
包阅导读总结
1.
关键词:QQ 频道、前端网关、性能优化、可观测性、Node 方案
2.
总结:本文介绍了 QQ 频道前端网关的升级历程,包括背景、方案选型、遇到的问题及解决办法,如 tRPC 协议转换、应对黑产攻击、解决请求超时等,还提及性能优化、支持 WebSocket 等成果,最后总结选择 Node 方案的原因。
3.
主要内容:
– 生于 B 端:先让自己满意
– 传统调用 RPC 接口流程繁琐,分析 tRPC 协议结构,通过对 HTTP 路径约定实现消费 tRPC 接口。
– 长于 C 端:跨越边界
– 小程序接入面临挑战,需明确请求链路,根据不同服务场景进行请求元信息转换,实现协议转换。
– 提升安全/可用性
– 安全:遭遇黑产攻击,配置安全策略。
– 可用性:解决请求超时,发布自检保证服务稳定。
– 提升性能/效率:实用第一
– 性能:改造 TSW/NGW,提升单核 QPS 和请求成功率。
– 支持 WebSocket:选择协议、低成本接入、保证消息可靠送达。
– 效率:沉淀文档,建设工具。
– 提升可观测性:深度是被逼出来的
– 分析错误比例上升问题,最终发现是缓存机制缺失,实现应用内链接缓存和复用,并完善监控。
– 总结:以躺平的心态完成不躺平
– 介绍选择 Node 方案的原因,包括使用体验、稳定性、响应及时高效、性能持续优化及业务需求。
思维导图: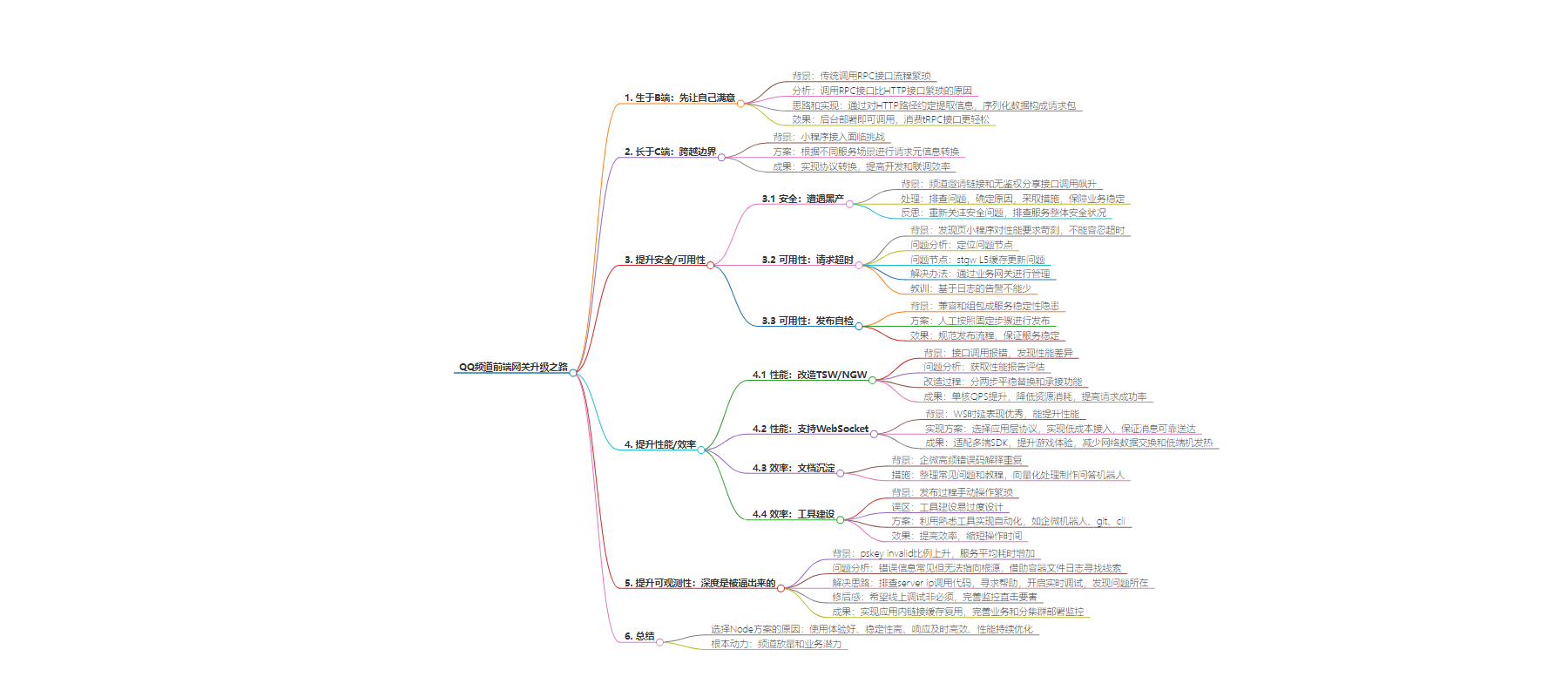
文章地址:https://mp.weixin.qq.com/s/R4OHIOhcSb2QsR_D1Z-wKw
文章来源:mp.weixin.qq.com
作者:付志远
发布时间:2024/6/17 9:50
语言:中文
总字数:8528字
预计阅读时间:35分钟
评分:84分
标签:性能优化,Node.js,WebSocket,可扩展性,网关架构
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
👉目录
1 生于 B 端:先让自己满意
2 长于 C 端:跨越边界
3提升安全/可用性
4提升性能/效率:实用第一
5提升可观测性:深度是被逼出来的
6 总结:以躺平的心态完成不躺平
本文亮点提炼:
每日请求量从几千到上亿
小程序和H5都能使用腾讯开源tRPC接口
单核QPS从2K提升至2W
请求成功率从99.985%提升至99.997%
性能:支持WebSocket
本文通过介绍整个历程中遇到的关键问题和解决办法,提供网关建设中的一些可复用经验。长文干货,建议先点赞收藏,慢慢品阅!
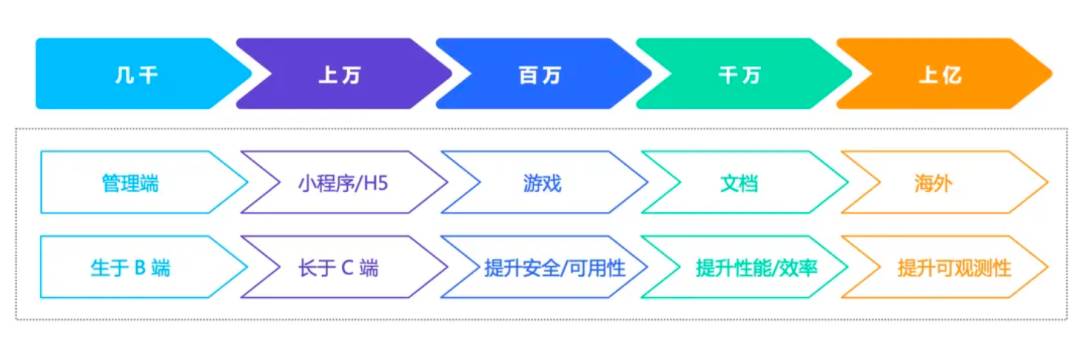
(从左到右的量级为累计)
1.1背景
1.2分析
message RequestProtocol {uint32 version = 1;uint32 call_type = 2;uint32 request_id = 3;uint32 timeout = 4;bytes caller = 5;bytes callee = 6;bytes func = 7;uint32 message_type = 8;map<string, bytes> trans_info = 9;uint32 content_type = 10;uint32 content_encoding = 11;}
1.3思路和实现
-
只需对 HTTP 的路径进行一致性约定,即可按照固定规则提取出 RequestProtocol 中的 callee 和 func;例如,频道使用的约定如下:
-
HTTP 头中的其他信息可以根据业务场景映射到 trans_info 中; -
包头的 proto 固定,我们使用这个固定的 proto 把上面的数据序列化为二进制。
1.4 效果
2.1 背景:小程序接入
2.2方案
-
标准服务场景:直接与后台 Server 进行通信。; -
经过 OIDB 代理的服务场景:借助 OIDB 代理和后台 Server 通信。 -
经过 SSO 代理的服务场景:借助 SSO 代理和后台 Server 通信。
-
请求元信息转换按照 QQ 频道后台 tRPC Server 的默认约定进行。(这里略过,不同业务有不同约定)
2.3 成果:难路是捷径
-
第一次和这么多团队打交道:客户端、跨平台、基础平台、互联、业务后台。 -
两周打了最多的电话,麻烦了十几位大佬请教代码逻辑、开权限。 -
参照 QQ NT 和 SSO,实现了第一版协议转换,可以从 JSAPI 无缝切到 HTTP,向更灵活的服务调用模式迈出关键一步; -
此外,对 QQ 频道的服务架构和网络链路有了整体框架,很快在下次问题定位中派上了大用场;
3.1 安全:遭遇黑产(背景)
-
频道邀请链接和一个无鉴权的分享接口(对应协议转换服务)调用飙升;
-
短链码服务高负载,但是进程没挂,而且扩容没有让失败率略微下降! -
某个服务链接数有限制,或者耗尽,而且最有可能是 MySQL。
-
针对无鉴权的接口,一定要配置安全策略,对 IP、UA 等进行更严格的限频; -
特别关注 k8s 二次扩容特性,的二次扩容特性,虽然它是一种紧急保命策略,但也可能引发其他问题(比如这里):
3.2 可用性:请求超时
背景
问题分析
问题节点
STGWL5缓存更新问题
bug原因
解决办法
-
通过业务网关进行管理:由于业务服务(如缩扩容、迁移等)经常变动,而网关相对稳定,因此,将业务服务配置在一个稳定的网关之后是最佳解决方案。
教训
-
基于指标的告警固然重要,基于日志的告警也不能少(敏感度更高); -
正是由于这个问题,,催生了 STGW 后建设业务网关的想法;
3.3 可用性:发布自检
背景
方案
-
step 1: review 发布变更准备完整的代码 diff,供二次检查; -
repeated:枚举变更点(变更点包括:配置、数据库表结构、接口、依赖服务)变更内容; -
当前变更的依赖项(依赖的其他变更项,比如配置、数据库变更等); -
step 2:确定发布步骤根据变更及变更的依赖项确定发布次序。 -
step 3:确定更新策略手动分批发布:微小修改(包括配置变更) -
step 4:发布过程亲眼看到第一个 pod 重建;
效果
4.1 性能:改造 TSW/NGW
背景
问题分析
为了使性能评估结果具有实际意义,我们需要一份能够完全镜像真实环境的性能报告。
import { sleep, check } from "pts";import HTTP from "pts/HTTP";export const options = {};export default function main() {let response;response = HTTP.get("HTTPs://xx.com/apisix/");check("status equals 200", () => response.statusCode.toString() === "200");}
import { sleep, check } from "pts";import HTTP from "pts/HTTP";export const options = {};export default function main() {let response;response = HTTP.get("HTTPs://xx.com/tsw/");check("status equals 200", () => response.statusCode.toString() === "200");}
-
使用 APISIX 平稳替换 NGW 和 TSW 的功能;
-
APISIX 无缝承接 NGW/TSW 的路由/灰度/染色功能 ; -
单核 QPS 从 2K 提升至 2W,显著降低了 CPU 和内存的资源消耗; -
根据最近 7 天的 STGW 监控数据,请求成功率从 99.985% 提升至 99.997%;(整体平均耗时略有下降,但不具备可比较性,因为后端负载有不重叠部分)。
4.2 性能:支持 WebSocket
背景
实现方案
协议选择
-
socketio 已经在公司内其他业务的生产环境中经受了百万级消息每秒的考验;
低成本接入
-
WS server 只做“接线员”角色:把 client 和 server 的 socket 连起来,就算完事了; -
WS server 做“邮局”的角色:业务 server 不用管 client 的存在,只要告诉 WS server 消息发给谁就可以了,WS server 保证最大可能送达;
|
|
||
|
|
|
消息可靠送达
-
业务 server 指定向某个用户推消息,但是用户不在线(没有活跃 socket)怎么办?
-
消息确认:client 接收每个消息需要回复 ack 命令字,否则进入补发机制; -
成果
-
适配三端(H5/QQ 小程序/cocos)的 SDK;
4.3 效率:文档沉淀
背景
4.3 效率:工具建设
背景
-
发布过程,比如检查配置、灰度比例设置、配置更新等都需要手动进行。
误区
方案
-
新网关也接入企微机器人设置染色/转发,和 tsw 一样的方式;
-
重要配置(白名单、oidb 命令字等),使用 git 管理,采用代码一样的 review 进行变更;
-
配合 ci,配置变更->审批->生效,完全自动化。 -
cli 负责代码生成:以命令行的形式,自动生成符合网关约定的调用 SDK、接口出入参数类型、Mock 规则等;
效果
5.1背景
-
pskey invalid 比例上升,略微下降后再上升;
5.2问题分析
猜想、验证
polaris 版本有变动,而新版本修改了 server ip —— 这是首先想到的最可能原因。
版本确实升级了(0.3.x -> 0.4.x),经过 diff 两个版本相关源码后,发现 server ip 没有任何更改。
否认了 server ip 变更的猜想后,必须调整 Debug 思路:
-
继续向上排查 server ip 的调用代码;
-
寻求北极星助手帮助;
寻求协助
两个版本之间的变动十分多。为了更快解决问题,决定立即寻求相关开发团队的帮助:
可能并不是应用代码存在问题,也稍微放心了点。
但是,运行一段时间后,重建的pod 再次出现了上面的报错。放下的心再次悬起来:立即登录 pod,对报错的 ip telnet 测试,网络连通没问题,所以还是应用代码的问题!
非常手段
时间紧迫,无奈只能走钢丝:对线上环境开启实时调试。
太久没这样搞过,一边隔离 pod,一边手忙脚乱查自定义调试端口的写法(生产环境对可访问端口有严格限制):
(…略掉大量无借鉴意义的试验细节)
最终在 memory 的快照中发现了端倪:
按 retained size 倒序后,出现了 PolarisGRPCClient。
展开 PolarisGRPCClient 后发现,每个 client 还都一个 pool:
既然有 pool,client 被设计为复用,但却有这么多 client,每个还有独立的 pool,显然有问题:要么该销毁的时候没销毁,要么缺失了缓存机制。
瞬间惊醒:缓存!
18 个月前写下这个函数的时候,特意留下提醒:
之前一直把目标聚焦在北极星,问题压根不在这,而是使用北极星的库:trpc-rpc-client。
查看 trpc-rpc-client 最新版的源码,果然 createObjectProxy 没了缓存。
5.3解决思路
5.4修后感
-
我喜欢听法医笔记,99% 依靠摄像头就能破案,但传统刑侦技能依然不能丢,为了可能的 1%。
-
希望线上调试永远不会成为必须的选项,如果 bug 真的落到监控死角,不要忘了这一救命办法:node –inspect=0.0.0.0:80。
-
用了一周才走完这 “10 分钟的 bug 修复”,期间思考各个现象、指标背后的关联信息、翻看库代码。如果下次,我希望有监控能帮助我直击要害,而不是绕了这么远:
5.5成果
-
实现应用内链接缓存和复用,建链+编解码平均在 5ms 内;
-
完善业务指标的监控:关键页面 PV/UV、关键接口耗时;
-
加强分集群部署的监控:核心系统指标、服务指标的横向对比;
在流量增长、功能扩展与性能优化的交织下,把一个协议转换发展为业务网关。每一步的发展都不是事先规划的,而且和最初的设想完全不同。
当时同时存在其他可用的替代方案:JSAPI(客户端方案)、HTTPSSO(后台方案),为什么最后落到 Node(前端)来做呢?我觉得一句话总结,是开发选择了 Node。
Node只是三个选项中的一个,最后前端、游戏、其他业务的开发(比如腾讯文档)、包括后台,选择了 Node。通过上面的过程,我归纳了 4 个原因:
1. 使用体验
每个开发会用脚投票,不好用就会选择其他替代方案。我熟悉前端最习惯的调用方式:
同时为了让后台的服务不改动也能被尽可能多的方式调用**(APP、小程序、H5、管理端),我做了大量工作,这也是不少后台希望走 Node调用的原因。
2. 稳定第一
Node在测试环境、正式环境的稳定性都被认可。相对于其他调用方法,Node测试环境的稳定赢得了开发的心。并且,Node在正式环境的可用性也达到了 4个 9。
3. 及时响应、敏捷高效
毕竟我就坐在旁边,前端小伙伴吼一声就可以了。一个最近的例子,海外版开始也是计划先走 JSAPI,但是一个 cookie 的修改可能就得排期,通过 Node5分钟,需求响应及时、高效。
4. 持续优化的性能
ngw/tsw -> apisix,编解码、连接等,性能一直在变好,目前可能还不是性能最佳的,但也不会成为瓶颈,是已有替代方案中体验和性能综合最好的。
当然还有十分重要的,频道放量和业务潜力,为网关发展提供根本动力:
不需要胸怀大志,把一件件小事做好,顺势而为。
最后引用一位大佬的话:希望每个看完的小伙伴,忘掉,再重新总结出属于自己的东西。
–END–
如果您关注前端+AI 相关领域可以扫码加群交流

关于奇舞团
奇舞团是 360 集团最大的大前端团队,非常重视人才培养,有工程师、讲师、翻译官、业务接口人、团队 Leader 等多种发展方向供员工选择,并辅以提供相应的技术力、专业力、通用力、领导力等培训课程。奇舞团以开放和求贤的心态欢迎各种优秀人才关注和加入奇舞团。
