包阅导读总结
1. 压测、数据库、CPU 飙升、性能指标、行读异常
2. 本文讲述一次压测中数据库 CPU 利用率异常飙升的排查过程。在压测不同流量阶段,CPU 利用率出现异常。经过排查,发现行读异常是主因,由于压测改造方式导致同一账号注册任务增多,使符合条件的行数增加,最终 CPU 花费更多资源处理。
3.
– 压测背景
– 业务需求形成秒杀场景,需对系统和 DB 水位进行压测。
– 压测准备
– 包括流量评估、改造、测试发布、下游流量报备、数据准备、小流量预跑等步骤。
– 压测问题
– 不同流量阶段 CPU 利用率异常。
– 同等流量下压测 CPU 利用率高于线上实际值。
– 流量 80%时 CPU 利用率缓慢上涨,100%时突然飙升。
– 问题排查
– 排除压测改造导致 DB 的 QPS 和 TPS 过高的猜测。
– 发现行读异常,对比定位到有问题的 SQL。
– 明确原因是压测改造方式使同一账号注册任务增多,符合条件的行数增加,CPU 处理资源消耗增加。
– 总结反思
– 压测 80%流量时应关注 CPU 异常。
– 压测时对 DB 性能指标监控不到位。
– 压测改造要注意与场景匹配程度。
思维导图: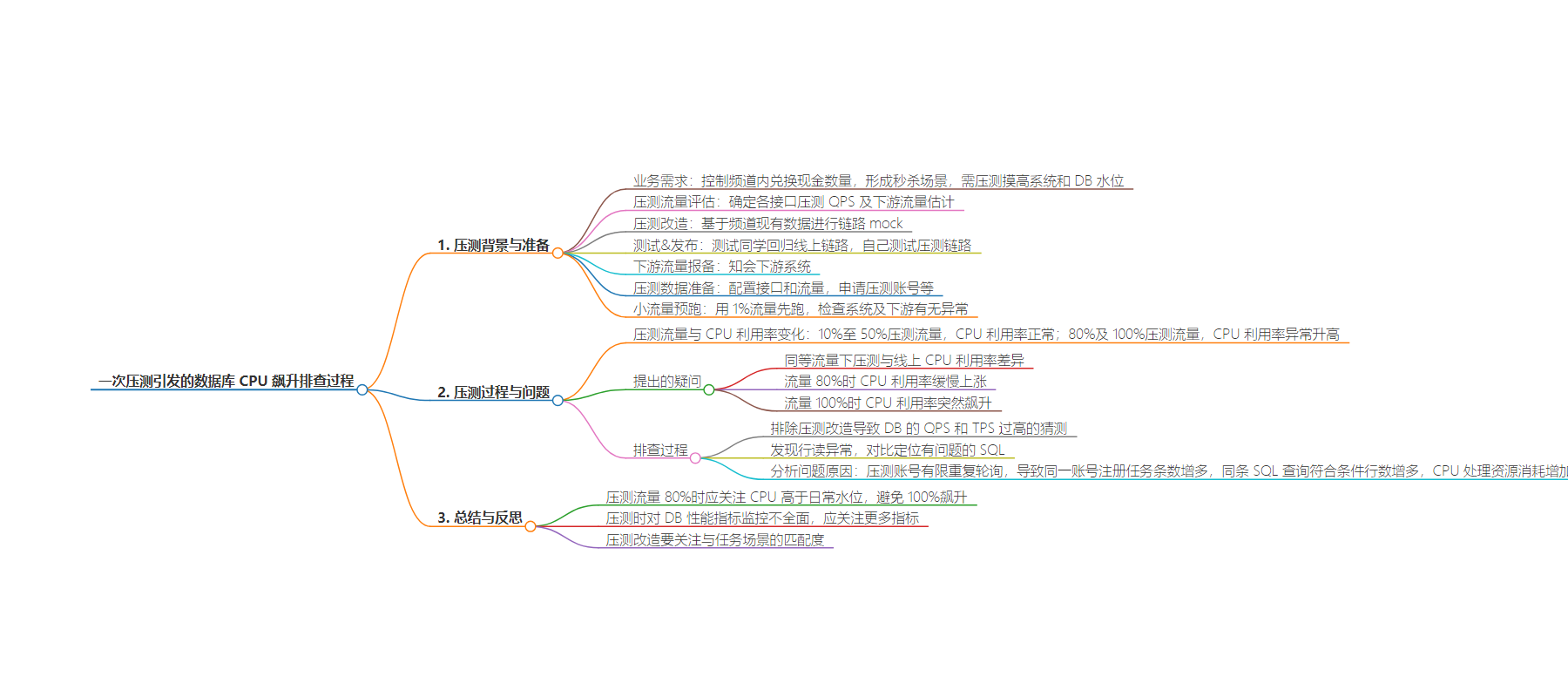
文章地址:https://mp.weixin.qq.com/s/n0U3g-R0KmZ97RhH9dzWiw
文章来源:mp.weixin.qq.com
作者:昀鹤
发布时间:2024/6/20 8:02
语言:中文
总字数:2656字
预计阅读时间:11分钟
评分:86分
标签:性能测试,数据库性能,CPU优化,行读优化,SQL效率
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

这是2024年的第43篇文章
( 本文阅读时间:15分钟 )
一次压测过程中,当数据库的qps和tps都正常时,如果cpu利用率异常的高,应该如何排查?希望通过这篇文章,给你一些启发…
看着cpu的监控图,我的脑海里浮现了三个疑问:
1.同等流量下,压测时的cpu利用率为什么高于线上实际值(线上约等于压测80%流量时,cpu利用率实际40%不到,压测时已经到60%了)?
2.流量80%时,为什么压测流量持续不动,cpu利用率会缓慢上涨呢?
3.流量100%时,分明一开始cpu利用率还维持在80%以下,然后突然就飙到100%了?
总体来说,就是CPU高于预期。
第一时间我猜测是我的压测改造不符合预期,导致打到db的qps和tps过高导致。
急了,开始看代码,然后挑了几个压测trace在鹰眼上看调用,没找到问题。
然后发现我好蠢呐(主要是有点慌张),dbservice本身就有tps和qps的监控:
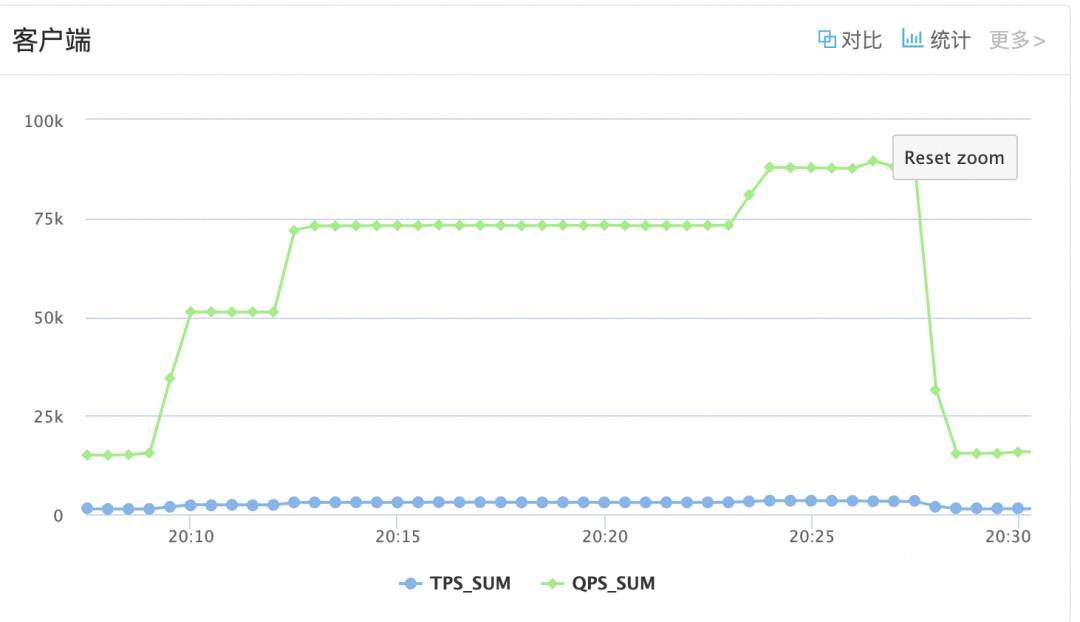
看了一下,有两点,一是持续压测的时候,qps并没有持续上涨,二是差不多同流量下qps的值确实略高于线上实际值,但远远没有cpu差值这么多,所以基本可以排除一开始的猜测。
陷入了瓶颈…..
这时候我知道今天的压测指定是不行了,所以很干脆地摆了,开始安心的找问题~
这时候拉了DBA同学一起帮我们看问题,DBA同学表示,一,数据库在长时间高压下会发生性能劣化,这也是cpu从80%突然暴涨到100%的原因(解答了第三个问题),至于CPU利用率异常是表象,qps和tps只是其中一个影响因素,建议我们看看其他指标。
于是挨个查看数据库性能指标(带宽、慢sql、RT….),然后终于发现了一个疑点:
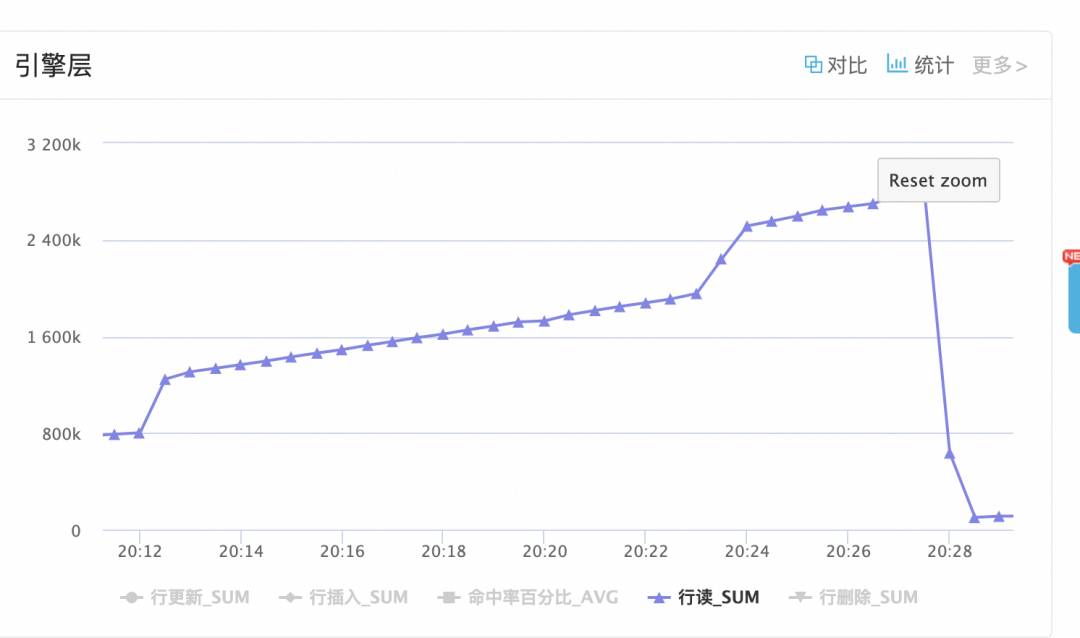
这个缓慢升高的行读,非常符合压测流量80%时cpu曲线的变化,很可能是问题二的原因…
那是不是也有可能是问题一的原因呢?
对比正常峰值流量下的行读指标
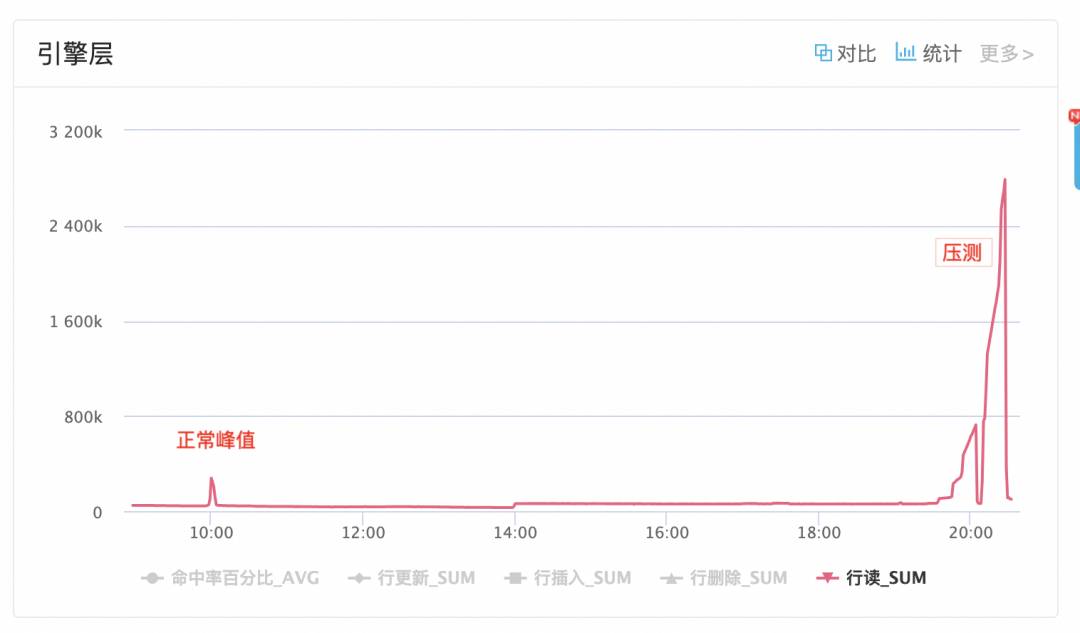
好吧,这都差了一个数量级了,基本可以确定问题出在行读异常上了
开始思考为什么行读这么多还在持续上涨,难道是同一个sql查出来的行数会变多?
其实这时候心里已经隐隐约约猜到问题在哪了,但还是顺着这个行读异常排查下去
通过对比定位到了有问题的sql
压测时:
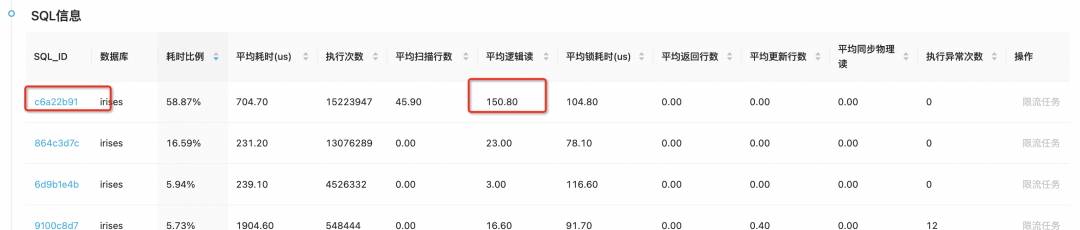
正常时:

点进去也能看到具体的sql信息:
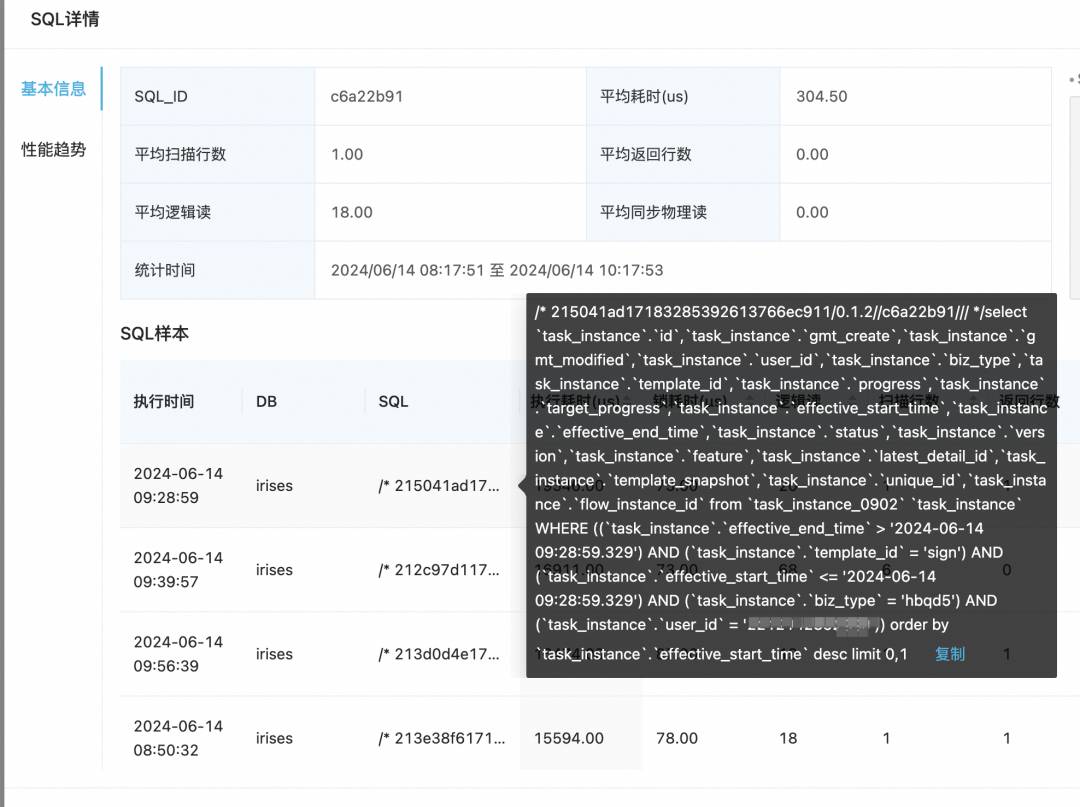
好吧,和我猜的一样,这下悬着的心终于死了。
至于为什么同一条sql压测的平均行读会高这么多,还是得从代码层面来分析。
首先先看下改造逻辑和逻辑推导:
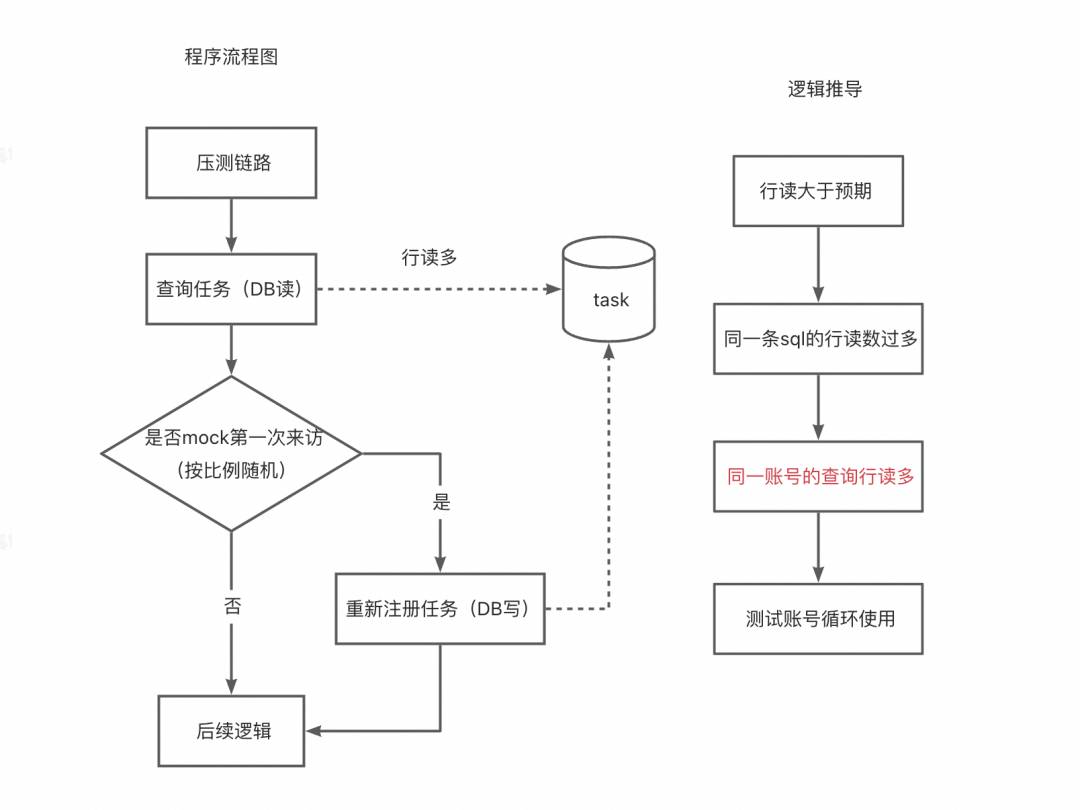
这么压测改造的原因是压测的账号是有限的(同一批压测账号重复的去轮询),如果所有账号都调过一遍接口,那后面的每次查询都能查到任务,不会再有DB写,为了更好的模拟线上实际情况,因此通过这种方法去让账号重新路由到注册逻辑。
然后看下任务的查询逻辑,如下:
private TaskInstanceParam createQueryParamByEffectiveTime(TaskQueryParam queryParam) {final TaskInstanceParam dbQueryParam = new TaskInstanceParam();Date now = TimeTravelManager.getCurrentTime(queryParam.getUserId());dbQueryParam.createCriteria().andUserIdEqualTo(queryParam.getUserId()).andBizTypeEqualTo(queryParam.getBizType()).andTemplateIdEqualTo(queryParam.getSubBizType()).andEffectiveStartTimeLessThanOrEqualTo(now).andEffectiveEndTimeGreaterThan(now);dbQueryParam.appendOrderByClause(OrderCondition.EFFECTIVESTARTTIME, SortType.DESC);dbQueryParam.setPagination(1, 1);return dbQueryParam;}
接下来请ChatGpt老师上台,为我们普及下相关原理:
我 :什么是行读,行读高cpu利用率就高嘛?

我 :哦,听起来行读是比较笼统的概念,那什么是逻辑读和物理读呢,区别在哪里?

我:嗯哼,原理解释有点干燥,画个关系图(挑衅)?
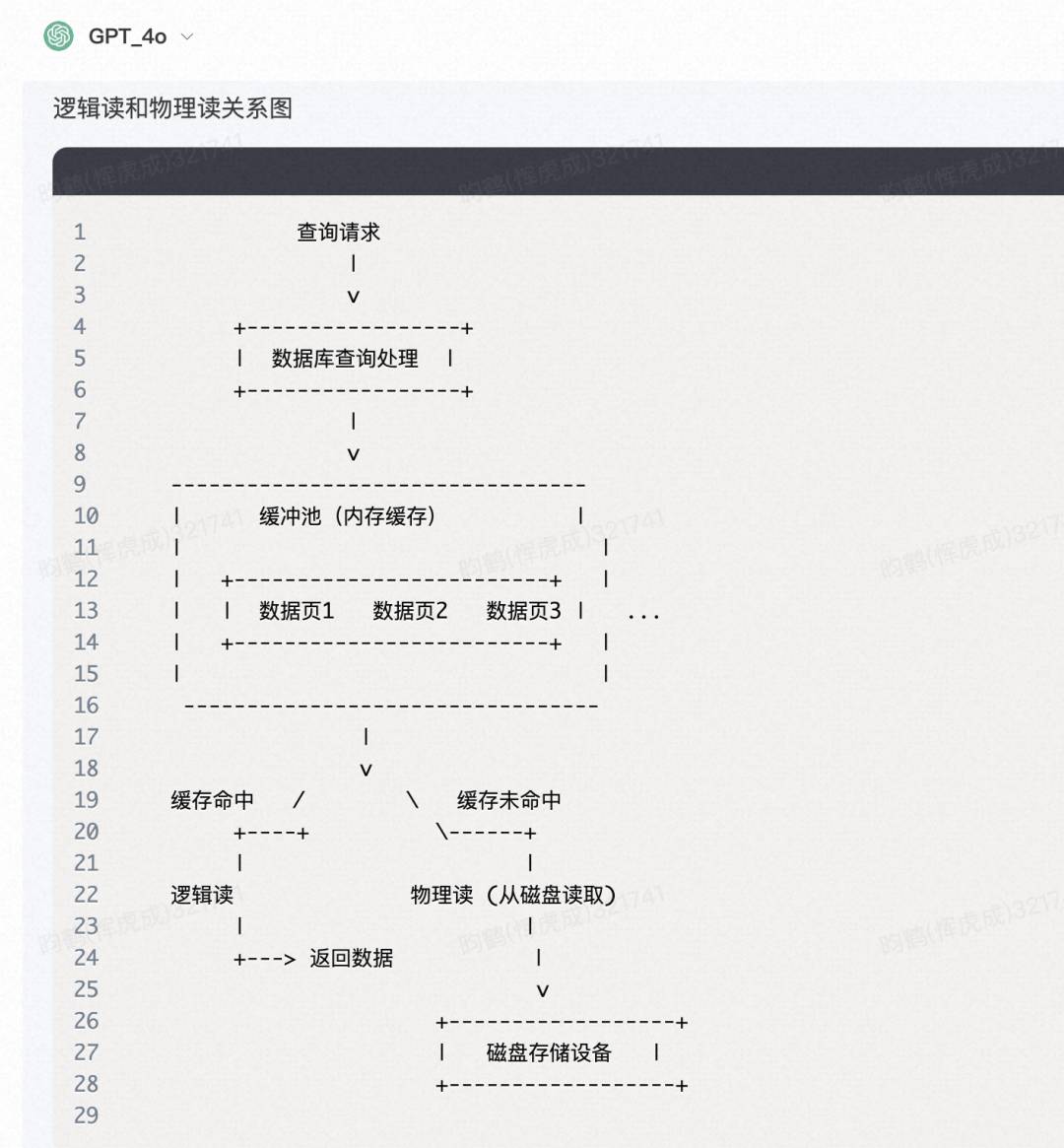
我:啊?阿珍你来真的啊?
我:那总结一下,其实就是行读包括逻辑读和物理读两种,前者优于后者,平时的开发中,应该注意合理建立索引和优化sql,来减少扫描整体行读数以及物理读的次数呗,说的对就夸一下我?

1.压测流量80%时,就应该敏感地关注到cpu是高于日常水位的,其实可以避免压测调到100%的cpu飙升;
2.对于DB的性能指标,压测时只关注了最表层的cpu利用率,其他的性能指标监控没有关注到位;
3.对于我们的任务场景下,查询的是有效期内的最新一条任务,实际上不太适合反复注册的压测mock,所以在压测改造时,还需要关注改造方式与场景的匹配程度。