
包阅导读总结
1. 关键词:AIGC、信息检索、人工智能、技术模型、材料科学
2. 总结:
本文涵盖了生成信息检索 GenIR 开源、FAL 公开源代码超级分辨率图像扩大器、CriticGPT 找 GPT-4 错误、Meta 发布 LLM 编译器、Point-SAM 3D 分割模型、Gemma 2 系列新型号开源、材料科学领域语言模型、Mamba 2 快速实现方案等 AIGC 相关的新技术和新进展。
3. 主要内容:
– 生成信息检索 GenIR 开源
– 是全新信息查找方式,摒弃传统搜索方法
– 不依赖现有数据库,依赖先进算法和技术
– 提供精准个性化信息服务,带来革命性变革
– FAL 公开源代码超级分辨率图像扩大器 GigaGAN
– 公开 AuraSR 源代码
– 一次前向传递可实现 4 倍扩大,多次应用效果良好
– CriticGPT
– 用于找出 GPT-4 可能的错误
– 基于 GPT-4 模型构建,分析输出找错
– 比现有技术更准确,提供更好解决方案
– Meta 发布 LLM 编译器
– 可将代码编译成汇编语言并反编译至 LLVM IR
– 经大量数据训练,优化汇编和反汇编性能
– 为编程和反编程领域带来新突破
– Point-SAM
– 互动引导下的 3D 分割变革模型
– 提高 3D 数据处理效率和精度
– 为 3D 数据处理领域带来革命
– Gemma 2 系列新型号
– 9B 和 27B 上市
– 融合先进技术与优雅设计,为用户带来卓越体验
– 材料科学领域的语言模型
– MatText 是评估工具和数据集
– 助于理解和评估语言模型在材料科学中的表现
– Mamba 2 快速实现方案开源
– 介绍快速实现方式,无需关联扫描
– GitHub Repo 提供详细步骤和方法
思维导图:
文章地址:https://mp.weixin.qq.com/s/-EXs9r3QHSbh-eG2VKuoMg
文章来源:mp.weixin.qq.com
作者:漫话开发者
发布时间:2024/6/29 16:59
语言:中文
总字数:2766字
预计阅读时间:12分钟
评分:88分
标签:生成信息检索,人工智能,深度学习,CriticGPT,GPT-4
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
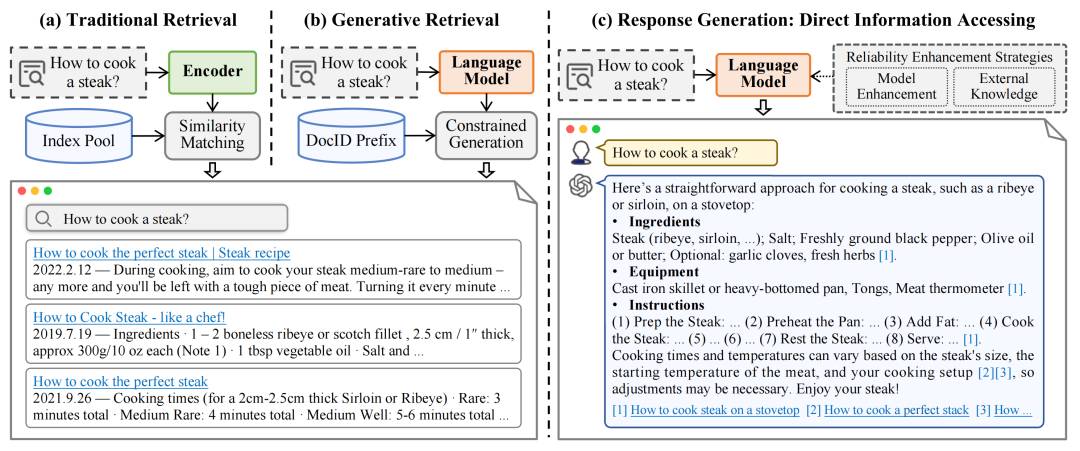
1. 生成信息检索GenIR开源:颠覆传统搜索的新方法
本次调查深入探讨了生成信息检索(GenIR),这是一种全新的信息查找方式,它摒弃了传统的搜索方法,转而采用能够实时生成答案的方法。生成信息检索不再依赖于现有的数据库或信息源,而是依赖于先进的算法和技术,如人工智能和深度学习,来生成用户所需的信息。这种方法的出现,为用户提供了更为精准和个性化的信息服务,同时也为信息检索领域带来了革命性的变革。
划重点
-
生成信息检索(GenIR)是一种全新的信息查找方式 -
生成信息检索不再依赖于现有的数据库或信息源,而是依赖于先进的算法和技术,如人工智能和深度学习 -
生成信息检索为用户提供了更为精准和个性化的信息服务,同时也为信息检索领域带来了革命性的变革
标签:生成信息检索, 人工智能, 深度学习
原文链接见文末/1[1]
2. FAL公开源代码超级分辨率图像扩大器GigaGAN
FAL最近公开了超级分辨率图像扩大器AuraSR的源代码。这款工具只需一次前向传递,就可以实现4倍的扩大,甚至在多次应用后仍能保持良好的效果。AuraSR在处理生成的图像上表现出色。FAL公司此次公开源代码,无疑为图像处理领域带来了新的可能性。它的效果强大、运行高效,有望在广泛的图像处理任务中发挥重要作用。该工具的公开,将有助于推动超级分辨率技术的进一步发展。

划重点
-
FAL最近公开了超级分辨率图像扩大器AuraSR的源代码 -
AuraSR只需一次前向传递,就可以实现4倍的扩大
标签:FAL, AuraSR, 超级分辨率
原文链接见文末/2[2]
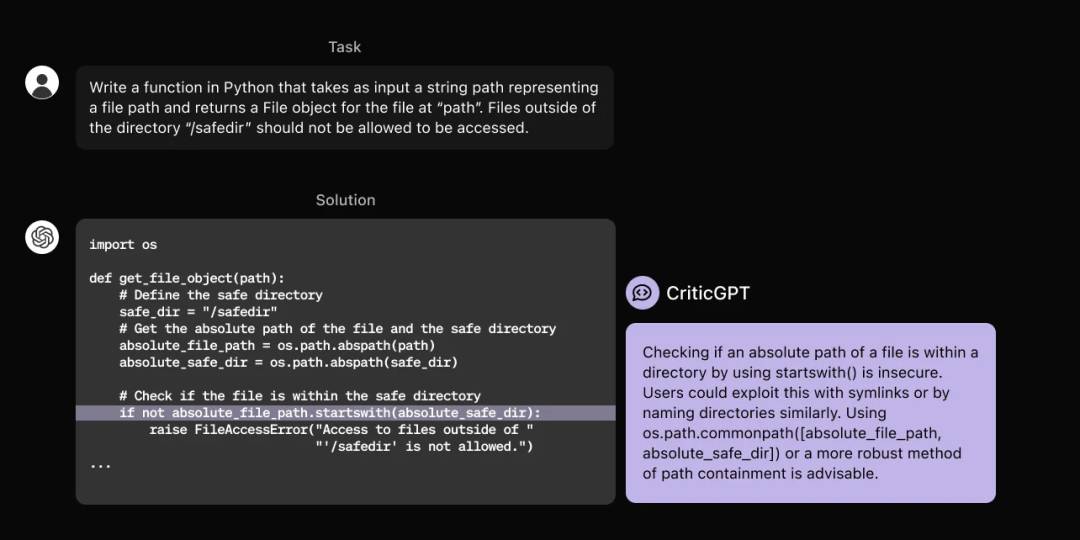
3. CriticGPT: 用GPT-4找出GPT-4的错误
据外媒报道,研究人员正在开发一种名为CriticGPT的新技术,以帮助找出GPT-4可能存在的错误。CriticGPT 是在 GPT-4 模型的基础上构建的,它通过分析 GPT-4 模型的输出,找出其中的错误和偏差。相比目前的技术,CriticGPT 能够更加准确地找出 GPT-4 模型中存在的问题,并提供更好的解决方案。
划重点
-
CriticGPT是一种新技术,旨在找出GPT-4模型可能存在的错误。 -
CriticGPT通过分析GPT-4模型的输出,找出其中的错误和偏差。 -
相比目前的技术,CriticGPT能够更加准确地找出GPT-4模型中存在的问题,并提供更好的解决方案。
标签:CriticGPT, GPT-4, 人工智能技术
原文链接见文末/3[3]
4. Meta发布LLM编译器:性能优化至77%,反汇编性能达45%
近日,Meta发布了两款语言模型,旨在将代码编译成汇编语言并能够反编译至LLVM IR。这两款模型在5460亿个高质量数据标记上接受了训练,并进行了进一步的指令调优。Meta的这一创新实现了优化后的汇编性能达到77%,反汇编性能达到45%。这两款模型的出现,无疑为编程和反编程领域带来了新的突破,预示着未来的程序开发将更加高效和精确。这也标志着Meta在人工智能和机器学习领域的深度研究取得了重要的进展。
划重点
-
Meta发布了两款语言模型,可以将代码编译成汇编语言并反编译至LLVM IR。 -
这两款模型在5460亿个高质量数据标记上接受了训练后,实现了优化后的汇编性能达到77%,反汇编性能达到45%。 -
这两款模型的出现,预示着未来的程序开发将更加高效和精确,标志着Meta在人工智能和机器学习领域的深度研究取得了重要的进展。
标签:Meta, LLM编译器, 人工智能
原文链接见文末/4[4]
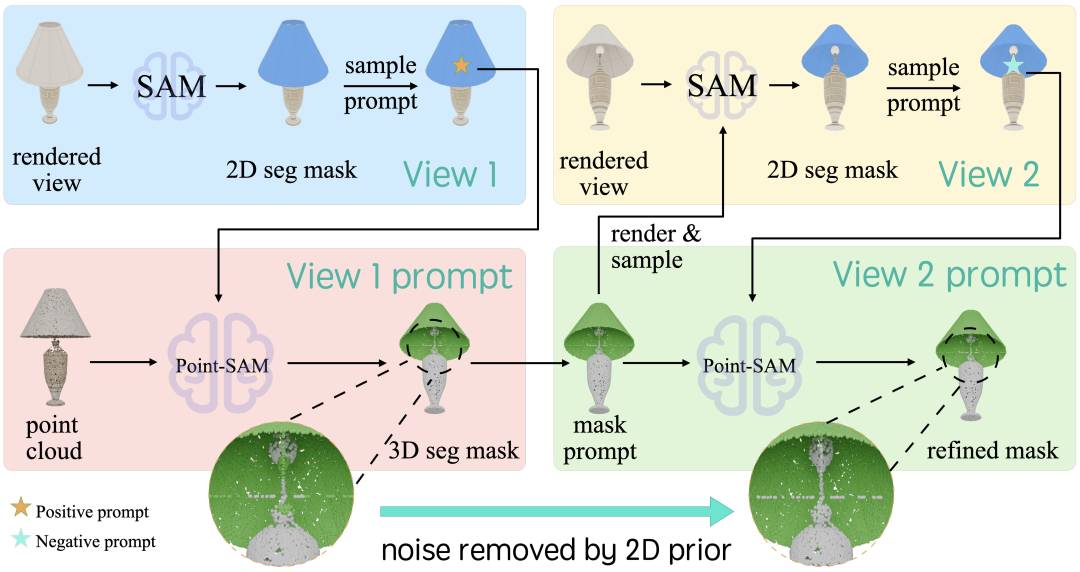
5. Point-SAM:互动引导下的3D分割变革模型
为满足对详细3D数据的日益增长的需求,研究人员推出了Point-SAM,这是一种基于变革者的3D分割模型。这个模型将大大提高3D数据处理的效率和精度。与传统的3D分割技术相比,Point-SAM能够提供更精细的数据,从而更好地满足各种需求。这一研究的推出,无疑为3D数据处理领域带来了一场革命。
划重点
-
研究人员推出了一种新型的3D分割模型Point-SAM -
Point-SAM基于变革者模型,提高了3D数据处理的效率和精度 -
Point-SAM的推出,为3D数据处理领域带来了一场革命
标签:3D segmentation, Point-SAM, Transformer model
原文链接见文末/5[5]
6. Gemma 2系列9B和27B模型现已开源
我们很高兴地宣布,Gemma 2系列的两款新型号——9B和27B现已正式上市。这两款新型号均秉承了Gemma 2系列的一贯优良传统,将先进的技术与优雅的设计完美融合。无论是在性能、可靠性还是易用性方面,Gemma 2的9B和27B都将为用户带来卓越的体验。我们对这两款新型号充满信心,并期待其在市场上的表现。
划重点
-
9B和27B均秉承了Gemma 2系列的优良传统,将先进的技术与优雅的设计完美融合。 -
无论是在性能、可靠性还是易用性方面,9B和27B都将为用户带来卓越的体验。
标签:Gemma 2, 新型号, 上市
原文链接见文末/6[6]
7. 论文:材料科学领域的语言模型
MatText是一套专为评估材料科学中语言模型性能的基准测试工具和数据集。这套工具和数据集的设计目标,是使研究者能够更有效地理解和评估语言模型在材料科学应用中的表现。语言模型在材料科学中的应用,可以帮助科学家更准确地预测和理解材料的性质和行为。MatText的开发,标志着语言模型在材料科学领域的应用迈出了重要的一步。
划重点
-
MatText是一套专为评估材料科学中语言模型性能的基准测试工具和数据集。 -
MatText的设计目标,是使研究者能够更有效地理解和评估语言模型在材料科学应用中的表现。 -
MatText的开发,标志着语言模型在材料科学领域的应用迈出了重要的一步。
标签:语言模型, 材料科学, 基准测试
原文链接见文末/7[7]
8. Mamba 2快速实现方案开源
本文主要介绍了如何快速实现Mamba 2,而不需要关联扫描。Mamba 2是一种新型的技术实现,其主要优势在于无需进行繁琐的关联扫描,大大提高了工作效率。这种实现方式不仅节省了大量时间,而且降低了出错的可能性。在GitHub Repo中,我们提供了详细的实现步骤和方法,供技术人员参考和使用。这将对进一步提高Mamba 2的使用效率,扩大其应用范围产生积极的推动作用。
划重点
-
GitHub Repo中提供了详细的实现步骤和方法
标签:Mamba 2, GitHub Repo, 技术实现
原文链接见文末/8[8]
每日AIGC
如果觉得内容有帮助,欢迎分享转发有需要的朋友。如果想第一时间跟踪AI前沿或者交个朋友,也可扫码添加微信(还请备注来意)。

👉关注「漫话开发者」,精选全球AI前沿科技资讯以及高质量AI开源工具,帮你给每天AI前沿划重点!👀
– END –
参考资料
原文链接见文末/1: https://github.com/ruc-nlpir/genir-survey?utm_source=uwl.me
[2]原文链接见文末/2: https://blog.fal.ai/introducing-aurasr-an-open-reproduction-of-the-gigagan-upscaler-2/?utm_source=uwl.me
[3]原文链接见文末/3: https://openai.com/index/finding-gpt4s-mistakes-with-gpt-4/?utm_source=uwl.me
[4]原文链接见文末/4: https://ai.meta.com/research/publications/meta-large-language-model-compiler-foundation-models-of-compiler-optimization/?utm_source=uwl.me
[5]原文链接见文末/5: https://point-sam.github.io/?utm_source=uwl.me
[6]原文链接见文末/6: https://www.kaggle.com/models/google/gemma-2?utm_source=uwl.me
[7]原文链接见文末/7: https://arxiv.org/abs/2406.17295v1?utm_source=uwl.me
[8]原文链接见文末/8: https://github.com/okarthikb/state-space-models/blob/main/models/mamba2.py?utm_source=uwl.me