
包阅导读总结
1. 关键词:私人云、数据湖、架构设计、回归原因、实施方法
2. 总结:本文探讨私人云再度受关注,阐述其回归原因,如成本、可预测性、安全性等,介绍以现代数据湖为设计模式的私人云架构特点及优势,还列举了点亮私人云的多种实施方法。
3. 主要内容:
– 私人云受关注
– 统计显示多数企业在实施私人云
– 回归私人云的原因
– 成本节省,高达 70%
– 可预测性强
– 解决安全问题
– 拥有控制权
– 技术成熟
– 满足法规要求
– 私人云的设计模式
– 基于云操作模型,以现代数据湖为架构
– 支持多种分析,使用对象存储,性能可调
– 遵循核心云操作原则,如高性能、解耦计算和存储等
– 点亮私人云的方法
– 限时混合模式
– 完全回归
– 新建私人云
– 已有部署的回归
– 其他类别(如突发和外部表)
思维导图: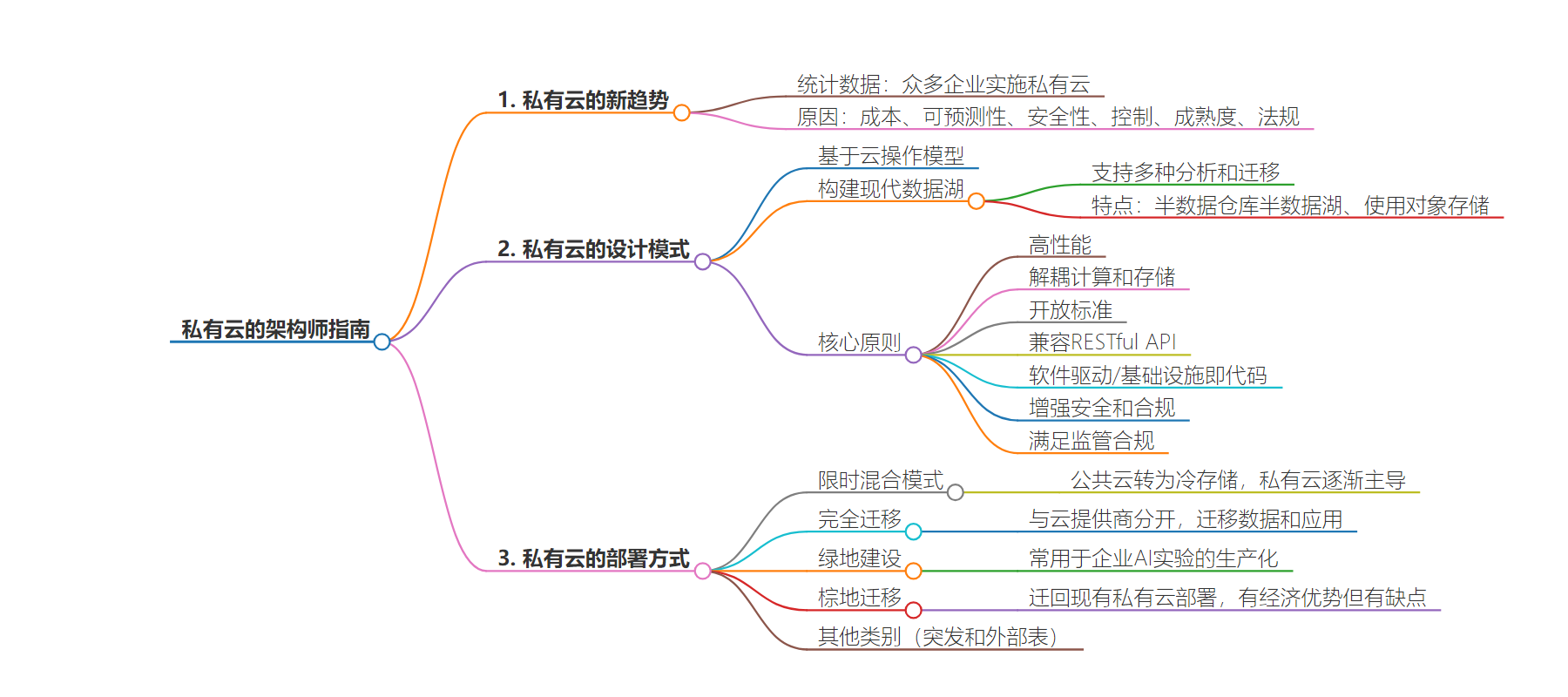
文章地址:https://thenewstack.io/the-architects-guide-to-the-new-private-cloud/
文章来源:thenewstack.io
作者:Ugur Tigli
发布时间:2024/7/9 17:13
语言:英文
总字数:2926字
预计阅读时间:12分钟
评分:85分
标签:私有云,现代数据湖,云操作模型,对象存储,回收
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
For a few years there, the term “private cloud” had a negative connotation. But as we know, technology is more a wheel than an arrow, and right on cue, the private cloud is getting a ton of attention — it’s all positive.
The statistics are clear: Forrester’s 2023 Infrastructure Cloud Survey had 79% of the 1,300 enterprise decision-makers who responded saying they are implementing private clouds. According to a Citrix report in the UK, 93% of IT leaders had been involved with a repatriation effort. The venerable IDC found that 80% of companies repatriated some or all of their data within a year of moving that data to the cloud.
So much for the cloud-industrial complex’s claims of “nothing to see here.”
The reasons are varied and we will detail them, but more importantly, what is the right architecture to repatriate to? What are the engineering first principles of the private cloud? And finally, how do I design for the data infrastructure requirements of AI?
The Why Behind Repatriation to the Private Cloud
The primary reason that companies repatriate is cost. They save up to 70% by repatriating. This has been proven publicly by companies as diverse as 37 Signals, X and Ahrefs.
Related — but not the same — is predictability. Private clouds come with less elasticity, but greater predictability. (We address some elasticity hacks below.) For most CIOs who understand their workloads, this trade-off is well worth it. For CFOs, it is an even easier choice.
Security issues come in third. This is not to say the public cloud is inherently insecure, it is not. It does say that CISOs don’t entirely trust their public cloud partners — indeed, most cloud providers retain the right to look into your buckets — on this front. The stakes only get higher in the age of AI.
On a related note, control makes every CIO’s list. Together with cost savings, predictability and security, you’re not only in full control of your AI data infrastructure, but that data is close for all your applications to consume. This enables you to host your models on AI data infrastructure where security standards can be set by you and your team to match with your unique security requirements — even physical access.
Maturity ranks, too. The modern cloud is an operating model, not a location. That model, once the exclusive purvey of the major public clouds, is now everywhere — from the edge to the core. Containerization, orchestration, microservices, software-defined infrastructure and RESTful APIs are standard operating procedures. It doesn’t matter where you run them — and if it doesn’t matter, why would you pay two to three times the cost?
Regulations also play a role, particularly as they evolve. Some architectures, some geographies even some deployment scenarios (military/intelligence) didn’t start out requiring private clouds but do now.
Again, the reasons will differ but the effect is the same. The private cloud is back in vogue. The question is: What changed in the past few years?
Private Cloud’s Design Pattern Is a Modern Data Lake
As noted above, the private cloud, like the public cloud, runs on the cloud operating model. The edge cloud runs on the cloud operating model. Colocation runs on the cloud operating model.
That operating model defines a certain architecture and time and time again, that architecture makes the modern data lake possible. There are other architectures to be sure, but using the private cloud to build your modern data lake allows organizations to pay for only what they need. When their business grows, scaling is as simple as adding more resources to a cluster. A redesign is not needed.
AI/ML is supported. Advanced analytics? Supported. Log analytics/threat analytics? Supported. HDFS replacement/migration? Supported.
A modern data lake is half data warehouse and half data lake, and it uses object storage for everything. The object storage layer is software-defined, scalable, cloud native and performant. Performance is tunable through the selection of the hardware (NVMe) and network (100 GbE or higher), which are conveniently available, off the shelf from vendors like Supermicro, Dell and HPE.
Using object storage with the data lake is standard, using it with the data warehouse is new, made possible by Open Table Formats (OTFs) like Apache Iceberg, Apache Hudi and Delta Lake. There is considerable detail on this architecture that is beyond the scope of this article. For that, I recommend reading Keith Pijanowski’s full article on the modern data lake. Here is the architecture:
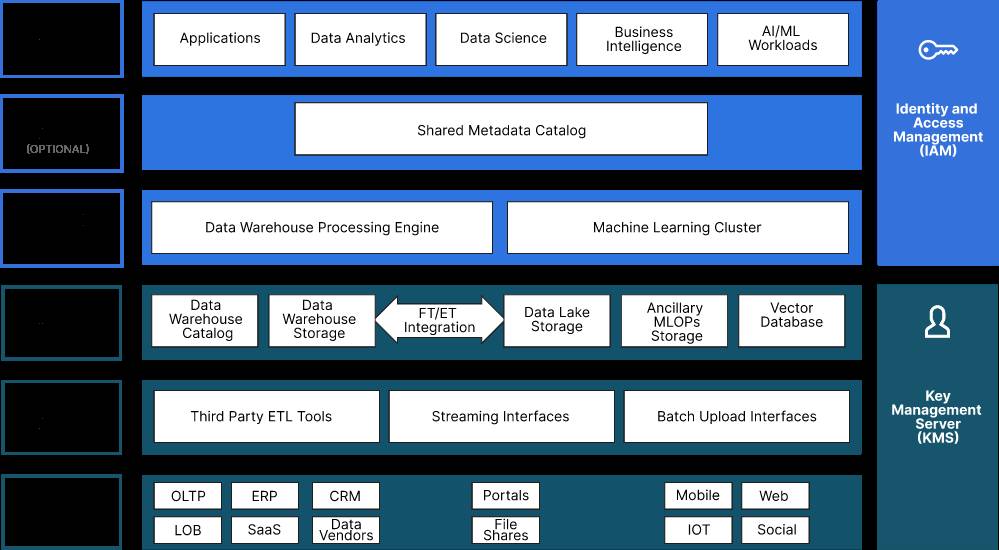
This architecture is designed to deliver the following, all of which are core cloud operating principles and, by extension, core principles of the private cloud:
- High performance: While the private cloud can be designed for capacity, the modern private cloud looks to deliver performance at scale. This architecture prioritizes tools that emphasize speed and efficiency. As Jeff Bezos says, who wants to pay more and wait longer to get it? The same principles apply here: Who wants it slower?
- Decoupled compute and storage: Unlinking these components offers increased flexibility and scalability, enabling your chosen infrastructure, services and tools to excel in their respective areas of expertise.
- Open standards: Open standards not only encourage interoperability, but they also future-proof your investments. This encompasses not just open source solutions but also open table formats as we will explore. Don’t build a private cloud with a storage appliance for these reasons (and the fact that they will never be cloud native).
- Compatibility with RESTful APIs: Interconnectivity is a must. Your tools should share a common language, with S3 serving as the lingua franca for cloud storage. For this reason, don’t build your private cloud with a POSIX-centric solution, even if it claims to support S3. Go with the real deal.
- Software-driven/Infrastructure as Code: Automate and let Kubernetes take care of orchestrating your infrastructure, enabling you to abstract away the complexities of manual management and allowing for rapid and efficient scalability.
- Enhanced security and compliance: Because private clouds provide a dedicated infrastructure, they offer greater control over data and enhanced security measures. This is particularly beneficial for industries that handle sensitive information, such as finance and health care.
- Regulatory compliance: This architecture can support regulatory compliance by providing customizable security settings and audit controls to meet specific industry standards.
Putting Your Private Cloud in Play
There are a number of approaches we have seen to lighting up the private cloud. All of them can work; it really depends on the enterprise and the use case.
- A time-limited hybrid model where some data and applications remain in the public cloud while the private cloud is hydrated.
- Complete repatriation from the public cloud into a private cloud.
- Greenfield build of a private cloud. This is particularly popular as enterprises put their AI experiments into production.
- Brownfield repatriation where you move your public cloud data and infrastructure back to an existing private cloud deployment. While economical, there are some drawbacks to this approach.
- The “other” category (bursting and external tables).
Time-Limited Hybrid Approach
The time-limited hybrid approach essentially turns the public cloud into cold storage and builds out your private cloud footprint over some period of time (months/quarters, not years). This involves buying and configuring your infrastructure and software stack on the private cloud.
Then you point your data pipeline at the private cloud, not the public cloud.
With the time-limited hybrid approach, over time the public cloud goes from cold storage to frozen while the private cloud becomes the primary and dominant storage type.
There might be some period of time where you might do both. The goal, however, is to use the public cloud as tiered cold storage and the private cloud as hot storage. Over time, the public cloud goes from cold to frozen while the private cloud becomes the primary and dominant storage type.
This is what a leading cybersecurity player did. It started by setting up a private cloud in conjunction with MinIO and Equinix, then turned the 250 tebibyte (TiB)-a-day data firehose in that direction. Given that log analytics have a high decay function in terms of operational value, it didn’t take long for the new private cloud to be the primary source of threat-hunting data. This private cloud has grown to nearly an exabyte (and will cross that threshold soon), and the decision to move these workloads (effectively the core business) onto a private cloud (with opex not capex) improves the gross margin of the business by more than 2%. As a result, this company has a valuation multiple that is the envy of its peers.
Complete Repatriation
There are times when keeping the applications and data on both the public and private cloud is not an option. In these cases, you need to break up with your cloud provider. It is hard, and even with the elimination of exit fees, they make it painful. (The fine print basically says everything has to go to get any exit fee relief.)
It is very doable; it just takes a little more planning and a little more business friction. In this case, provision your colo or private cloud and application stack. Then back up the data truck or lease the network to firehose the data out to your private cloud data infrastructure.
At this point you are free, but count on paying double for a month or two if you are the belt-and-suspenders type.
One of the leading streaming companies took this approach when it left the public cloud. It forklifted half an exabyte into the new private cloud, including all the movies, shows, documentaries, etc. The process took about three quarters. The payoff was massive, however, and the complexity was greatly reduced for the team managing the service. They also enjoyed the side benefit of a nice pop in “time to first byte” — a key metric in the space.
Greenfield Private Cloud
This is a fairly straightforward proposition and it generally involves new everything. The project is new; the data on the project will be new (or newish) or generated from some source that is coming online (like a giant fabrication plant or a new cloud video-on-demand service). Here, you size the workload — you might even test it on the public cloud — but the idea is that it will, from inception, run on the private cloud.
With the greenfield approach, everything is new. You might test it on the public cloud, but the idea is that it will, from inception, run on the private cloud not just for scale, but also security, privacy and control.
We are seeing this quite frequently with AI data infrastructure. The early experiments are occurring in the public cloud. The data is not that significant. The GPU availability is fairly good. Nonetheless, the enterprise knows that the workload needs to be on the private cloud for production — both for scale, but also for security, privacy and control.
One of the leading automotive companies in the world recently pivoted its full self-driving initiative from a rules-based system to one that’s based on the behavior of actual drivers. That behavior is “learned” from millions and millions of videos and log files that come off its vehicles. Good drivers, bad drivers, average drivers. Not just from the video, but the other elements of car telemetry such as braking, acceleration, steering torque, etc. The rules-based ML approach was petabytes in scale; the video is in exabytes of scale. The company is not sharing that data with anyone (indeed two of the public clouds have competing initiatives). That AI workload — all more than 300 servers worth — was always a private cloud initiative.
Brownfield Private Cloud
We will be honest here: We see this, but we don’t love it. This includes trying to run high-performance workloads on hard disk drives to layer MinIO on top of a SAN/NAS (storage area network/network attached storage).
It works but is rarely the optimal solution. It’s economical (you are reusing hardware); it’s low friction (no procurement); but rarely is it performant. Nonetheless, we include it here to be comprehensive.
It does raise an important point. When you design your private cloud, in any of the scenarios, plan for heterogeneity. It is a guarantee and frankly should be part of the plan. In one of the scenarios above, half the hardware is from Supermicro, the other half from Dell. As the world changes and new technology becomes available, your software shouldn’t care.
The Others
There are two other scenarios that are less frequent but should be in the consideration mix. One is the hybrid burst approach and the other is the external tables approach. Both are related to the hybrid option, but may not be time-bound.
In the hybrid burst approach, you maintain a private cloud while designing it to seamlessly expand, or “burst,” into the public cloud for added flexibility. This strategy is often adopted to leverage extra GPU capacity or to use specific cloud services. In this model, certain tasks are temporarily transferred to the public cloud for processing. Once the analysis is complete, the results are sent back to the private cloud, and the public cloud resources are then decommissioned.
In the new private cloud, rather than just scrapping hardware and buying new, we have to make the existing hardware work. Infrastructure management is a thing. It shouldn’t be scary, but it should be planned for.
We have a major financial services customer doing this with credit risk and market risk calculations. It uses the public cloud for some compute operations and combines it with a private cloud data lake that uses MinIO and Dremio.
The beauty of the cloud operating model is that the architecture should support operations in both places. It is, effectively, a two-way street. At one point, it was a one-way street, but the world has changed, and there is optionality for the enterprise.
With the external tables option, organizations can still benefit from the principles of the cloud operating model by integrating their existing cloud data warehouses, such as Snowflake and SQL Server, with a data lake built on the private cloud. This hybrid setup allows enterprises to benefit from the performance, data security and open-standard design of a modern data lake while still capitalizing on existing investments in cloud infrastructure. Every major database vendor now offers support for external tables. This functionality allows users to query data in object storage wherever it is as if it were a regular table in the database without the hassle of migration. Your data stays in the private cloud but is made available wherever it’s needed.
Final Thoughts and Counsel
We have been party to a lot of these private cloud repatriations/new builds over the years. One thing that comes as a surprise to the teams is managing hardware again. In the cloud it is transparent. DevOps and site reliability engineers only interact with infrastructure at an API level. If a VM is acting up, terminate and launch a new one in its place. Unfortunately, in the new private cloud, rather than just scrapping hardware and buying new, we have to make the existing hardware work.
Infrastructure management is a thing. It comes with the territory. It shouldn’t be scary, but it should be planned for. There needs to be a delineation of responsibilities between the software engineering/DevOps side and the data center engineer. This SME (subject matter expert) in data centers should know the ins and outs of all hardware. They will be responsible for anything and everything related to hardware including failures, replacements and any maintenance.
Software matters here. This is why MinIO built observability into its global console. In the world of the private cloud, you should be running smart software and dumb hardware. But that software has to carry the operational burden of this economic bounty. The hardware guys simply couldn’t build the observability layer, MinIO had to do it.
If you are an organization that deploys once a week, that means each deployment is probably a spectacle. This is because with infrequent deployments it’s difficult to predict and fix bugs. When deployments do not go as planned, it’s all hands on deck. Generally, the flow would look as follows:
- Design to deploy your application in a distributed setup.
- Test it in your local environment.
- Further validate in a Dev and Stage environment.
- Add monitoring, metrics, tracing and altering.
- Deploy on-prem, hybrid and cloud environments.
When these CI/CD principles are applied in practice, one strong data center engineer working closely with another strong DevOps/SRE engineer can easily manage over 5,000 nodes in a private cloud or colo facility. We have customers that do exactly this. Once you follow the CI/CD baseline principles almost everything can and should be automated and the data center and DevOps engineers will focus on only those tasks that cannot be automated.
Lastly, in case you missed it, colos are synonymous with our definition of the private cloud. Colocation provides a middle ground between fully on-premises infrastructure and the public cloud, offering the benefits of both worlds. With access to top-tier networking and proximity to the public cloud providers, colos facilitate low-latency connections and hybrid cloud setups, enabling efficient data transfer and processing. This flexibility and potential for successful hybrid cloud deployments is crucial for businesses aiming to optimize their operations and maintain a competitive edge. To learn more about how this works, check out our MinIO and Equinix page.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.