
包阅导读总结
1.
“`
Redis、多线程查询引擎、语义搜索、性能提升、向量数据库
“`
2.
Redis 推出增强版查询引擎,引入多线程技术提升性能,解决了传统单线程架构的局限性。进行了广泛基准测试,声称在速度和可扩展性上优于同类,新引擎满足生成式 AI 应用需求,为开发者提供更优解决方案。
3.
– Redis 推出增强版查询引擎
– 正值向量数据库受重视
– 引入多线程技术,提升查询吞吐量,保持低延迟
– 允许查询并发访问索引,实现垂直扩展
– 解决传统单线程架构局限性
– 长时间运行的查询导致拥塞和吞吐量降低
– 搜索操作复杂,结合多个索引扫描
– 新的多线程方法解决挑战
– 新架构与流程
– 主线程准备查询上下文并排队
– 各线程从队列取出任务并发执行
– 完成后结果发送回主线程
– 基准测试与比较
– 与三类向量数据库提供商比较
– 声称速度和可扩展性更优
– 满足生成式 AI 应用需求
– 如聊天机器人快速处理多步骤
– 开发者需重新思考数据架构
– 是综合解决方案的一部分
– 提供新引擎与发布计划
– 立即在 Redis Software 提供
– 秋季发布 Redis Cloud
思维导图: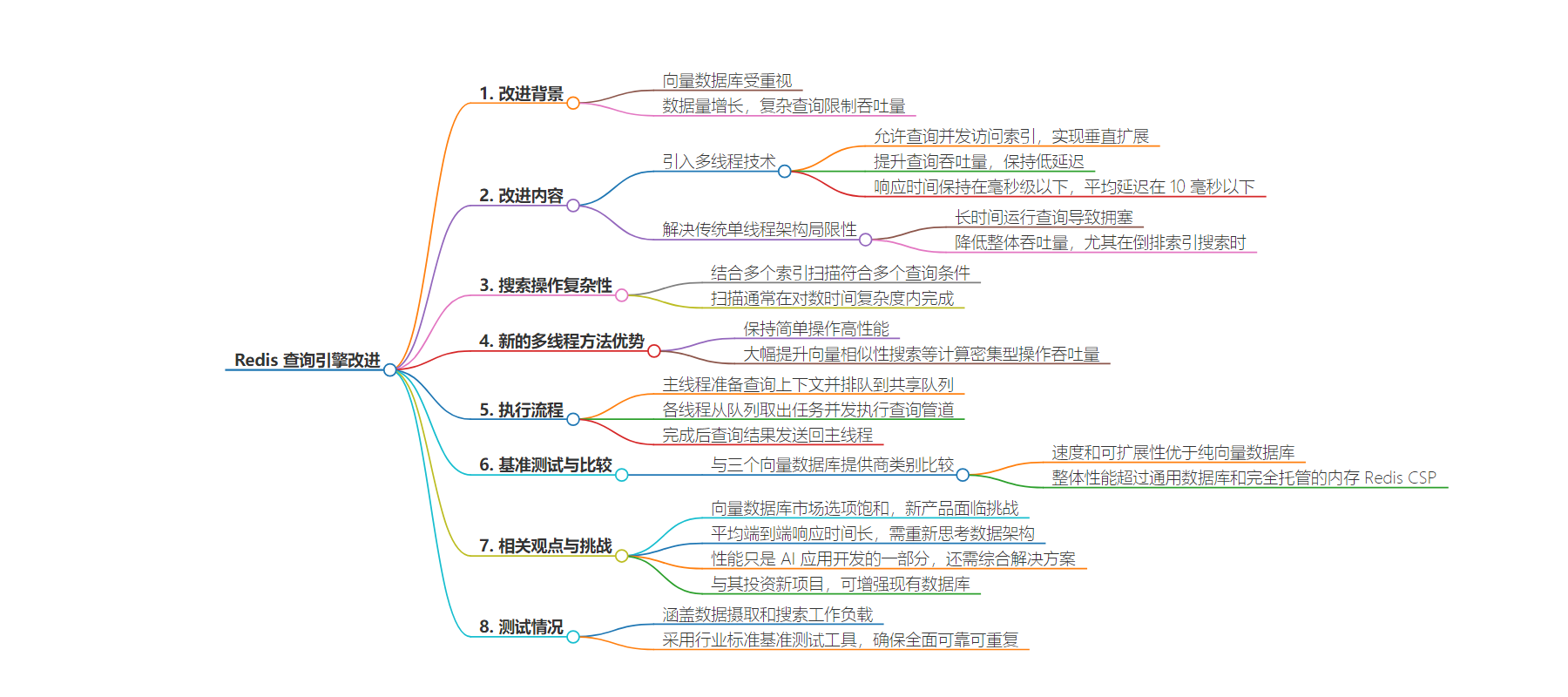
文章地址:https://mp.weixin.qq.com/s/oGHUlTH6GW6zL2Cq8SYFIw
文章来源:mp.weixin.qq.com
作者:Vinod??Goje
发布时间:2024/7/26 10:49
语言:中文
总字数:1999字
预计阅读时间:8分钟
评分:84分
标签:Redis,多线程,查询引擎,性能优化,实时处理
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Redis 这个广受欢迎的内存数据结构存储系统,最近推出了增强版的 Redis 查询引擎。这一发布正值向量数据库因其在生成式 AI 应用中检索增强生成(RAG)的重要性而日益受到重视之际。
Redis 宣布对其查询引擎进行重大改进,通过引入多线程技术,在保持低延迟的同时大幅提升查询吞吐量。Redis 表示:通过允许查询并发访问索引,实际上使 Redis 能够进行垂直扩展,从而同时提升 Redis 操作和查询的吞吐量。
下图展示了垂直扩展的情况。
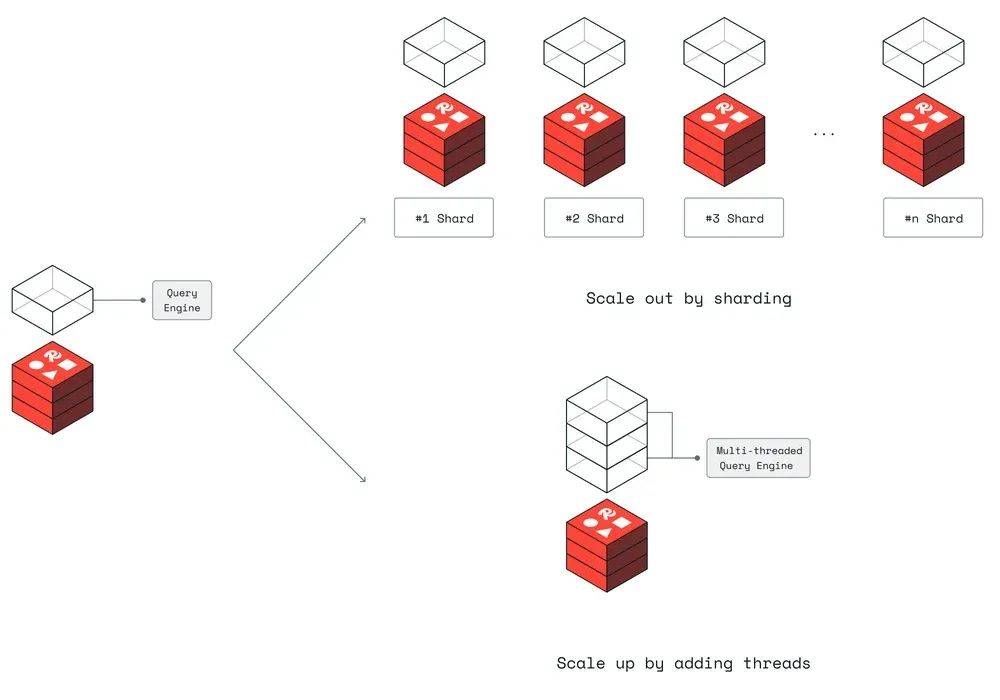
Redis 强调,这一进展在数据量增长到数亿个文档时尤为重要,因为复杂查询可能会限制吞吐量。Redis 声称,响应时间保持在毫秒级以下,查询的平均延迟在 10 毫秒以下。
Redis 承认,其传统的单线程架构在某些操作上存在局限性。长时间运行的查询在单线程上会导致拥塞,进而降低整体吞吐量,尤其是在使用倒排索引进行数据搜索时。
Redis 进一步解释了搜索操作的复杂性:
搜索并不是一个 O(1) 时间复杂度的命令。搜索通常结合多个索引扫描以符合多个查询条件。这些扫描通常在对数时间复杂度 O(log(n)) 内完成,其中 n 是索引映射的数据点数量。
Redis 强调,其新的多线程方法有效地解决了这些挑战,使 Redis 在保持高性能进行简单操作的同时,大幅提升了计算密集型操作如向量相似性搜索的吞吐量。
Redis 指出:“高效扩展搜索需要结合水平分布数据负载(向外扩展)和多线程垂直处理,启用索引访问的并发性(向上扩展)。”
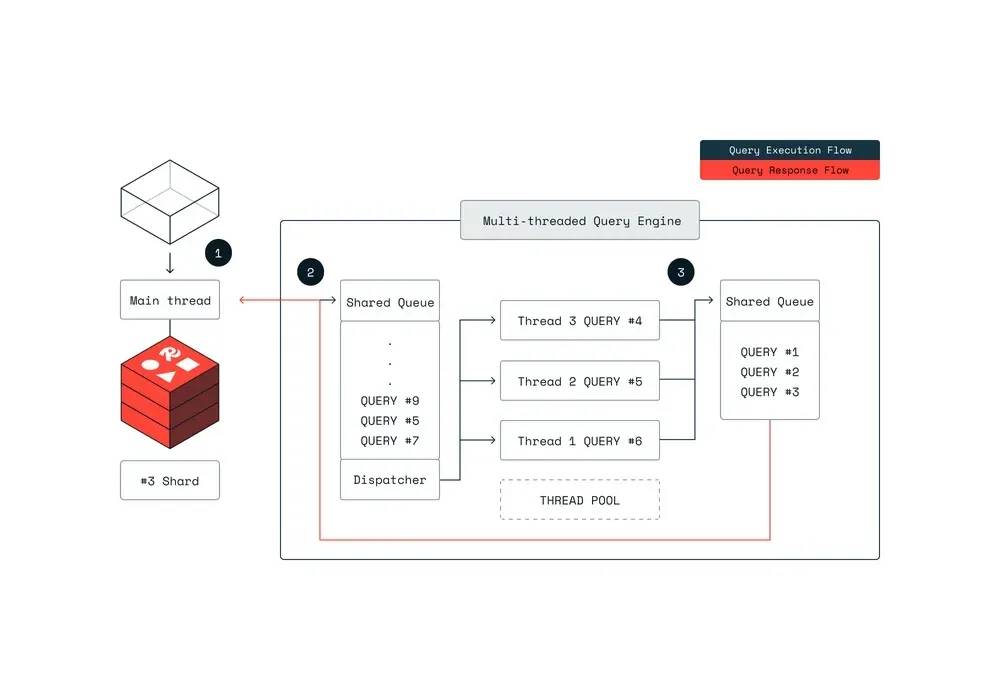
上图展示了新的架构,多个查询分别在独立的线程上执行。Redis 概述了一个三步流程:
首先,查询上下文(规划)在主线程上准备,并排队到共享队列。然后,各线程从队列中取出任务并并发执行查询管道。这允许我们在保持主线程处理更多传入请求(如其他 Redis 命令)的同时,执行多个并发查询。完成后,查询结果被发送回主线程。
Redis 声称,这种新架构使他们能够在处理多个复杂查询的同时,保持主线程对标准 Redis 操作的响应,从而提高整体系统吞吐量和可扩展性。
Redis 进行了广泛的基准测试,以验证其查询引擎的性能,并与三个向量数据库提供商类别进行了比较:纯向量数据库、具备向量功能的通用数据库和完全托管的内存 Redis 云服务提供商(CSP)。Redis 声称,其升级的查询引擎在速度和可扩展性上优于纯向量数据库,同时在整体性能上显著超过通用数据库和完全托管的内存 Redis CSP。
近年来,向量数据库市场显著增长,许多产品涌入市场。这种激增为新进入者和用户带来了挑战。行业专家指出,市场向量数据库选项已经饱和,新产品很难脱颖而出并找到独特的价值主张。
Reddit 首席工程师 Doug Turnbull 指出:在向量搜索中,我们有几十种选择。作为这种选择的 “客户”,领域变得不堪重负…… 向量检索不再是问题。解决实际检索问题的难点不只是获取向量,而是围绕它的一切。
这种观点强调了需要综合解决方案来应对 AI 驱动的数据检索中的更广泛挑战。
新的 Redis 查询引擎声称查询吞吐量比上一代提高了 16 倍。特别是,该查询引擎满足了生成式 AI 应用的需求,如依赖实时 RAG 的聊天机器人,必须在检索向量数据库中的数据时快速处理多个步骤。
Gmail 创始人 Paul Buchheit 提出了 “100 毫秒规则”,即每次交互应在 100 毫秒内完成,以给用户一种即时的感觉。
RAG 架构中延迟边界的细分显示:网络往返、LLM 处理、生成式 AI 应用操作和向量数据库查询,导致平均端到端响应时间为 1,513 毫秒(1.5 秒)。为应对这一挑战,开发者必须重新思考他们的数据架构,以构建接近 100 毫秒规则的实时生成式 AI 应用。实时 RAG 对于保持应用速度,同时利用 AI 功能至关重要,可以确保用户体验接近即时的交互,并保持与应用程序的互动。
Vectera 的 Ofer Mendelevitch 提醒我们,虽然向量数据库的性能很重要,但它只是 AI 应用开发更大技术图景的一部分。
确实,RAG 是目前构建基于自有数据的可信 LLM 应用最流行的方法,你确实需要强大的语义搜索能力作为整体检索能力(RAG 中的 R)的一部分,但向量数据库只是整体堆栈的一部分,可能还不是最重要的。
RisingWave Labs 创始人吴英骏对向量数据库的发展提供了一个补充性观点:
与其投资新的向量数据库项目,不如集中精力在现有数据库上,并探索用向量引擎增强它们的机会,使它们更强大。
Redis 增强其现有基础设施的方法与这一观点一致,有可能为开发者提供更加集成和高效的解决方案。
综合基准测试过程涵盖了数据摄取和搜索工作负载。在摄取方面,Redis 测量了使用分层可导航小世界(HNSW)算法、近似最近邻(ANN)搜索进行数据摄取和索引的时间。在查询方面,他们专注于 K 最近邻(k-NN)搜索,测量每秒请求数(RPS)和平均客户端延迟,包括往返时间(RTT)。
Redis 基于 gist-960-euclidean、glove-100-angular、deep-image-96-angular、dbpedia-openai-1M-angular 数据集,具有不同的向量维度和距离函数进行基准测试,以确保测试的全面性。模拟环境采用行业标准的基准测试工具,包括 Qdrant 的 vector-db-benchmark,以提供可靠且可重复的结果。
Redis 已在 Redis Software 中立即提供了新的查询引擎,并计划在秋季发布 Redis Cloud。