
包阅导读总结
1. 足球预测、图模型、大模型、欧洲杯、球员关系
2. 本文介绍了程序员用图模型开发足球预测工具“智猜足球”,融合多种技术,分析球员关系,预测比赛胜负,准确率较高,还能展示球员配合与对抗,预估球队积分。
3.
– 开发背景
– 为验证前沿人工智能技术在体育赛事应用的可行性,拓展技术应用边界。
– 技术原理
– 构建球员关系网络图,分析近 30000 名球员协作关系。
– 借助前沿技术,量化球员元素,训练近 10000 场比赛数据。
– 让大模型推断球队胜负值。
– 影响因素
– 球员个人实力数据。
– 球员间配合相关因素,如位置、基础特征、配合和防守能力、战术素养等。
– 使用 Transformer 模型计算增益和对抗。
– 比赛预测
– 17 号 7 场比赛预测准确率 71%。
– 测试集准确率 53%(考虑平局)、71%(排除平局)。
– 输出模型结果至图数据库,展示图数据,预估球队积分。
思维导图: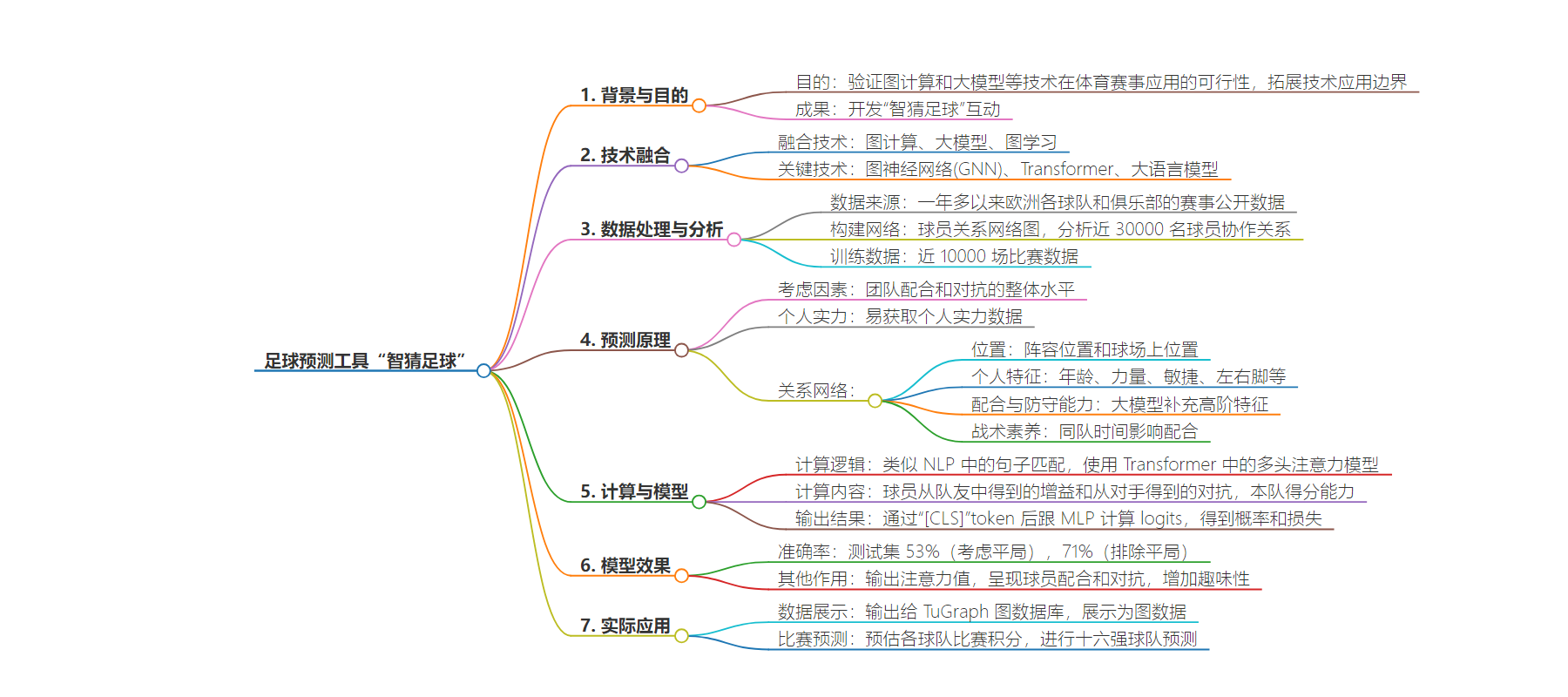
文章地址:https://mp.weixin.qq.com/s/kx9-rOd80tDD_1ryPXAf_A
文章来源:mp.weixin.qq.com
作者:TuGraph
发布时间:2024/6/20 14:17
语言:中文
总字数:2463字
预计阅读时间:10分钟
评分:84分
标签:图计算,大模型,足球预测,人工智能
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
2024年欧洲杯比赛正酣,分享我厂TuGraph程序员做的一件有趣的事。
为了验证图计算和大模型等前沿人工智能技术在体育赛事应用的可行性,拓展技术应用边界,他们开发了一项叫做“智猜足球”的互动。这项互动融合了图计算、大模型、图学习等技术,要找到足球比赛中的关键组合,从而为赛事走向提供依据。
图计算、大模型,可是一个比一个复杂的技术。听上去,是不是从毛线球里找头子?
但就是被这帮极客跑通了。
参考一年多以来欧洲各球队和俱乐部的赛事公开数据,利用图算法构建了一张球员关系网络图。你看,它好像一张蜘蛛网啊。
在这张网上分析了近30000名球员之间的协作关系,谁和谁传球多,谁和谁对抗多,全都呈现在这张“网”上。
借助图神经网络(GNN)、Transformer、大语言模型等前沿技术,量化球员间的默契配合与竞技对抗元素,训练了近10000场比赛数据。大模型,给我学!
最后,是时候表演真正的技术了——让大模型根据学会的知识,和每场比赛的选手阵营,推断球队的胜负值。
在17号 ,“智猜足球”分析的7场比赛中,有5场与实际比赛结果一致,准确率71%。
小编请TuGraph的程序员们
揭秘了他们的技术思路
接下来进入非常硬核的学习时间
在足球、篮球等团队运动中,决定胜负的因素远不止于个人实力,更重要的是团队配合和对抗的整体水平。每个球员在比赛中的表现不仅依赖于自身的技术,还取决于队友之间的默契配合和对对手的策略应对。这种复杂的交互关系使得比赛变得高度动态和多变。
通过图算法,我们可以将这些复杂关系有效地进行建模,为比赛的分析和预测提供科学依据。因此,要预测一场比赛的胜负,图模型自然成为了我们的首选:通过将双方阵容中的球员连在一起,比较他们的个人实力、团队配合和对抗强度,从而提供更精准的预测。
球员个人实力是影响比赛胜负的重要因素,我们可以很容易获得他们的个人实力数据,那么如何得到模型的另一半拼图——关系网络呢?
首先,我们要考虑哪些因素影响球员间的配合。最直观的是球员的位置,包括阵容里的位置(前锋之间的配合肯定会高于守门员与前锋)和球场上的位置(球员在球场上的热点如果相近,那么配合可能会更频繁)。我们可以从网上查到球员擅长的角色(前锋、中场、后卫)和球场上的热点,并把它们做成可学习的嵌入(learnable embedding),类似于NLP中的位置嵌入(positional embedding)。
有部分基础特征也能反映球员的配合和对抗的强度,如年龄、力量、敏捷、左右脚等,这些特征会作为球员个人特征送入模型。
其次是球员的配合和防守能力,比如某球员擅长争抢、短距离传球、进攻欲望强、有领导能力等。这些数据不是轻易能拿到的,网上的数据也不全。为了补齐球员这方面的数据,我们将球员的基础数据(如传球、速度、身高、体重等)喂给大模型,让大模型补充这些球员的更高阶特征,并用句子嵌入的方法做成球员特征。
最后是球员的战术素养。我们认为,如果球员在同一队待的时间越长,他们可能会接受类似的战术训练和指导,从而配合得更好。因此,我们建立了球员间的关系网络。如果他们在同一队待过,那么他们之间会有一条边,边上的特征为这个球队的特征,如球队世界排名等。
经过上述处理,我们得到了最终的球员个人特征。
对于一场比赛,我们需要计算来自队友的支持(buff)和来自对手的对抗(debuff),这样才能得到球员在这场比赛中能发挥出多少实力、对胜利作出多少贡献。这一计算逻辑和NLP中的句子匹配高度相似,因此我们使用了Transformer(在本应用中更体现其GNN属性)中的多头注意力模型(MHA,Multi-Head Attention)计算球员从队友中得到的增益和从对手得到的对抗;并算出面对对方阵容时,本队的得分能力。同时,我们还创建了一个‘[CLS]’token,把球员的发挥和比赛的胜负联系起来,最后通过‘[CLS]’token后跟一个MLP来计算logits,并用logits来得到有序多分类的概率和计算损失。
本方法使用公开数据中2023年的比赛作为训练集,2024年的比赛作为测试集,在测试集上得到53%的准确率(考虑平局),和71%的准确率(排除平局)。但这并不是本方法的上限,因为有较多比赛的数据不全,很多球员数据都是均值填充的,属于无效样本。
通过这套方法,我们不仅可以预测比赛的胜负,还能输出注意力值,直观地呈现球员之间的配合和对抗,为产品带来除了胜负以外的趣味性,一举多得。
经过GNN模型的训练和推理,我们将模型结果输出给TuGraph图数据库,展示为一目了然的图数据,进行解读。
B组小组赛的部分比赛。
截至写稿时,比了3场。3个黄色点表示3场比赛,依次是:意大利 vs 阿尔巴尼亚、克罗地亚 vs 阿尔巴尼亚、阿尔巴尼亚 vs 西班牙。
蓝色点表示球员,分成了几个区域:最左侧的是意大利球员,左、中两个黄点中间的是阿尔巴尼亚球员,中、右黄点间的是克罗地亚球员,最右侧的是西班牙球员。
连线表示球员在首发阵容参加了该场比赛。有的球员同时参加(首发)了两场比赛;有的没有,比如阿尔巴尼亚的马纳伊、拉奇,他们对战克罗地亚是首发,但不是对意大利的首发。
A组小组赛的部分比赛。
截至写稿时,比了4场。4个黄色点表示4场比赛。左上:苏格兰 vs 瑞士;右上:德国 vs 苏格兰;左下:匈牙利 vs 瑞士;右下:德国 vs 匈牙利。
蓝色点表示球员,分成了几个区域:最上面的是苏格兰球员,中间左侧的是瑞士球员,中间右侧(深蓝紫色标出)是德国球员,最下面的是匈牙利球员。
连线表示球员在首发阵容参加了该场比赛。
目前比过赛的。
小组赛踢完后应该形成6个团体,每个组内都连着。现在因为小组内有的队伍还没交过手,所以有分散的情况。
通过计算各球队的对抗实力,我们预估了各球队的比赛积分,做了十六强球队预测。
不管它分析得对不对,小编认为还是要不吹不黑。毕竟,硅基大脑的每一次进步,都值得被鼓励!