
包阅导读总结
1. 关键词:
– Amazon Aurora Serverless
– 资源管理
– 动态缩放
– 内存管理
– 实例管理器服务
2. 总结:
AWS 工程师发表关于 Amazon Aurora Serverless 资源管理和缩放的论文。该平台自动缩放数据库以应对工作负载变化,第二代设计聚焦就地缩放和内存管理,通过实例管理器和舰队管理器服务实现,多数缩放无需跨主机迁移,强调设计简单和反应式资源管理。
3. 主要内容:
– Amazon Aurora Serverless 平台
– 利用不同组件动态缩放和调整资源以满足客户工作负载需求。
– 客户用 Aurora Capacity Units 配置缩放范围,服务按需动态调整。
– 第二代设计
– 基于 ASv1 经验,支持 CPU 和内存热插拔。
– 解决内存管理挑战,修改 DB 引擎、Linux 内核和 AWS Nitro 管理程序。
– 服务管理
– 实例管理器服务基于需求趋势控制资源缩放。
– 舰队管理器服务关注中长期舰队规模和容量调整,必要时进行主机间迁移。
– 数据与结论
– 绝大多数缩放事件无需跨主机迁移。
– 强调设计简单和反应式管理,未来或引入更多预测元素。
思维导图: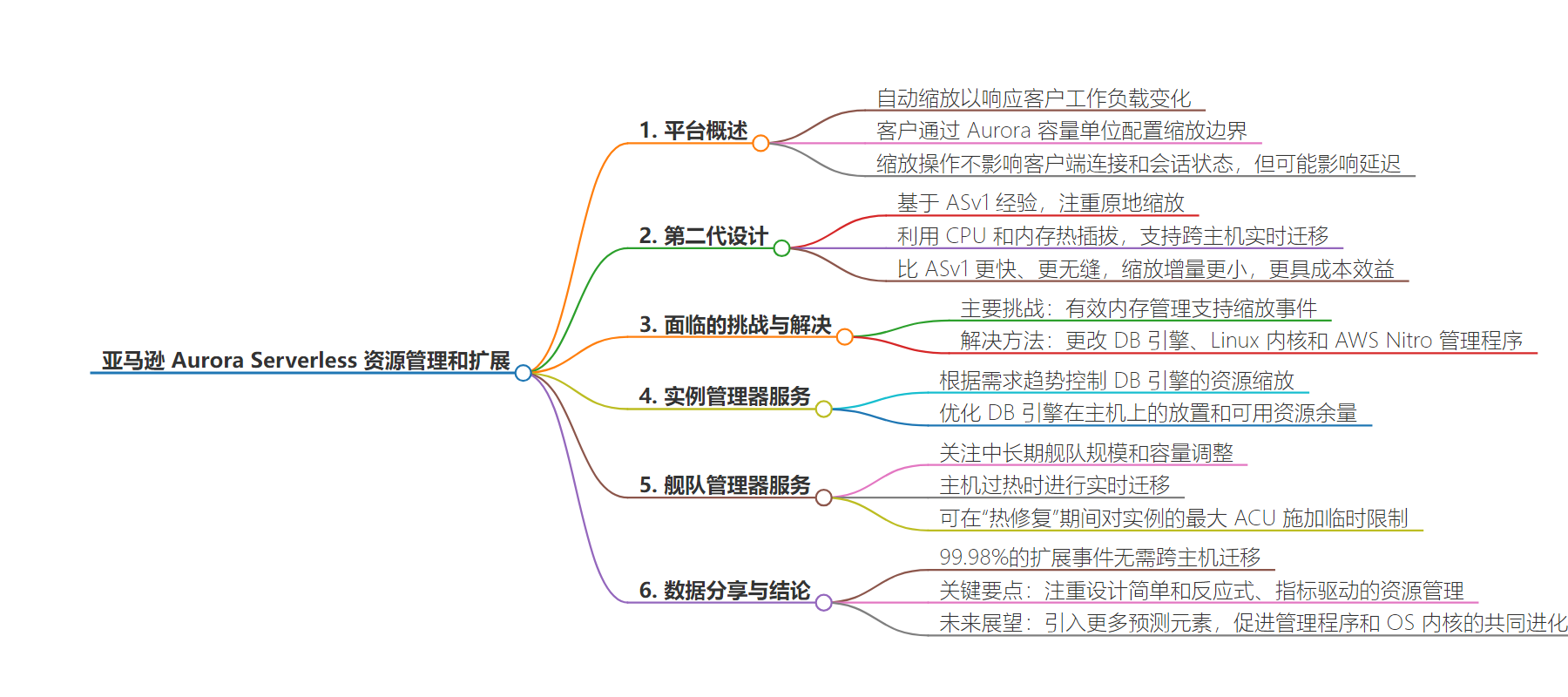
文章来源:infoq.com
作者:Rafal Gancarz
发布时间:2024/8/23 0:00
语言:英文
总字数:477字
预计阅读时间:2分钟
评分:92分
标签:Amazon Aurora Serverless,资源管理,数据库扩展,AWS,云计算
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
AWS engineers published a paper describing the evolution and latest design of resource management and scaling for the Amazon Aurora Serverless platform. Aurora Serverless uses a combination of components at different levels to create a holistic approach for dynamically scaling and adjusting resources to satisfy the needs of customer workloads.
Amazon Aurora Serverless automatically scales Amazon Aurora databases to respond to changing customer workloads and delivers cost optimizations, improved performance, and simplified operations. Aurora customers configure scaling bounds using Aurora Capacity Units (ACUs), and the services dynamically adjust resources according to demand. From the customer’s perspective, these scaling operations don’t require any interventions and don’t disrupt client connections or session states, but they may impact latency.
The current Aurora Serverless product is a second-generation design based on experiences from operating and supporting ASv1, which launched in 2018. The new design focused on in-place scaling, using CPU and memory hot (un)plug, supported by live migrations across hosts. Compared with ASv1, ASv2 offers faster and more seamless scaling, with smaller scaling increments, making it more cost-effective.
The team working on the second-generation solution had to address many challenges, the main of which was effective memory management for DB workloads that would support scale-up and scale-down events. Linux and DB engines tend to commit all available memory and hold on to it. Engineers changed DB engines, Linux kernel, and AWS Nitro hypervisor to allow more flexible memory management for varying workloads.
/filters:no_upscale()/news/2024/08/aurora-serverless-scale-resource/en/resources/1aurora-serverless-instance-1724329981067.jpeg)
Instance Manager Service (Source: Resource Management in Aurora Serverless)
Amazon Aurora utilizes a per-instance manager service to control the resource scaling of the DB engine based on the demand trends from all instances on the physical host. Optimizing the placement of DB engines across hosts and the available resource headroom allows Aurora Serverless to ensure sufficient resources are available on the host to accommodate dynamic workloads without the need to migrate those between hosts.
Aurora Serverless service manages large fleets of tens of thousands of compute instances at the broadest level. The fleet manager service focuses on mid to long-term fleet sizing and capacity adjustments based on desired utilization levels and predicted demand. Live migrations between hosts are used when hosts risk becoming “hot” to free up resources. Additionally, the fleet manager can impose temporary limits on maximum ACUs for instances during “heat remediation”.
/filters:no_upscale()/news/2024/08/aurora-serverless-scale-resource/en/resources/1aurora-serverless-fleet-1724329981067.jpeg)
Fleet Manager Service (Source: Resource Management in Aurora Serverless)
Engineers shared some data from Aurora flees in US AWS regions, pointing out that the vast majority (99.98%) of scale-up events didn’t need inter-host migrations and could be satisfied by an in-place scaling mechanism.
The paper concludes with some key takeaways, emphasizing focusing on design simplicity and a reactive, metric-driven approach to resource management. The team didn’t rule out introducing more predictive elements into the solution in the future and highlighted further opportunities for the co-evolution of hypervisors and OS kernels to better support DB workloads.