
包阅导读总结
1. 数据库、JSON字段、NAS、存储方案、降本增效
2. 本文讲述了因数据库费用增长快,排查出一张存有大JSON字段的表占据大量空间,经过思考选择NAS存储方案,通过添加注解和拦截器实现数据存NAS和读NAS,介绍了方案特点、优缺点及未来展望。
3.
– 问题背景
– 数据库费用增长快,发现一张有大JSON字段的表占据大量空间
– 数据与代码特点
– 数据不能删除、永久保留、只插入低频查询
– 底层服务、功能简单、单行插入和ID查询
– 改造过程
– 思考能否换数据库或存OSS、NAS
– 尝试阿里云PolarDB分区表功能,因不成熟放弃
– 代码编写
– 增加拦截器拦截数据库命令
– 添加表注解和字段注解
– 实现数据存NAS和读NAS
– 测试
– 注入拦截器
– 实体增加注解
– 进行插入、查询、更新等测试
– 总结
– 方案特点包括降本增效、代码改动小等
– 存在未能解决事务等缺点
– 提出未来展望如做成自动配置装配等
思维导图: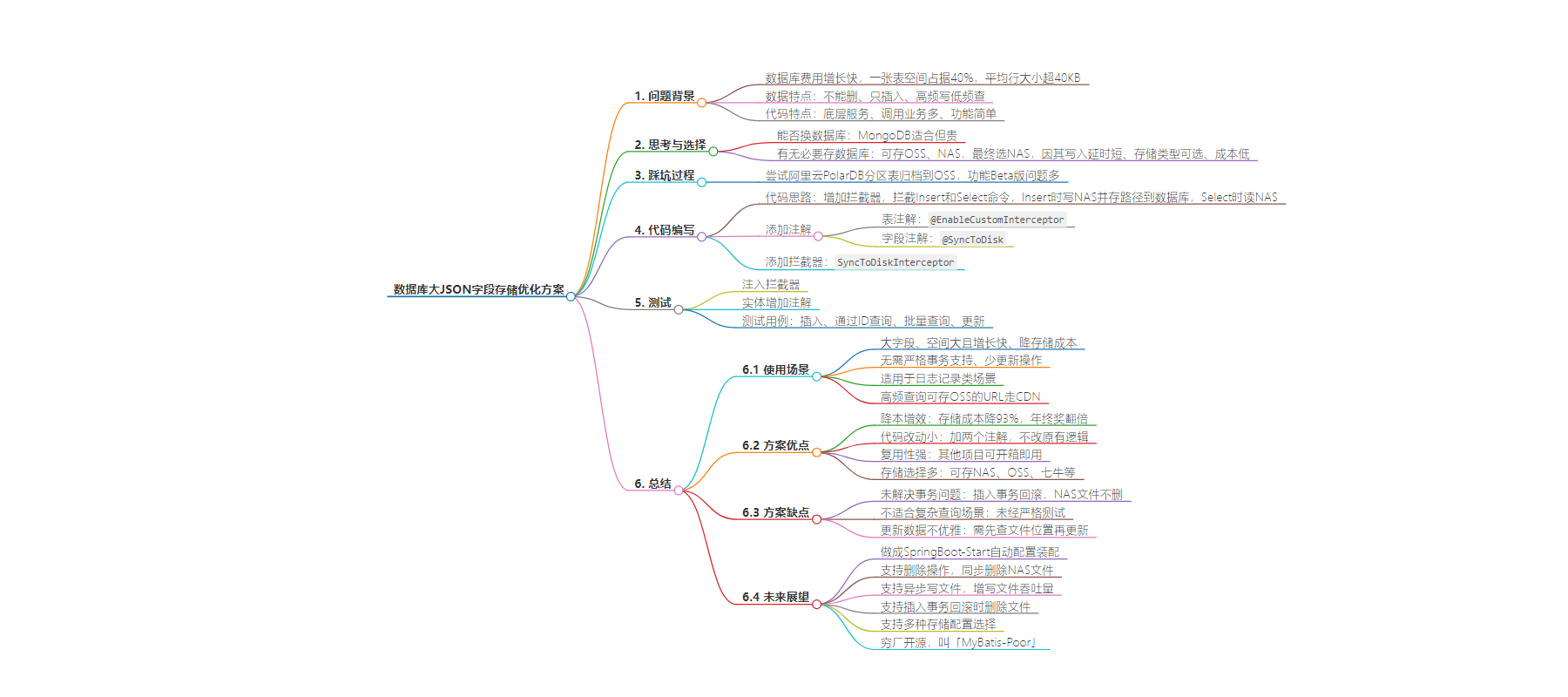
文章地址:https://juejin.cn/post/7393293636653203475
文章来源:juejin.cn
作者:赵侠客
发布时间:2024/7/20 3:27
语言:中文
总字数:2349字
预计阅读时间:10分钟
评分:84分
标签:数据库优化,性能优化,存储成本降低,NAS存储,MyBatis拦截器
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
原文:赵侠客
前言
近日CTO让我排查下最近数据库费用为什么增长的这么快,我们数据库使用了阿里云的按量付费,费用增长快肯定是数据空间增长的非常快,于是我统计了一下所有表的物理空间大小,然后发现了一张数据库刺客,这张表的空间占据了整个数据库容量的40%左右,表里主要存了一个大JSON字段,平均行大小超过了40KB。问题找到了,那么该怎么解决这个问题呢?
「数据特点」
首先我向产品了解这张表的数据特点:
- 不能删除,永久保留
- 只会插入,不会修改
- 高频写入,低频查询
然后我阅读了这张表的dao层代码,并梳理了一下相关代码的特点:
「代码特点」
- 底层服务,调用业务众多
- 功能简单,单行插入和ID查询
改造过程
「思考过程」
面对这个问题我做了如下思考:
- 写代码人已走,不要抱怨前人
- 能否换数据库?换什么数据库?
- 有没有必要存数据库?
第2点换数据库肯定是可以的,而且这中业务场景MongDB这种文档型数据库再适合不过了,不过MondBD也是比较贵的。第3点这种不变数据好像不放数据库也可以,和静态化文件业务场景类似,难道不能存OSS、NAS吗?考虑到OSS的特点是写慢查快,NAS写入比OSS延时短,而且NAS还有各种存储类型可以选则,如容量型、性能型、归档型、极速型等,我们这个业务是写多读少,所以最后选择的方案是将这部分数据存NAS,那么该如何存呢?
「踩坑过程」
本想着通过阿里云PolarDB分区表来将数据按月分区,然后将老的分区数据自动归档到OSS,成本可以降低97%,也不用改动业务代码,可是阿里云这个功能还是Beta版本,用了一下问题比较多,还帮他们发现了一个BUG,一个分区语句居然将数据库所有表对应的数据库搞乱了,所有业务都报表不存在,数据库里表是存在的,后来他们说是Proxy出了问题,还好是在测试环境,要是生产环境就直接走人了,感觉这个功能不太成熟,还是安全第一,自己撸代码角度解决吧。
阿里云
PolarDB 4.3万/TB/年
MongDB 3.4万/TB/年
OSS 0.1万/TB/年
NAS 0.3万/TB/年
代码编写
「代码思路」
我们DAO层用的是Mybatis,那么撸代码去解决这个问题思路是这样的:
- 增加一个拦截器,拦截数据库Insert和Select命令
- 在Insert时,获取对象JSON内容写入NAS,将文件路径写数据库
- 在Select时,获取NAS文件路径,读取文件内容后返回到对象中
- 添加表注解和字段注解,只对指定的字段生效
「添加注解」
添加表注解
@Target(ElementType.TYPE) @Retention(RetentionPolicy.RUNTIME) @Documented public @interface EnableCustomInterceptor { }添加字段注解
@Target(ElementType.FIELD)@Retention(RetentionPolicy.RUNTIME)@Documentedpublic @interface SyncToDisk { String rootPath();}「添加拦截器」
添加Mybatis拦截器,拦截所有插入和查询请求,在拦截器中对插入和查询进行数据存NAS和读NAS
@Intercepts( { @Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class}), @Signature(type = Executor.class, method = "update", args = {MappedStatement.class, Object.class}) })public class SyncToDiskInterceptor implements Interceptor { @Override public Object intercept(Invocation invocation) throws Throwable { Object[] args = invocation.getArgs(); Executor executor = (Executor) invocation.getTarget(); Connection connection = executor.getTransaction().getConnection(); MappedStatement mappedStatement = (MappedStatement) args[0]; final Class<?> entityClass = getMapperGenericClass(mappedStatement); if (entityClass.getAnnotation(EnableCustomInterceptor.class) != null) { if (args.length == 4) { Object result = invocation.proceed(); traverseParam(mappedStatement.getSqlCommandType(), result, entityClass, connection); return result; } else { Object sqlParams = args[1]; traverseParam(mappedStatement.getSqlCommandType(), sqlParams, entityClass, connection); } } return invocation.proceed(); } private void traverseParam(SqlCommandType sqlCommandType, Object param, Class<?> entityClass, Connection connection ) { if (param == null) { return; } if (param.getClass().getAnnotation(EnableCustomInterceptor.class) != null) { interceptField(sqlCommandType, param, entityClass,connection); } else if (param instanceof Map) { final Map<?, ?> map = (Map<?, ?>) param; for (Object value : map.values()) { traverseParam(sqlCommandType, value, entityClass, connection); } } else if (param instanceof Collection) { final Collection<?> collection = (Collection<?>) param; for (Object item : collection) { traverseParam(sqlCommandType, item, entityClass, connection); } } } private void interceptField(SqlCommandType sqlCommandType, Object param, Class<?> entityClass, Connection connection) { if (SqlCommandType.SELECT.equals(sqlCommandType)) { } if (SqlCommandType.INSERT.equals(sqlCommandType)) { } if (SqlCommandType.UPDATE.equals(sqlCommandType)) { } }}测试
「注入拦截器」
将自定义的Mybatis拦截器注入Spring容器中
@Bean public Interceptor SyncToDiskInterceptor() { return new SyncToDiskInterceptor();}「实体增加注解」
将我们要同步数据库实体对象字段增加注解
@Data@TableName("user_oss")@EnableCustomInterceptorpublic class User { @TableId private Long id; @SyncToDisk(rootPath = "/tmp/saveToDisk") private String userConfig; @SyncToDisk(rootPath = "/tmp/saveToDisk") private String userInfo;}「测试用例」
插入
@Testpublic void testInsert() { User user =new User(); user.setUserInfo("赵侠客1"); user.setUserConfig("赵侠客公众号1"); userMapper.insert(user);}通过ID查询
@Testpublic void testQuery() { User user = userMapper.selectById(1L); Assertions.assertEquals("赵侠客",user.getUserInfo()); Assertions.assertEquals("赵侠客公众号",user.getUserConfig());}批量查询
@Testpublic void testQueryList() { List<User> users = userMapper.selectList(new QueryWrapper<>()); users.stream().forEach(x->{ log.info("user {}->{}",x.getId(),x.getUserConfig()); });}更新
@Testpublic void testUpdate() { String newTrueName=String.valueOf(System.currentTimeMillis()); User user = userMapper.selectById(1L); user.setUserInfo(newTrueName); userMapper.updateById(user); User user1 = userMapper.selectById(1L); Assertions.assertEquals(newTrueName,user1.getUserInfo());}总结
本方法完全是自己脑洞大开想出来,感觉路子有点野,我在市面上没见过类似的来源项目,不知道市面上有没有类似的需求,大家可以评论区讨论下,总结本方法的特点
「使用场景」
-
数据库存在大字段,空间非常大,增长比较快,为了降低存储成本
-
不需要严格事务支持,没有频繁更新操作
-
非常适用于日志记录类业务场景
-
高频查询可以存OSS的URL,使用方通过URL走CDN解决高频读问题
「方案优点」
- 降本增效:存储成本降低93%,CTO肯定给你年终奖翻倍
- 代码改动小:只需要增加两个注解,原有业务逻辑不需要改动
- 复用性强:其它项目如有类似需求,引入依赖,开箱即用
- 存储选择多:在不想换数据库的情况下,可以将大字段存NAS,OSS,七牛等更便宜的存储
「方案缺点」
- 未能解决事务问题:如果数据库插入事务回滚,NAS文件不会删除
- 不适合有复杂查询业务场景:代码未经严格测试,不知道其它复杂场景会不会有问题
- 更新数据不太优雅:更新数据时需要从数据库通过ID查出文件位置再更新,不能通过其它字段更新数据
「未来展望」
- 做成SpringBoot-Start自动配置装配,方便使用
- 支持删除操作,数据库删除后NAS文件同步删除
- 支持异步写文件,增加写文件吞吐量
- 支持插入事务回滚时删除文件
- 支持储存可配置,如NAS,OSS,七牛等多种选择
最后如果穷厂多可以做成开源项目,名字就叫 「MyBatis-Poor」,不穷的厂也不会在乎数据库这点存储费用,数据库配置直接拉满,大JSON直接存就完。