
包阅导读总结
1. 关键词:Microsoft、Phi-3.5 模型、开源、AI 发展、性能优势
2. 总结:Microsoft 推出 Phi-3.5 系列三个新开源 AI 模型,包括 Phi-3.5-mini-instruct、Phi-3.5-MoE-instruct 和 Phi-3.5-vision-instruct,具有不同特点和优势,在多种任务中表现出色,引发 AI 社区关注,采用 MIT 许可协议。
3. 主要内容:
– Microsoft 推出 Phi-3.5 系列开源 AI 模型
– Phi-3.5-mini-instruct:3.82 亿参数,适合基础快速推理,在内存和计算受限环境表现好,在某些基准测试中优于更大模型
– Phi-3.5-MoE-instruct:41.9 亿参数,采用混合专家架构,处理复杂推理任务,在多种基准中超越同类大模型
– Phi-3.5-vision-instruct:4.15 亿参数,整合文本和图像处理,擅长多帧视觉任务
– 训练背景
– 不同模型训练时长、使用的 GPUs 数量及处理的令牌数量不同
– 性能表现
– 在众多基准测试中表现出色,常超越其他领先模型
– 社区反应与许可协议
– AI 社区关注,评价积极
– 采用 MIT 许可协议,方便开发与应用
思维导图:
文章来源:infoq.com
作者:Robert Krzaczyński
发布时间:2024/8/31 0:00
语言:中文
总字数:548字
预计阅读时间:3分钟
评分:91分
标签:AI模型,开源,Microsoft,推理,多语言处理
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Microsoft launched three new open-source AI models in its Phi-3.5 series: Phi-3.5-mini-instruct, Phi-3.5-MoE-instruct, and Phi-3.5-vision-instruct. Available under a permissive MIT license, these models offer developers tools for various tasks, including reasoning, multilingual processing, and image and video analysis.
The Phi-3.5-mini-instruct model, with 3.82 billion parameters, is optimized for basic and fast reasoning tasks. It is designed to perform in memory- and compute-constrained environments, making it suitable for code generation, mathematical problem-solving, and logic-based reasoning tasks. Despite its relatively compact size, Phi-3.5-mini-instruct outperforms larger models such as Meta’s Llama-3.1-8B-instruct and Mistral-7B-instruct on benchmarks like RepoQA, which measures long-context code understanding.
The Phi-3.5-MoE-instruct model, which features 41.9 billion parameters, employs a mixture-of-experts architecture. This allows it to handle more complex reasoning tasks by activating different parameters depending on the input. The MoE model outperforms larger counterparts, including Google’s Gemini 1.5 Flash, in various benchmarks, demonstrating its advanced reasoning capabilities. This makes it a powerful tool for applications that require deep, context-aware understanding and decision-making.
The Phi-3.5-vision-instruct model, with 4.15 billion parameters, integrates both text and image processing capabilities. This multimodal approach allows it to handle various tasks, including image understanding, optical character recognition, and video summarization. It is particularly adept at handling complex, multi-frame visual tasks thanks to its support for a 128K token context length. Trained on a combination of synthetic and publicly available datasets, the Phi-3.5-vision-instruct model specializes in tasks like TextVQA and ScienceQA, providing high-quality visual analysis.
All three models in the Phi-3.5 series have strong training backgrounds. The Phi-3.5-mini-instruct was trained on 3.4 trillion tokens using 512 H100-80G GPUs over 10 days. The Phi-3.5-MoE-instruct model required a more extensive training period, processing 4.9 trillion tokens over 23 days with the same number of GPUs. The Phi-3.5-vision-instruct model was trained on 500 billion tokens using 256 A100-80G GPUs over six days. These extensive training processes have enabled the Phi-3.5 models to achieve high performance across numerous benchmarks, often exceeding other leading AI models, including OpenAI’s GPT-4o in several scenarios.
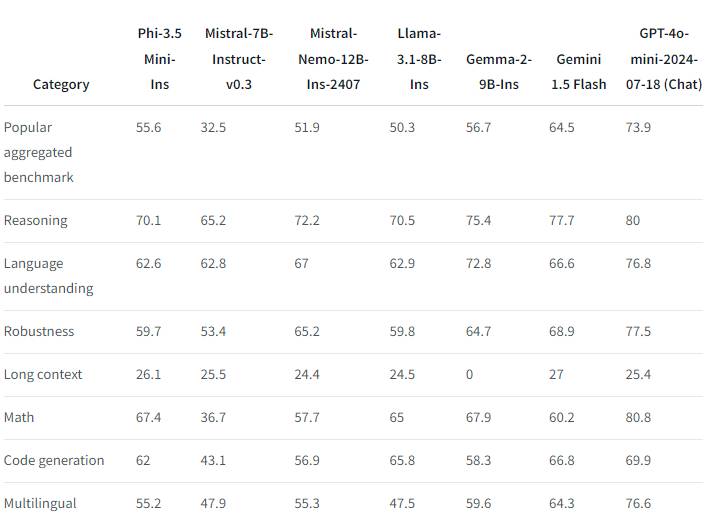
Benchmark comparison of Phi-3.5 mini-instruct and other leading AI models (Source: Hugging Face)
These benchmark results demonstrate how the Phi-3.5 models, especially the Phi-3.5 mini, compare to other leading AI models such as Mistral, Llama, and Gemini across different tasks. The data highlights the effectiveness of the Phi-3.5 models in tasks ranging from general reasoning to more specific problem-solving scenarios.
Reactions from the AI community highlighted the technical capabilities of the Phi-3.5 series, especially in multilingual and vision tasks. On social media platforms, users have noted the models’ performance in benchmarks and expressed interest in their potential applications. For example, Turan Jafarzade PhD commented on LinkedIn:
These advantages position Phi-3.5 SLM (small language model) as a competitive model for enterprise applications where efficiency and scalability are critical.
Danny Penrose added:
Impressive development! The ability to convert Phi-3.5 to the Llama architecture without performance loss opens up some exciting possibilities for model optimization. How do you see this impacting the broader adoption of these models in real-world applications?
The Phi-3.5 models are released under the MIT license, which allows developers to freely use, modify, and distribute the software for both commercial and non-commercial purposes. This license aims to facilitate the integration of AI capabilities into various applications and projects, supporting a wide range of use cases across different industries.