
包阅导读总结
1. 关键词:十万条数据、渲染、浏览器、性能优化、虚拟列表
2. 总结:本文探讨了在Web开发中一次性渲染十万条数据的问题及解决方法,从直接渲染到分批渲染、使用更好的技术和虚拟列表,逐步优化性能,避免浏览器卡顿,提高用户体验。
3. 主要内容:
– 一次性渲染十万条数据会导致浏览器卡顿和用户体验差
– 最直接方法:一次性创建所有列表项添加到DOM树,虽JS编译快但浏览器渲染慢,阻塞页面
– setTimeout分批渲染:分摊浏览器渲染压力,但可能因屏幕刷新率导致用户短暂看不到数据
– 使用requestAnimationFrame:避免setTimeout的问题,在屏幕刷新时渲染,更流畅
– 使用文档碎片:创建DocumentFragment暂存DOM节点,减少DOM操作次数提高性能
– 用虚拟列表:只渲染可视区域数据,用户滚动时替换,是处理大数据集的最佳实践
– 总结:介绍了从基本方法到现代技术的优化过程,希望对读者有帮助
思维导图:
文章地址:https://juejin.cn/post/7407763018471948325
文章来源:juejin.cn
作者:反应热
发布时间:2024/8/28 6:17
语言:中文
总字数:3673字
预计阅读时间:15分钟
评分:86分
标签:前端开发,性能优化,虚拟滚动,JavaScript,DOM操作
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
前言
当面试官问:给你十万条数据,你会怎么办? 这时我们该如何应对呢?
在实际的Web开发中,有时我们需要在页面上展示大量的数据,比如用户评论、商品列表等。如果一次性渲染太多的数据(如100,000条数据),直接将所有数据一次性渲染到页面上会导致浏览器卡顿,用户体验变差。下面我们从一个简单的例子开始,逐步改进代码,直到使用现代框架的虚拟列表技术来解决这个问题,看完本文后,你就可以跟面试官侃侃而谈了。
正文
最直接的方法
下面是最直接的方法,一次性创建所有的列表项并添加到DOM树中。
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title></head><body> <ul id="container"></ul> <script> let ul=document.getElementById('container'); const total=100000 let now=Date.now() for(let i=0;i<total;i++){ let li=document.createElement('li'); li.innerText=~~(Math.random()*total) ul.appendChild(li) } console.log('js运行耗时',Date.now()-now) setTimeout(()=>{ console.log('运行耗时',Date.now()-now) }) </script></body></html>效果:

可以看到圈圈转了一会
代码解释:
- 我们获取了一个
<ul>元素,并定义了一个总数total为1000,使用for循环来创建<li>元素,并给每个元素设置一个文本值,~~为向下取整, 每个新创建的<li>都被添加到<ul>元素中。 - 我们记录了整个过程的耗时,可以看到
js引擎在编译完代码只花了92ms还是非常快的。 - 而定时器耗时了
3038ms,我们知道js引擎是单线程工作的,首先它会执行同步代码,然后再执行微任务,接着再在浏览器上渲染,最后执行宏任务,setTimeout这里我们人为的写一个宏任务,这个打印的出来时间可以看成开始运行代码再到浏览器把数据渲染所花的时间对吧,可以看到还是要一会的对吧。
结论: 这种方法虽然实现起来简单直接,但由于它在一个循环中创建并添加了所有列表项至DOM树,因此在执行过程中,浏览器需要等待JavaScript完全执行完毕才能开始渲染页面。当数据量非常大(例如本例中的100,000个列表项)时,这种大量的DOM操作会导致浏览器的渲染队列积压大量工作,从而引发页面的回流与重绘,浏览器无法进行任何渲染操作,导致了所谓的“阻塞”渲染。
setTimeout分批渲染
为了避免一次性操作引起浏览器卡顿,我们可以使用setTimeout将创建和添加操作分散到多个时间点,每次只渲染一部分数据。
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title></head><body> <ul id="container"></ul> <script> let ul=document.getElementById('container'); const total=100000 let once= 20 let page=total/once let index=0 function loop(curTotal,curIndex){ let pageCount=Math.min(once,curTotal) setTimeout(()=>{ for(let i=0;i<pageCount;i++){ let li=document.createElement('li'); li.innerText=curIndex+i+':'+~~(Math.random()*total) ul.appendChild(li) } loop(curTotal-pageCount,curIndex+pageCount) }) } loop(total,index) </script></body></html>代码解释:
- 这里我们将所有数据分批渲染,每批次添加20个元素,因为到最后可能会不足20个所有我们用
Math.min(once,curTotal)取两者小的那个,如果还有剩余的元素需要添加,则递归调用loop函数继续处理,每次递归减去相应数量。 - 首先上来执行一遍,同步,异步,然后渲染,啥也没有渲染对吧,然后执行
setTimeout也就是宏任务,然后再向刚刚一样同步,异步,然后渲染,这时候可以渲染20条数据,接着再这样一直递归到数据加载完毕。
结论:
- 这里就是把浏览器渲染时的压力分摊给了
js引擎,js引擎是单线程工作的,先执行同步,异步,然后浏览器渲染,再宏任务,这里就很好的利用了这一点,把渲染的任务分批执行,减轻了浏览器一次要渲染大量数据造成的渲染“阻塞”,也很好的解决了数据过多时可能造成页面卡顿或白屏的问题, - 但是有点小问题,我们现在用的电脑屏幕刷新率基本上都是
60Hz,意味着它每秒钟可以刷新显示60次新的画面。如果我们以此为例计算,那么两次刷新之间的时间间隔大约是16.67毫秒,如果说当执行本次宏任务里的同步,异步,然后渲染这个时间点是在16.67ms以后也就是屏幕画面刚刷新完以后,是不是得等到下一次的16.67ms屏幕画面刷新才能有数据看到,所有当用户往下翻的时候有可能那一瞬间看不到东西,但是很快马上就有了,这个问题不是你迅速往下拉数据没加载那个,这个问题现在是不法完成避免的。
使用requestAnimationFrame
requestAnimationFrame是一个比setTimeout更优秀的解决方案,因为它就是屏幕刷新率的时间。
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title></head><body> <ul id="container"></ul> <script> let ul=document.getElementById('container'); const total=100000 let once= 20 let page=total/once let index=0 function loop(curTotal,curIndex){ let pageCount=Math.min(once,curTotal) requestAnimationFrame(()=>{ for(let i=0;i<pageCount;i++){ let li=document.createElement('li'); li.innerText=curIndex+i+':'+~~(Math.random()*total) ul.appendChild(li) } loop(curTotal-pageCount,curIndex+pageCount) }) } loop(total,index) </script></body></html>代码解释:
- 和使用
setTimeout类似,这里我们也使用分批处理。 - 不同之处在于使用了
requestAnimationFrame代替setTimeout,这使得操作更加流畅,就是在屏幕画面刷新的时候渲染,就避免了上面的问题。
结论: 通过requestAnimationFrame代替setTimeout,在屏幕画面刷新的时候渲染,就避免了上面setTimeout可能出现的问题。
使用文档碎片(requsetAnimationFrame+DocuemntFragment )
文档碎片是一种可以暂时存放DOM节点的“容器”,它不会出现在文档流中。当所有节点都准备好之后,再一次性添加到DOM中,可以减少DOM操作次数。
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title></head><body> <ul id="container"></ul> <script> let ul=document.getElementById('container'); const total=100000 let once= 20 let page=total/once let index=0 function loop(curTotal,curIndex){ let fragment =document.createDocumentFragment(); let pageCount=Math.min(once,curTotal) requestAnimationFrame(()=>{ for(let i=0;i<pageCount;i++){ let li=document.createElement('li'); li.innerText=curIndex+i+':'+~~(Math.random()*total) fragment.appendChild(li) } ul.appendChild(fragment) loop(curTotal-pageCount,curIndex+pageCount) }) } loop(total,index) </script></body></html>代码解释:
- 创建一个
DocumentFragment实例fragment来暂存<li>元素,在循环内部,将生成的<li>元素添加到fragment中,你可以理解为一个虚假的标签,把<li>挂在这个标签上,只不过这个标签不会出现在DOM中。 - 循环结束后,一次性将
fragment添加到<ul>元素中,这样就减少了DOM操作次数,提高了性能。
结论: 通过使用 DocumentFragment,可以在内存中暂存一组 DOM 节点,直到这些节点被一次性添加到 DOM 树中。这样做可以减少 DOM 的重排和重绘次数,从而提高性能这对于提高页面性能是非常重要的,尤其是在进行大量的DOM更新时。
用虚拟列表(Virtual List)
对于非常大的数据集,最佳实践是使用虚拟列表技术,现在很多公司都是用的这种方法。虚拟列表只渲染当前可视区域内的数据,当用户滚动时,替换这些数据。
这里使用vue实现一个简单的虚拟列表。

就两个文件
App.vue
<template> <div class="app"> <virtualList :listData="data"></virtualList> </div></template><script setup>import virtualList from './components/virtualList.vue'const data = []for (let i = 0; i < 100000; i++) { data.push({ id: i, value: i })}</script><style lang="css" scoped>.app { height: 400px; width: 300px; border: 1px solid #000; }</style>virtualList.vue
<template> <div ref="listRef" class="infinite-list-container" @scroll="scrollEvent()"> <div class="infinite-list-phantom" :style="{ height: listHeight + 'px' }"></div> <div class="infinite-list" :style="{ transform: getTransform }"> <div class="infinite-list-item" v-for="item in visibleData" :key="item.id" :style="{ height: itemSize + 'px', lineHeight: itemSize + 'px' }" > {{ item.value }} </div> </div> </div></template><script setup>import { computed, nextTick, onMounted, ref } from 'vue';const props = defineProps({ listData: Array, itemSize: { type: Number, default: 50 }});const state = reactive({ screenHeight: 0, startOffset: 0, start: 0, end: 0 });const visibleCount = computed(() => { return Math.ceil(state.screenHeight / props.itemSize); });const visibleData = computed(() => { return props.listData.slice(state.start, Math.min(state.end, props.listData.length)); });const listHeight = computed(() => { return props.listData.length * props.itemSize; });const getTransform = computed(() => { return `translateY(${state.startOffset}px)`; });const listRef = ref(null);onMounted(() => { state.screenHeight = listRef.value.clientHeight; state.end = state.start + visibleCount.value; });const scrollEvent = () => { const scrollTop = listRef.value.scrollTop; state.start = Math.floor(scrollTop / props.itemSize); state.end = state.start + visibleCount.value; state.startOffset = scrollTop - (scrollTop % props.itemSize); };</script><style lang="css" scoped>.infinite-list-container { height: 100%; overflow: auto; position: relative; }.infinite-list-phantom { position: absolute; left: 0; right: 0; top: 0; z-index: -1; }.infinite-list { position: absolute; left: 0; right: 0; top: 0; text-align: center; }.infinite-list-item { border-bottom: 1px solid #eee; box-sizing: border-box; }</style>效果:
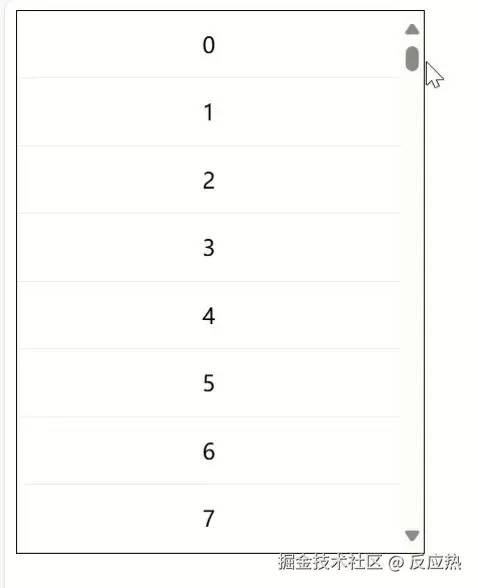
代码解释:
可视区域
<div ref="listRef" class="infinite-list-container" @scroll="scrollEvent()"></div>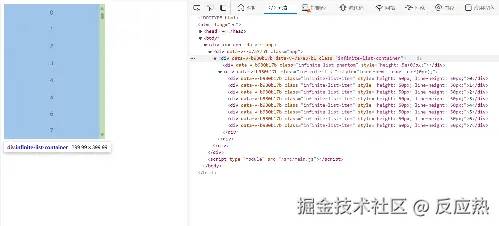
这个是可视的区域,就好比电脑和手机能看到东西的窗口大小,这是用户实际可以看到的区域,它有一个固定的大小,并且允许滚动
虚拟高度占位符
<div class="infinite-list-phantom" :style="{height: listHeight + 'px'}"></div>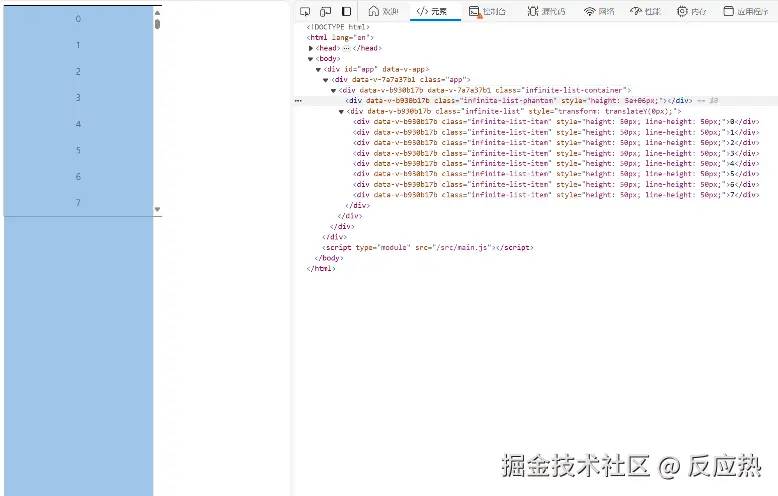 这个占位符的作用是模拟整个数据集的高度,即使实际上并没有渲染所有的数据项。它是一个不可见的元素,高度等于所有数据项的高度之和。
这个占位符的作用是模拟整个数据集的高度,即使实际上并没有渲染所有的数据项。它是一个不可见的元素,高度等于所有数据项的高度之和。
动态渲染数据的区域
<div class="infinite-list" :style="{transform: getTransform}"></div>
这部分负责实际显示数据项,和可视化的区域一样大,它通过 transform 属性调整位置,确保只显示当前可视区域内的数据项。
核心实现原理: 先拿到所有数据的占的区域,当往下滚动的时候,整个所有区域的数据会往上走(也就是这个div class="infinite-list-phantom"),而我们现在这个区域(div class="infinite-list")就是跟用户看到的数据区域一样大的区域也会往上滚,可以保证给的数据是正确的数据,当往上滚时,用户看到数据会更新并且会往上移动,变得越来越少,我们通过transform属性调整位置把它移动到我们固定的可视化的区域(div ref="listRef" class="infinite-list-container"),给用户看的数据就是完整的数据了。也就相当于我们这个有全部的虚假数据大小,我们只截取用户能看到的真实的部分数据给他们看。
结论: 虚拟列表的核心思想是只渲染当前可视区域的数据,而不是一次性渲染整个数据集。这在处理大数据量时尤为重要,因为它可以显著提高应用的性能和响应速度。
总结
通过上述五个方法,我们从最基本的DOM操作的方法到使用现代前端技术使用的方法,本文到此就结束了,希望对你有所帮助!感谢你的阅读!