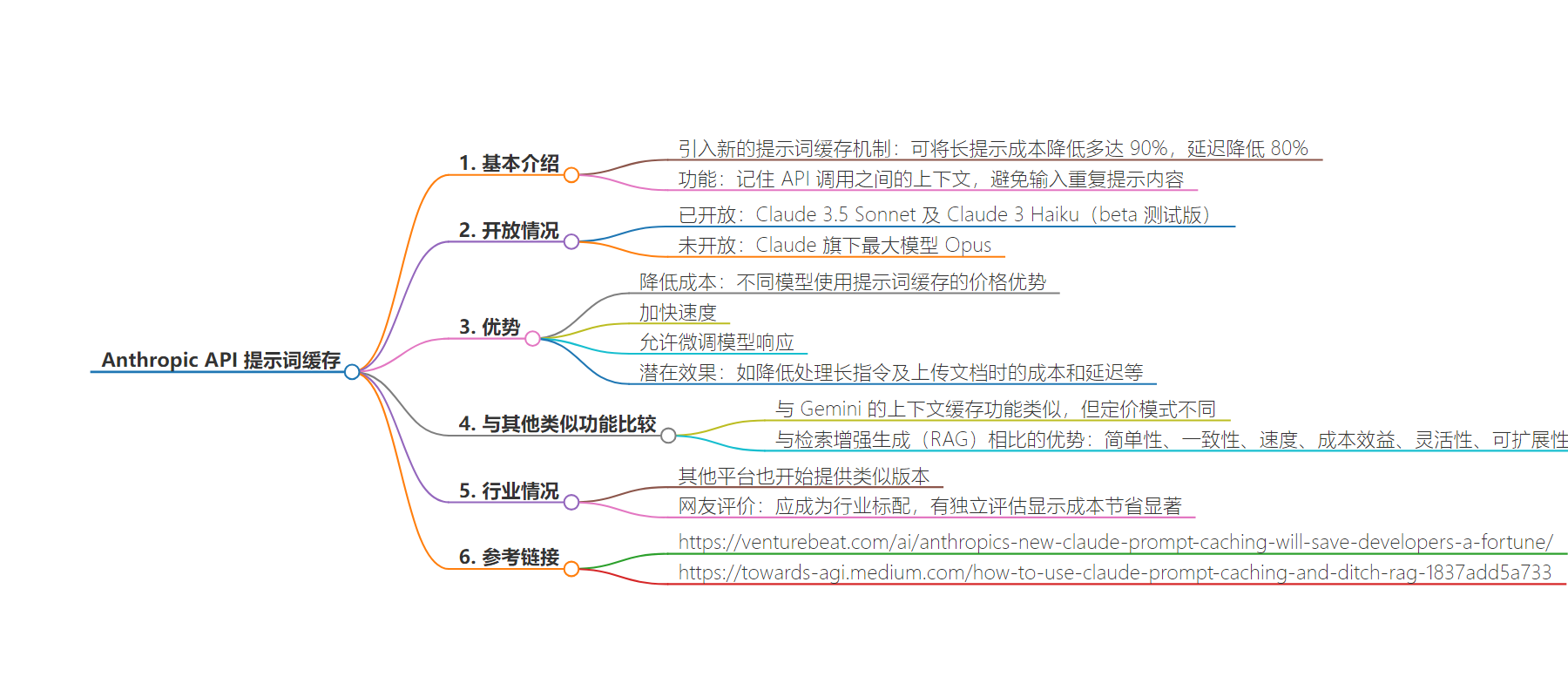
文章地址:https://mp.weixin.qq.com/s/6Ns8F0qmsnVc536D8nunMA
文章来源:mp.weixin.qq.com
作者:InfoQ 中文
发布时间:2024/8/18 2:40
语言:中文
总字数:2111字
预计阅读时间:9分钟
评分:91分
标签:提示词缓存,API优化,成本降低,延迟缩短,Anthropic
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Anthropic 在其 API 上引入了新的提示词缓存机制,可将长提示的成本降低多达 90%,并将延迟降低 80%。
提示词缓存功能能够记住 API 调用之间的上下文,并帮助开发人员避免输入重复提示内容。目前该功能已经在 Claude 3.5 Sonnet 以及 Claude 3 Haiku 当中以 beta 测试版的形式开放,但对 Claude 旗下最大模型 Opus 的支持仍未交付。

提示词缓存的概念源自 2023 年的研究论文,其允许用户在会话中保留常用的上下文。由于模型能够记住这些提示词,因此用户可以添加额外的背景信息而不必重复承担成本。这一点对于需要在提示词中发送大量上下文,并在与模型的不同对话中多次引用的使用场景非常重要。它还允许开发人员及其他用户更好地对模型响应作出微调。
Anthropic 表示,早期用户“已经在多种用例中观察到,使用提示词缓存后速度及成本都出现了显著改善——测试范围从完整知识库到 100 个样本示例,再到在提示词中包含对话的每个轮次。”
该公司表示,提示词缓存的潜在效果包括降低对话智能体在处理长指令及上传文档时的成本和延迟、加快代码的自动补全速度、向智能体搜索工具提交多条指令,以及在提示词中嵌入完整文档等等。

Anthropic 刚刚公布了一项改变其 API 游戏规则的功能:提示词缓存。 大家可以这样理解提示词缓存的概念:你选中了一家咖啡厅。第一次光顾时,我们需要逐个挑选出自己喜欢的品类。而下次到店时,直接说“老样子”就好。
提示词缓存的主要优势在于每 token 的价格较低,Anthropic 表示使用这项功能要比“直接输入 token 便宜得多”。
以 Claude 3.5 Sonnet 为例,初次输入提示词时每 100 万 token(MTok)的成本为 3.75 美元,但随后调用缓存提示词的每百万 Token 成本仅为 0.30 美元。Claude 3.5 Sonnet 模型的基础提示词输入价格为每百万个 3 美元,也就是说只要预先多付一点钱,那么在下次使用缓存提示词时就能将成本压低至十分之一。
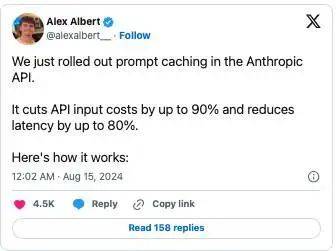
我们刚刚在 Anthropic API 中推出了提示词缓存功能。 它能够将 API 的输入成本降低 90%,并将延迟降低 80%。
说到成本,尽管初始 API 调用会稍贵一些(毕竟需要将提示词存储在缓存当中),但一切后续调用都只是正常输入价格的十分之一。

Claude 3 Haiku 用户使用提示词缓存时每百万 token 时需要额外支付 0.30 美元,而在调用已缓存提示词时每百万 token 价格仅为 0.03 美元。
虽然 Claude 3 Opus 尚未提供提示词缓存,但 Anthropic 已经提前公布了具体价格。写入缓存的价格是每百万 token 18.75 美元,而访问已缓存提示词的每百万 token 价格为 1.50 美元。
然而,正如 AI 意见领袖 Simon Willison 在 X 上发帖所言,Anthropic 的缓存只有 5 分钟的生命周期,而且每次使用时都会刷新。
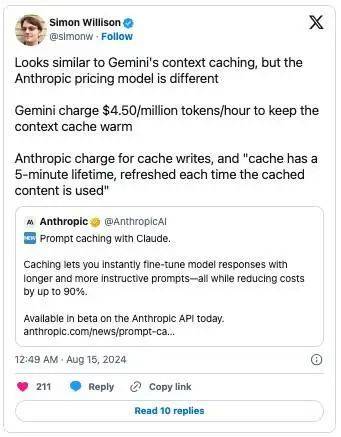
这看起来跟 Gemini 的上下文缓存功能类似,只是 Anthropic 提出了独立的定价模式。 Gemini 为百万个 token 每小时收取 4.50 美元的费用,即可保持上下文缓存。 Anthropic 直接对缓存输入量收费,而且“缓存的生命周期只有 5 分钟,且每次使用缓存内容时都会刷新”。
当然,这也绝不是 Anthropic 第一次尝试通过定价手段跟其他 AI 平台竞争了。在发布 Claude 3 系列模型之前,Anthropic 就曾大幅下调过其 token 的计费标准。
在当初为自家平台上的第三方开发商提供低价选项之后,现如今他们再次针对谷歌和 OpenAI 等竞争对手展开一场“比比谁价低”的烈性对抗。
为 Claude 模型引入提示缓存代表了 AI 交互效率的重大飞跃。尤其是在考虑诸如检索增强生成(RAG)或其他长上下文模型等替代方案时,其重要性不容忽视。
虽然 RAG 一直是通过外部知识增强 AI 模型的一种流行方法,但 Claude 的提示缓存提供了几个优势:
-
简单性:不需要复杂的向量数据库或检索机制
-
一致性:缓存的信息始终可用,确保一致的响应
-
速度:所有信息都可以立即访问,响应速度更快
与具有扩展上下文窗口的模型(如谷歌的 Gemini Pro)相比,Claude 的提示缓存提供了以下优势:
-
成本效益:只需为使用的部分付费,而不是为整个上下文窗口付费
-
灵活性:可以轻松更新或修改缓存信息,而无需重新训练
-
可扩展性:潜在的无限上下文大小,不受模型架构的限制
其他平台也开始提供类似的提示词缓存版本。Lamina 是一套大语言模型推理系统,尝试利用 KV 缓存来降低 GPU 使用成本。而随意浏览一下 OpenAI 的开发者论坛或者 GitHub,就会发现大量跟提示词缓存相关的话题。
提示词缓存跟大语言模型自己的提示词记忆并不是一回事。例如,OpenAI 的 GPT-4o 就提供记忆机制,模型可以借此记住用户的某些偏好或详细信息。但其无法像提示词缓存那样存储具体提示词及响应结果。
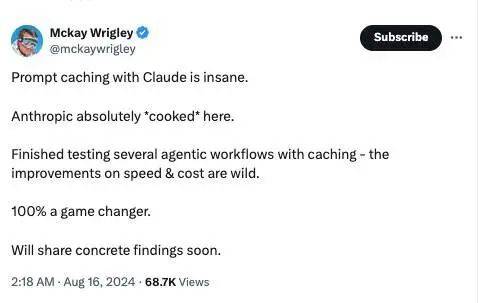
X 平台上对此的讨论也很多,有网友评价“提示词缓存”有 100% 的颠覆性,应该作为标准被每家大模型厂商采用。

还有网友对 AnthropicAI 提示缓存进行了独立评估——结果简直令人震惊,Claude 3.5 Sonnet 能做到 90% 的成本节省,而在 Claude 3 Haiku 上甚至能做到 97% 的成本节省。
展望未来,Claude 的提示缓存在推动更高效、更具成本效益的 AI 交互方面迈出了重要的一步。通过减少延迟、降低成本,并简化复杂知识的整合,这一功能为各行业的 AI 应用开辟了新的可能性。
参考链接:
https://venturebeat.com/ai/anthropics-new-claude-prompt-caching-will-save-developers-a-fortune/
https://towards-agi.medium.com/how-to-use-claude-prompt-caching-and-ditch-rag-1837add5a733
声明:本文由 InfoQ 翻译,未经许可禁止转载。