
包阅导读总结
1. 系统异常、日志打印、fastjson、序列化、解决方式
2. 本文记录了新增一行日志打印导致系统主流程异常的问题,原因是 fastjson 自动执行对象新增的 getXXX 方法引发 NPE 异常,解决方法是修改方法命名,还探讨了 fastjson 序列化过程及相关问题。
3.
– 系统异常
– 新增一行日志打印导致系统主流程出现异常
– 错误日志显示与 fastjson 序列化相关
– 问题排查
– 对象中新增的 getXXX 方法内部未对字段合法性校验
– fastjson 序列化时默认自动执行对象的 getXXX 方法,因字段为 null 导致 NPE 异常
– 解决方式
– 将方法名「getDutyLevelNumber」替换为「fetchDutyLevelNumber」
– 介绍了其他几种解决自定义 get 方法被自动执行的方式
– fastjson 序列化过程
– 从 toJSONString 方法出发,分析其创建对象、获取序列化器、序列化等步骤
– 解析对象中的字段信息,生成 FieldInfo,最终执行 JavaBeanSerializer 的 write 方法触发 get 方法
– 思考与总结
– 探讨 fastjson 默认使用 getter 方法的原因及不足
4.
思维导图: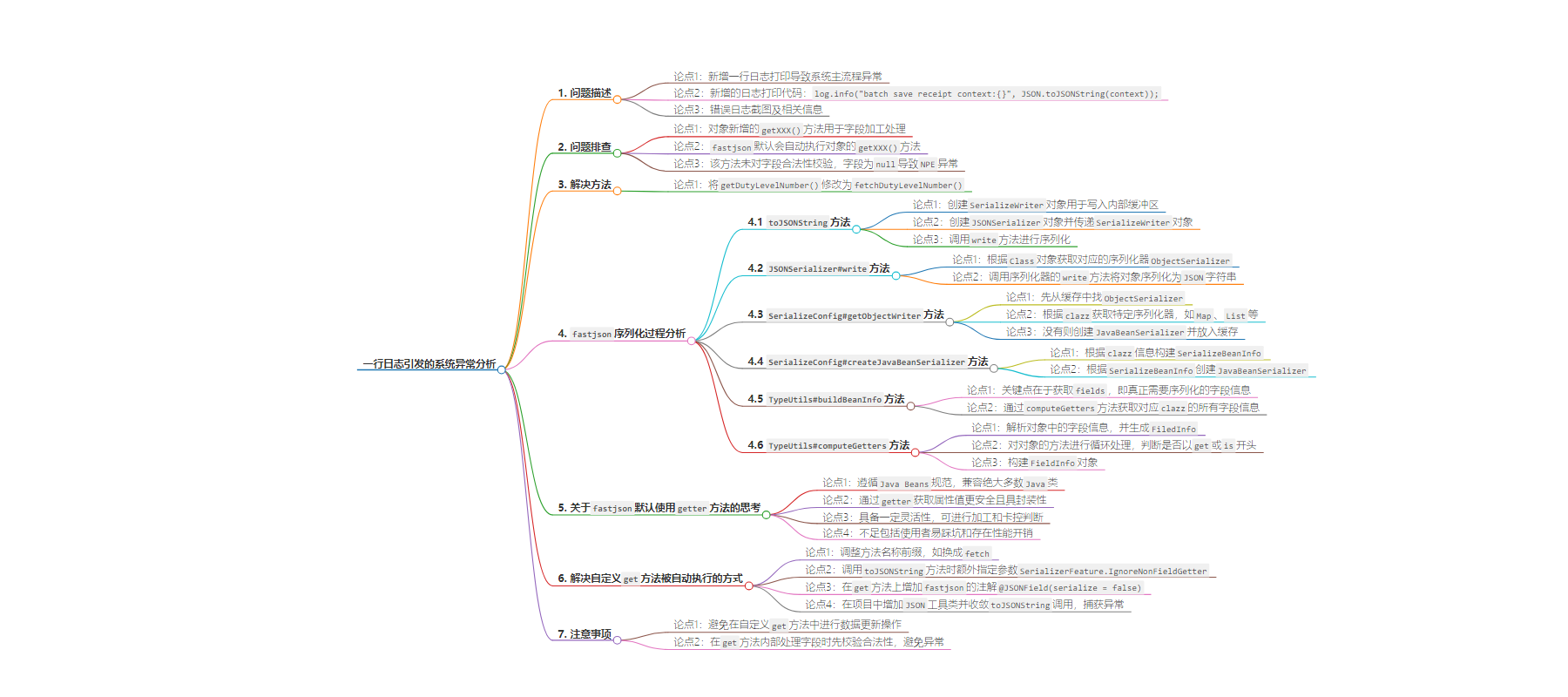
文章地址:https://mp.weixin.qq.com/s/fkKSARsOZrGjjE7R57PjUA
文章来源:mp.weixin.qq.com
作者:八帆
发布时间:2024/8/20 9:00
语言:中文
总字数:3343字
预计阅读时间:14分钟
评分:85分
标签:系统异常,日志打印,fastjson,序列化机制,Java开发
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

本文记录了一行日志引发的系统异常以及作者解决问题的思路。
在一次迭代开发过程中,新增了一行日志打印,导致系统主流程出现了异常。当时在想为何如此诡异,一行日志竟引发了 BUG。
新增的日志打印代码:
log.info("batch save receipt context:{}", JSON.toJSONString(context));下面是当时的错误日志截图:

2024-05-15 17:43:19.287|2132b44116764541988934881eca7a|[oms-thread-726]|ERROR|com.xxx.config.GlobalExceptionHandler|user_trace^xxxxx|1625792701351985152|## GlobalExceptionHandler,Host:33.xx.xx.xx invokes url:http:at com.alibaba.fastjson.serializer.JavaBeanSerializer.write(JavaBeanSerializer.java:544)at com.alibaba.fastjson.serializer.JavaBeanSerializer.write(JavaBeanSerializer.java:154)at com.alibaba.fastjson.serializer.JSONSerializer.write(JSONSerializer.java:312)at com.alibaba.fastjson.JSON.toJSONString(JSON.java:793)at com.alibaba.fastjson.JSON.toJSONString(JSON.java:731)at com.alibaba.fastjson.JSON.toJSONString(JSON.java:688)at com.xxx.impl.EmpTransHandleServiceImpl.doSaveTransReceipts(EmpTransHandleServiceImpl.java:1151)at com.xxx.impl.EmpTransHandleServiceImpl.processBatchSubmitReceipt(EmpTransHandleServiceImpl.java:1077)at com.xxx.impl.EmpTransHandleServiceImpl.submitTransReceipts(EmpTransHandleServiceImpl.java:156)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
经过仔细排查,发现需要打印日志的对象中,近期新增了一个 getXXX() 方法,用于对现有对象中的字段进行加工处理。如下:
public Integer getDutyLevelNumber() {String numberStr = dutyLevel.startsWith("M")? dutyLevel.replace(BusConstants.M_DUTY_LEVEL_PREFIX, StringUtils.EMPTY): dutyLevel.replace(BusConstants.P_DUTY_LEVEL_PREFIX, StringUtils.EMPTY);return Integer.valueOf(numberStr);}
查阅资料了解到,fastjson 进行序列化时,默认会自动执行对象的 getXXX() 方法。又由于该方法内部没有对字段合法性进行提前校验,因此当 fastjson 自动执行该方法时,由于字段为 null,导致了内部出现了 NPE 异常。
知道原因之后,解决问题的方式很简单。既然 fastjson 会自动执行 getXXX() 方法,那么修改方法命名不就可以了么。直接将 「getDutyLevelNumber()」替换为 「fetchDutyLevelNumber()」,修改后验证程序正常。
虽然问题得以解决,但还是有些疑问摆在我们面前,为何 fastjson 会自动执行 getXXX() 方法?fastjson 整个序列化过程是大概怎样的?由于 fastjson 在日常开发过程中使用比较频繁,我们有必要把其中的来龙去脉探究清楚。
Talk is cheap. Show me the code
下面我们结合 fastjson 1.2.76 源码,从 toJSONString 方法出发,简要分析下它的序列化过程。
public static String toJSONString(Object object, int defaultFeatures, SerializerFeature... features) {SerializeWriter out = new SerializeWriter((Writer) null, defaultFeatures, features);try {JSONSerializer serializer = new JSONSerializer(out);serializer.write(object);String outString = out.toString();int len = outString.length();if (len > 0&& outString.charAt(len -1) == '.'&& object instanceof Number&& !out.isEnabled(SerializerFeature.WriteClassName)) {return outString.substring(0, len - 1);}return outString;} finally {out.close();}}
首先,方法创建了一个 SerializeWriter 对象,用于将序列化后的字符流写入一个内部缓冲区。接下来,创建一个 JSONSerializer 对象,并将SerializeWriter对象作为参数传递给它。JSONSerializer 类负责管理序列化过程,并调用合适的序列化器将 Java 对象转换为 JSON 字符串。然后,通过调用 JSONSerializer 对象的 write 方法进行序列化。
3.2 JSONSerializer#write 方法
public final void write(Object object) {if (object == null) {out.writeNull();return;}Class<?> clazz = object.getClass();ObjectSerializer writer = getObjectWriter(clazz);try {writer.write(this, object, null, null, 0);} catch (IOException e) {throw new JSONException(e.getMessage(), e);}}
根据Class对象从SerializeConfig中获取对应的序列化器(ObjectSerializer)。接着调用序列化器的write方法将对象序列化为JSON字符串。区别点在于 getObjectWriter,ObjectSerializer 被定义成一个抽象接口,不同的对象会获取到不同类型的 ObjectSerializer。我们代码中是自定义的对象,看下自定义对象是如何返回 ObjectSerializer 的。
3.3 SerializeConfig#getObjectWriter 方法
public ObjectSerializer getObjectWriter(Class<?> clazz, boolean create) {ObjectSerializer writer = get(clazz);if (writer != null) {return writer;}...if (writer == null) {String className = clazz.getName();Class<?> superClass;if (Map.class.isAssignableFrom(clazz)) {put(clazz, writer = MapSerializer.instance);} else if (List.class.isAssignableFrom(clazz)) {put(clazz, writer = ListSerializer.instance);} else if (Collection.class.isAssignableFrom(clazz)) {...}if (create) {writer = createJavaBeanSerializer(clazz);put(clazz, writer);}...}return writer;}
先从缓存中找到ObjectSerializer,缓存中没有则先根据clazz获取特定的序列化器,比如Map、List这些,没有的话,则进入到创建JavaBeanSerializer的流程中。JavaBeanSerializer是自定义对象的序列化器,不同对象都需要创建一个对应的序列化器。创建完成后再放入缓存中。
3.4 SerializeConfig#
createJavaBeanSerializer 方法
public final ObjectSerializer createJavaBeanSerializer(Class<?> clazz) {String className = clazz.getName();long hashCode64 = TypeUtils.fnv1a_64(className);if (Arrays.binarySearch(denyClasses, hashCode64) >= 0) {throw new JSONException("not support class : " + className);}SerializeBeanInfo beanInfo = TypeUtils.buildBeanInfo(clazz, null, propertyNamingStrategy, fieldBased);if (beanInfo.fields.length == 0 && Iterable.class.isAssignableFrom(clazz)) {return MiscCodec.instance;}return createJavaBeanSerializer(beanInfo);}
这个方法主要有两步,第一步根据 clazz 信息构建需要序列化的 bean 信息对象 SerializeBeanInfo,第二步根据 SerializeBeanInfo 创建 JavaBeanSerializer。SerializeBeanInfo 中包含了一个对象中需要序列化的所有字段信息,也就是说哪些字段需要进行序列化就是在构建该对象的过程中进行判断的。创建 JavaBeanSerializer 的细节这里先不展开,主要是根据 SerializeBeanInfo 对象中已经确认好的需要序列化的字段,再结合不同字段的序列化配置,做了一层封装。
3.5 TypeUtils#buildBeanInfo 方法
public static SerializeBeanInfo buildBeanInfo(Class<?> beanType, Map<String,String> aliasMap, PropertyNamingStrategy propertyNamingStrategy, boolean fieldBased){Map<String,Field> fieldCacheMap = new HashMap<String,Field>();ParserConfig.parserAllFieldToCache(beanType, fieldCacheMap);List<FieldInfo> fieldInfoList = fieldBased? computeGettersWithFieldBase(beanType, aliasMap, false, propertyNamingStrategy): computeGetters(beanType, jsonType, aliasMap, fieldCacheMap, false, propertyNamingStrategy);FieldInfo[] fields = new FieldInfo[fieldInfoList.size()];fieldInfoList.toArray(fields);...return new SerializeBeanInfo(beanType, jsonType, typeName, typeKey, features, fields, sortedFields);}
关键点在于 fields 的获取,fields 字段就是真正需要序列化的字段信息。通过 computeGetters 方法获取对应 clazz 的所有字段信息。实现过程中借助了 fieldCacheMap 存储 fieldName 和 Field 的映射关系,减少之后的 findField 的轮询。
3.6 TypeUtils#computeGetters 方法
public static List<FieldInfo> computeGetters(Class<?> clazz,JSONType jsonType,Map<String,String> aliasMap,Map<String,Field> fieldCacheMap,boolean sorted,PropertyNamingStrategy propertyNamingStrategy){Map<String,FieldInfo> fieldInfoMap = new LinkedHashMap<String,FieldInfo>();boolean kotlin = TypeUtils.isKotlin(clazz);Constructor[] constructors = null;Annotation[][] paramAnnotationArrays = null;String[] paramNames = null;short[] paramNameMapping = null;Method[] methods = clazz.getMethods();for(Method method : methods) {if(methodName.startsWith("get")){if (methodName.length() < 4) {continue;}...else {propertyName = methodName.substring(3);field = ParserConfig.getFieldFromCache(propertyName, fieldCacheMap);if (field == null) {continue;}}...FieldInfo fieldInfo = new FieldInfo(propertyName, method, field, clazz, null, ordinal, serialzeFeatures, parserFeatures,annotation, fieldAnnotation, label);fieldInfoMap.put(propertyName, fieldInfo);}if(methodName.startsWith("is")) {...}Field[] fields = clazz.getFields();computeFields(clazz, aliasMap, propertyNamingStrategy, fieldInfoMap, fields);return getFieldInfos(clazz, sorted, fieldInfoMap);}
该方法主要作用是解析对象中的字段信息,并生成 FiledInfo 。首先获取对象的所有方法,对每个方法进行循环处理:判断方法是否以 get 或者 is 开头,如果是,则进一步判断。并取出 get 或者 is 之后的字符作为字段名称,构建 FieldInfo 对象,FieldInfo 中包括了属性的名称、序列化方法、方法等信息。
通过对 computeGetters 方法的分析,我们可以了解到对象中的 get 方法在 fastjson 中一般会被解析成具体的字段。比如,样例中的 getDutyLevelNumber 方法会被解析成 dutyLevelNumber 字段。
后续的代码流程不再展开,简单概括下:最终会执行 JavaBeanSerializer 中的 write 方法,该方法内部实际上会对 FieldInfos 进行循环处理,针对每个 field,会调用它的 FieldSerializer 进行字段序列化。序列化之前会通过 FieldInfo 中的 method 对象执行 invoke 方法获取属性值。因此在这一步会触发样例中的 getDutyLevelNumber 方法执行,导致系统异常。
分析至此,我们可能会想,fastjson 为何默认使用 getter 方法获取对应的属性?直接访问字段不也可以吗,比如 Gson 就是这样做的。
我的理解,首先这种方式是遵循 Java Beans 规范的,也能够兼容绝大多数 Java 类。其次,通过 getter 获取属性值相对来说更安全且具有一定的封装性,试想下如果对象中某个字段信息比较敏感,需要符合一定条件才允许序列化传输或者打印日志,我们在 getter 方法中增加卡控判断即可。另外,这种方式也具备一定的灵活性,如果需要对字段进行加工,也可在 getter 方法中进行处理,而无需改变原先的字段值。
但这种方式也存在一些不足。一是,使用者容易踩坑。比如本文遇到的 NPE 问题,也是因为起初不清楚 fastjson 序列化的原理,会自动执行 getter 方法,从而踩了坑,此类情况应该占多数;二是,性能开销,相比于直接访问字段,通过方法调用可能引入轻微的性能损耗,不过这点损耗,一般情况下相较于 fastjson 使用 ASM 技术提升的性能,可忽略不计。
针对自定义的 get 方法会被 fastjson 自动执行的情况,一般有以下几种方式可以解决。
2.调用 toJSONString 方法时,额外指定参数忽略没有对应字段的 get 方法。
4.在项目中增加 JSON 工具类,工具类中定义 toJSONString 方法并且调用 fastjson,并捕获异常。将项目中的 JSON.toJSONString 都收敛到工具类中,避免直接调用 fastjson。
另外也需注意,如果自定义 get 方法,也要尽量避免在 get 方法中进行数据更新操作。同时在 get 方法内部对字段进行处理时,养成先对字段合法性校验的编码习惯,避免产生 NPE 或数组越界等异常情况。
本方案结合通义千问和LangChain技术构建高效的对话模型,该模型基于自然语言处理技术提升语义理解和用户交互体验。它可以有效解决传统对话模型在理解能力和交互效果上的局限,使得用户沟通更加自然流畅,被广泛应用于聊天机器人、智能客服和社交媒体等多种场景。
点击阅读原文查看详情。