
包阅导读总结
1. 关键词:Apache DolphinScheduler、工作流编排、大数据、开源、ASF
2. 总结:Apache DolphinScheduler 是分布式开源工作流编排平台,2017 年启动,2019 年入 ASF 孵化器,2020 年成顶级项目。它解决复杂任务依赖等问题,有多种特色功能,已被广泛部署,社区不断壮大,欢迎多种形式贡献。
3. 主要内容:
– 项目介绍:
– Apache DolphinScheduler 是分布式可扩展的开源工作流编排平台,有强大的 DAG 可视化界面,低代码创建高性能工作流。
– 项目背景:
– 2017 年推出,旨在解决“复杂任务依赖”等问题。
– 目标受众与特点:
– 面向数据相关从业者,特点包括快速创建工作流、稳定数据执行、强大的数据回填和版本控制、轻松管理复杂任务。
– 解决的问题与重要性:
– 解决“复杂任务依赖”,提供 ETL 运行状态实时监测等。建立了强大的大数据工作流管理平台,促进大数据高效利用。
– 体现 ASF 使命:
– 遵循 Apache Way 和“Community Over Code”文化,吸引全球人员共建。
– 应用案例:
– 已部署超 3000 实例,如助力长安汽车智能云平台处理海量数据。
– 社区发展:
– 从少数人发展到 550 多个全球贡献者。
– 学习与尝试途径:
– 可通过教程链接学习和试用。
– 贡献方式:
– 包括代码和非代码贡献,如文档、社区支持、教程材料、活动参与和设计等。
思维导图: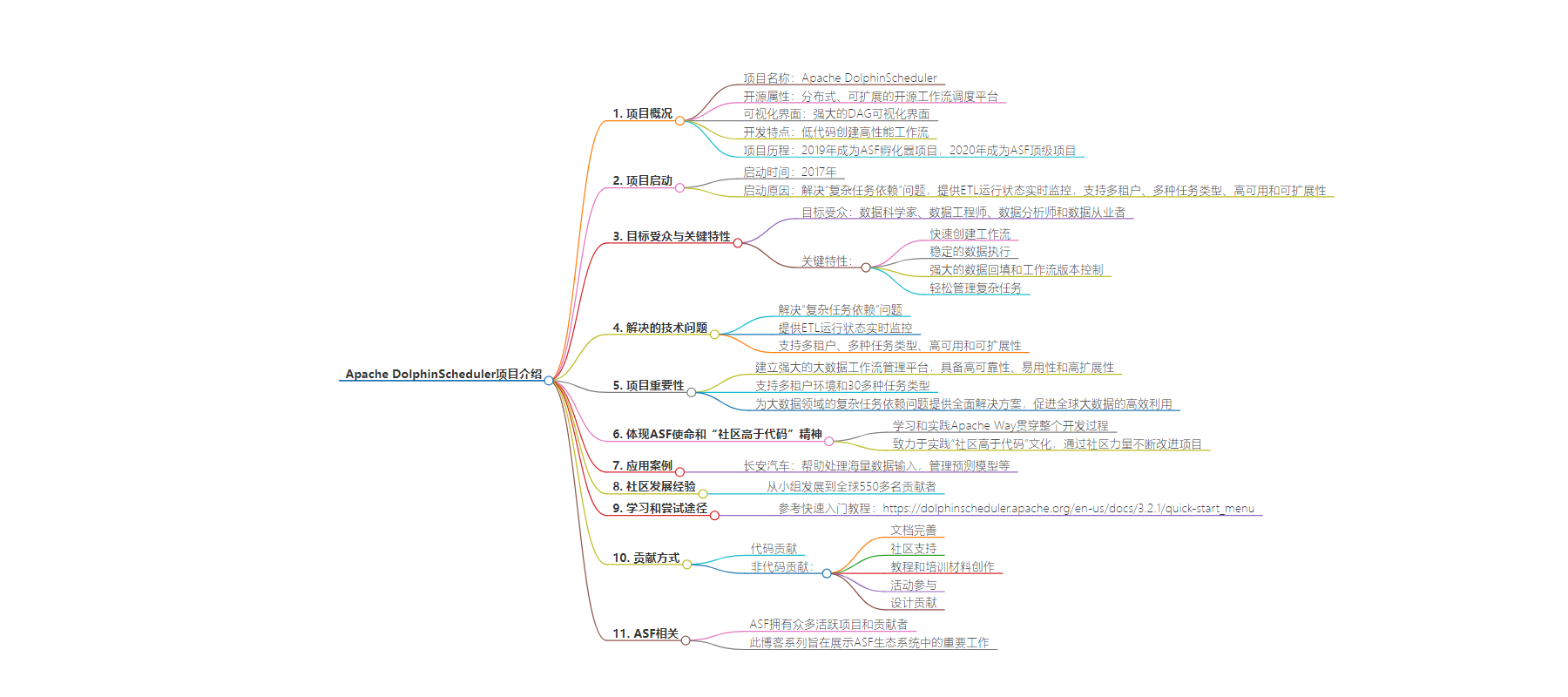
文章地址:https://news.apache.org/foundation/entry/asf-project-spotlight-apache-dolphinscheduler
文章来源:news.apache.org
作者:The ASF
发布时间:2024/8/20 17:07
语言:英文
总字数:1195字
预计阅读时间:5分钟
评分:87分
标签:工作流编排,大数据,开源,Apache 软件基金会,数据管理
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Can you tell us a bit about the project?
Apache DolphinScheduler is a distributed and extensible open-source workflow orchestration platform with powerful DAG visual interfaces, which is agile in creating a high-performance workflow with low code. DolphinScheduler was donated to the Apache Software Foundation (ASF) in 2019, becoming an ASF Incubator project. DolphinScheduler became an ASF Top-Level Project in 2020.
When was the project started and why?
DolphinScheduler was launched in 2017 to create an easy-to-use data scheduling tool that could solve the “complex task dependencies” problem, provide real-time monitoring of ETL running status, and support multi-tenancy, multiple task types, HA, and scalability. Prior to projects like DolphinScheduler, big data platforms were often hindered by the complex dependencies of ETL, ease of use, maintainability, and re-development issues.
Who is your audience, and what key features of the technology do you believe will excite people?
DolphinScheduler is built for data scientists, data engineers, data analysts, and data practitioners who need to solve big data workflow scheduling problems with a simple and easy-to-use approach, accelerating the efficiency of the data ETL development process.
DolphinScheduler features and highlights include:
- Fast workflow creations: The drag-and-drop workflow management method optimizes efficiency while supporting coding workflow by Python, Yaml, and Open API, allowing users to create a workflow within a minute.
- Steady data execution: DolphinScheduler allows users to execute big data tasks with high concurrency, high throughput and low latency.
- Powerful data backfill and workflow version control.
- Easily manage complex tasks by enabling cross-project and cross-workflow task dependencies.
What technology problem is Apache DolphinScheduler solving?
The emergence of DolphinScheduler solves the issue of “complex task dependencies,” providing real-time monitoring of ETL running status and supporting multi-tenancy, multiple task types, HA, and scalability.
Why is this work important?
DolphinScheduler has established a powerful big data workflow management platform that features high reliability, user-friendly, and high expansibility. It also supports multi-tenant environments and more than 30 task types, including Apache Spark, Apache Flink, Apache Hive, Shell, Python, sub_process. It has openly and freely provided a comprehensive solution to address the problem of complex task dependencies in the field of big data, which greatly promotes the efficient utilization of big data globally. This has helped enterprises, organizations, and individuals to enhance the value of their data.
The ASF’s mission is to provide software for the public good. In what ways does your project embody the ASF mission and “community over code” ethos?
Learning and practicing the Apache Way has permeated the entire development process of DolphinScheduler. We are also committed to practicing the essence of the ASF’s “Community Over Code” culture. The community is greater than the code itself; it requires thinking beyond the code on how to collaborate, how to communicate, and how to keep the community healthy moving forward. It is this constant reflection that has enabled DolphinScheduler to widely attract people from all over the world who like DolphinScheduler and support open source, to build the project and community together. Through various channels, the concept of “community over code” is promoted and through the power of the community, the project is constantly improved upon, allowing more people to enjoy the revolution brought by open-source big data task flow scheduling technology.
Are there any use cases you would like to tell us about?
DolphinScheduler has been deployed in 3000+ instances spanning enterprises, organizations, and personal use. One notable enterprise user is Changan Auto. DolphinScheduler helps Changan Auto’s intelligent internet-connected vehicle cloud platform to handle tens of millions of data inputs. Changan Auto uses DolphinScheduler to manage prediction models; build timed task workflows to extract signal data required for model prediction from the cluster; and centrally manage the SQL analysis and Py code. With DolphinScheduler, Changan Auto can build a unified data platform in conjunction with data integration tools such as SeaTunnel and Sqoop. This allows multiple sources of data to be integrated smoothly and efficiently while data is transmitted in both directions under a hybrid cloud architecture and under private and public cloud cross-cluster conditions.
For more details, please refer to this case study: Changan Auto Intelligent Vehicle Cloud Platform introduces the core workflow orchestration system Apache DolphinScheduler
What has been your experience growing the community?
Growing the community has been a tough but interesting challenge. The community started with just a small group of people and now has grown to 550+ contributors from around the globe. People from China, the United States, South Korea, India, Europe, the Philippines, Singapore, Australia, among others, are attracted to the goal of building a big data workflow scheduling platform more usable to everyone.
What’s the best way to learn about the project and try it out?
To learn more about DolphinScheduler, you can refer to this quick start tutorial to try it out: https://dolphinscheduler.apache.org/en-us/docs/3.2.1/quick-start_menu
How can others contribute to this project – code contributions being only one of the ways?
DolphinScheduler welcomes both code and non-code contributions. Anyone interested in the project and open-source software can find a suitable way to join the ranks of contributors.
- Code Contributions:
- Non-code Contributions:
- Documentation: Improving or translating the documentation helps lower the entry barrier for new users and developers;
- Community Support: Engaging in community forums, mailing lists, or chat platforms to help users with questions or challenges fosters a supportive ecosystem around Apache DolphinScheduler;
- Tutorials and Training Materials: Creating tutorials, blog posts, or video content that educates others about Apache DolphinScheduler and its applications can spread awareness and encourage adoption;
- Event Participation: Organizing or participating in meetups, conferences, and workshops; and
- Design Contributions: Offering design expertise for the project’s UI, website, or promotional materials.
The ASF is home to nearly 9,000 committers contributing to more than 320 active projects including Apache Airflow, Apache Camel, Apache Flink, Apache HTTP Server, Apache Kafka, and Apache Superset. With the support of volunteers, developers, stewards, and more than 75 sponsors, ASF projects create open source software that is used ubiquitously around the world. This work helps us realize our mission of providing software for the public good.
In the midst of hosting community events, engaging in collaboration, producing code and so much more, we often forget to take a moment to recognize and adequately showcase the important work being done across the ASF ecosystem. This blog series aims to do just that: shine a spotlight on the projects that help make the ASF community vibrant, diverse and long lasting. We want to share stories, use cases and resources among the ASF community and beyond so that the hard work of ASF communities and their contributors is not overlooked.
If you are part of an ASF project and would like to be showcased, please reach out to markpub@aparche.org.
Connect with ASF