
包阅导读总结
1. 关键词:Roaring BitMap、Bitmap、存储方式、container类型、Java API
2. 总结:
本文介绍了Bitmap及Roaring BitMap的原理与使用,包括Roaring BitMap的存储方式、三种container类型、Java中的相关API及应用场景,对比了Bitmap和Roaring BitMap的存储情况,指出Roaring BitMap压缩性能好,在大数据处理中效率高。
3. 主要内容:
– Bitmap
– 基本思想:用bit位标记元素对应的value
– 优点:占用内存少、运算效率高
– 缺点:无法存储重复数据、存储稀疏数据浪费空间
– Roaring BitMap
– 存储方式:将32位int型整数分为高16位和低16位处理
– Container类型
– ArrayContainer:适合稀疏数据,二分查找,最大数据量4096
– BitmapContainer:适合稠密数据,位运算,时间复杂度O(1)
– RunContainer:适合连续数据,行程长度编码压缩,二分查找
– 相关源码:Java中增加元素的源码,不同Container的添加实现
– 存储情况对比:压缩性能好,占用内存少
– Java中相关API使用
– 提供交并补差集等操作
– 定义序列化规则,可进行序列化和反序列化
– 业务实际场景应用
– 构建大数据标签,进行人群标签交并补集运算,提高查询效率
思维导图: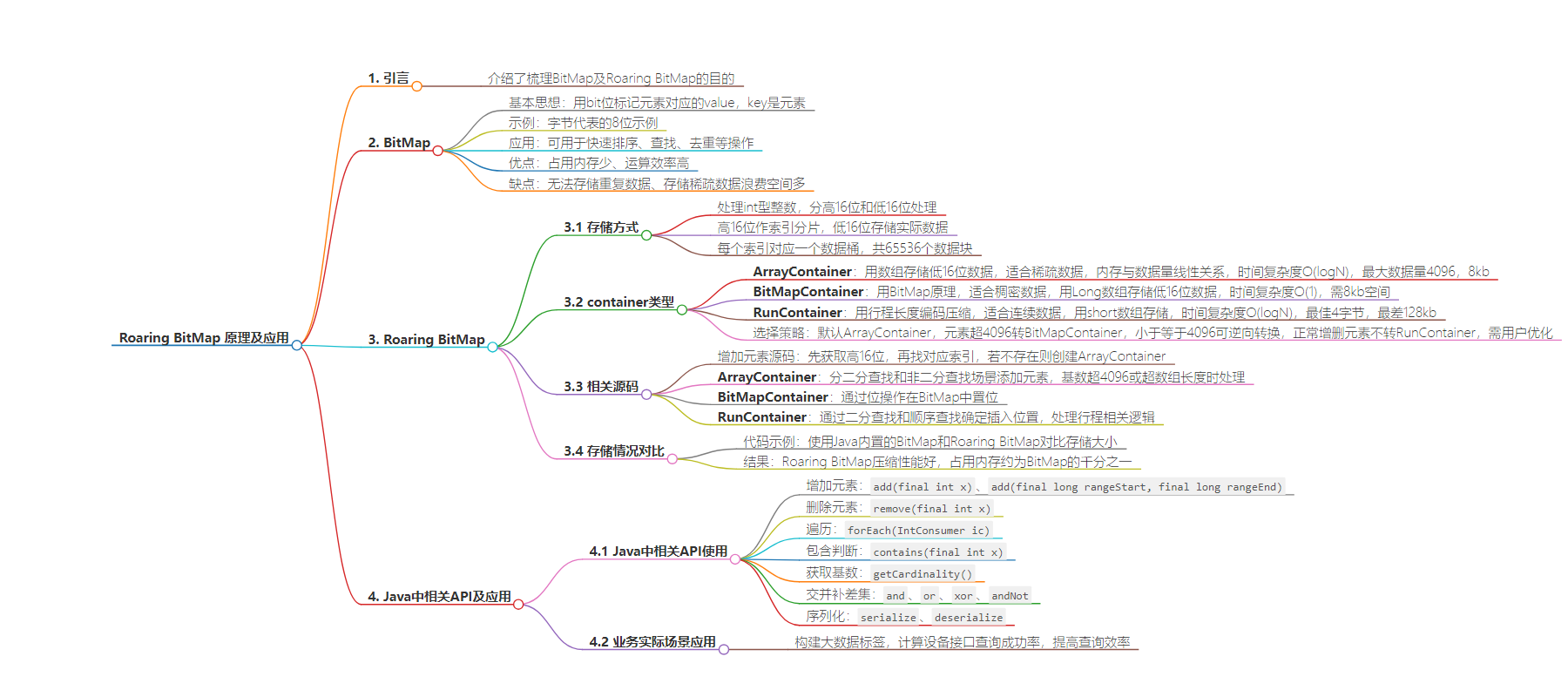
文章地址:https://mp.weixin.qq.com/s/aNHXKHNViWchWKcyRxjOIg
文章来源:mp.weixin.qq.com
作者:Zheng??Rui
发布时间:2024/6/19 10:11
语言:中文
总字数:5755字
预计阅读时间:24分钟
评分:86分
标签:Roaring BitMap,数据处理,位图
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
作者:来自 vivo 互联网服务器团队- Zheng Rui
本文结合个人理解梳理了BitMap及Roaring BitMap的原理及使用,分别主要介绍了Roaring BitMap的存储方式及三种container类型及Java中Roaring BitMap相关API使用。
在进行大数据开发时,我们可以使用布隆过滤器和Redis中的HyperLogLog来进行大数据的判重和数量统计,虽然这两种方法节省内存空间并且效率很高,但是也存在一些误差。如果需要100%准确的话,我们可以使用BitMap来存储数据。
BitMap 位图索引数据结构被广泛地应用于数据存储和数据搜索中,但是对于存储较为分散的数据时,BitMap会占用比较大的内存空间,因此我们更偏向于使用 Roaring BitMap稀疏位图索引进行存储。同时,Roaring BitMap广泛应用于数据库存储和大数据引擎中,例如Hive,Spark,Doris,Kylin等。
下文将分别介绍 BitMap 和 Roaring BitMap 的原理及其相关应用。
BitMap的基本思想就是用bit位来标记某个元素对应的value,而key就是这个元素。
例如,在下图中,是一个字节代表的8位,下标为1,2,4,6的bit位的值为1,则该字节表示{1,2,4,6}这几个数。

在Java中,1个int占用4个字节,如果用int来存储这四个数字的话,那么将需要4 * 4 = 16字节。
BitMap可以用于快速排序,查找,及去重等操作。优点是占用内存少(相较于数组)和运算效率高,但是缺点也非常明显,无法存储重复的数据,并且在存储较为稀疏的数据时,浪费存储空间较多。
3.1 存储方式
为了解决BitMap存储较为稀疏数据时,浪费存储空间较多的问题,我们引入了稀疏位图索引Roaring BitMap。Roaring BitMap 有较高的计算性能及压缩效率。下面简单介绍一下Roaring BitMap的基本原理。
Roaring BitMap处理int型整数,将32位的int型整数分为高16位和低16位分别进行处理,高16位作为索引分片,而低16位用于存储实际数据。其中每个索引对应一个数据桶(bucket),那么一共可以包含2^16 = 65536个数据块。每个数据桶使用container容器来存储低16位的部分,每个数据桶最多存储2^16 = 65536个数据。
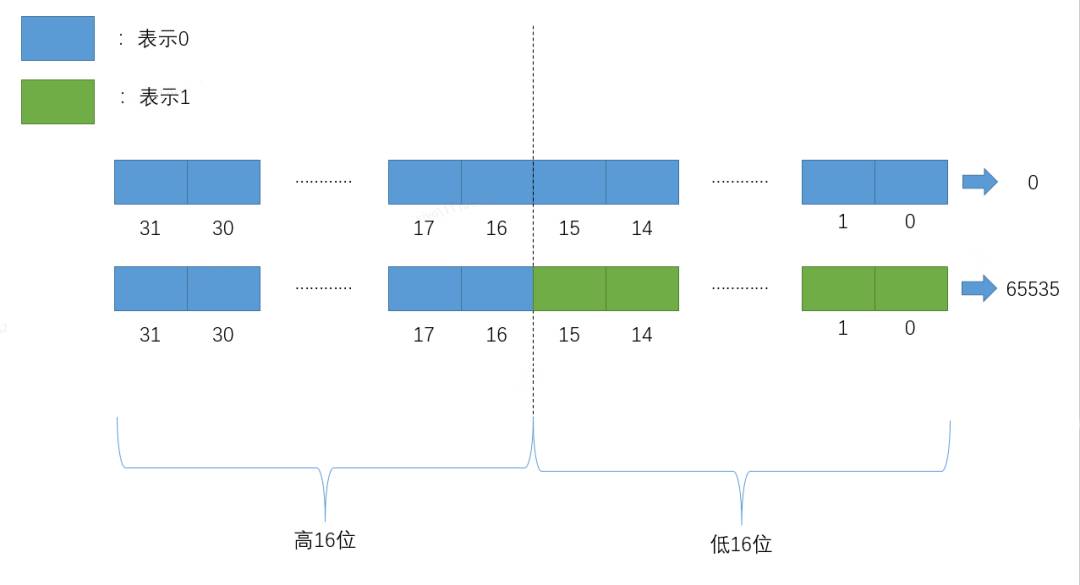
如上图所示,高16位作为索引查找具体的数据块,当前索引值为0,低16位作为value进行存储。
Roaring BitMap在进行数据存储时,会先根据高16位找到对应的索引key(二分查找),低16位作为key对应的value,先通过key检查对应的container容器,如果发现container不存在的话,就先创建一个key和对应的container,否则直接将低16位存储到对应的container中。
Roaring BitMap的精妙之处在于使用不同类型的container,接下来将对其进行介绍。
3.2 container类型
1.ArrayContainer
顾名思义,ArrayContainer直接采用数组来存储低16位数据,没有采用任何数据压缩算法,适合存储比较稀疏的数据,在Java中,使用short数组来存储,并且占用的内存空间大小和数据量成线性关系。由于short为2字节,因此n个数据为2n字节。ArrayContainer采用二分查找定位有序数组中的元素,因此时间复杂度为O(logN)。ArrayContainer的最大数据量为4096, 4096 * 2b = 8kb。
2.BitMapContainer
BitMapContainer采用BitMap的原理,就是一个没有经过压缩处理的普通BitMap,适合存储比较稠密的数据,在Java中使用Long数组存储低16位数据,每一个bit位表示一个数字。由于每个container需要存储2^16 = 65536个数据,如果通过BitMap进行存储的话,需要使用2^16个bit进行存储,即8kb的数据空间。
可以从下图中看出ArrayContainer和BitMapContainer的内存空间使用关系,当数据量小于4096时,使用ArrayContainer比较合适,当数据量大于等于4096时,使用BitMapContainer更佳。
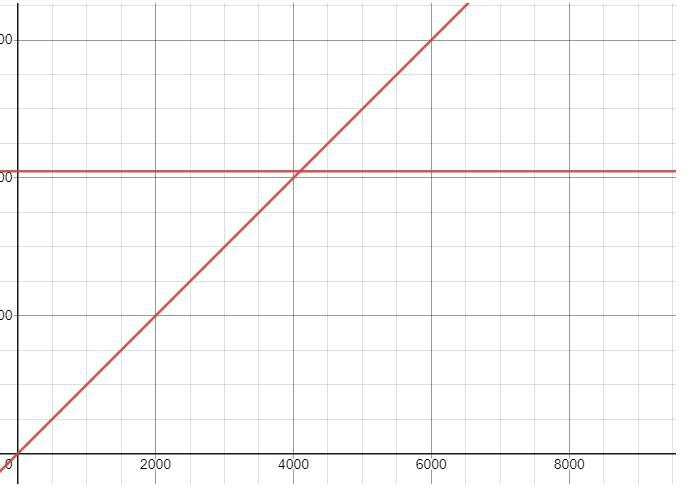
因为BitMap直接使用位运算,所以BitMapContainer的时间复杂度为O(1)。
3.RunContainer
RunContainer采用Run-Length Encoding 行程长度编码进行压缩,适合存储大量连续数据。Java中使用short数组进行存储。连续bit位程度越高的话越节省存储空间,最佳场景下(65536个数据全为1)只需要存储4字节。最差场景为所有数据都不连续,所有存储数据位置为奇数或者偶数,这种场景需要存储128kb。由于采用二分查找算法定位元素,因此时间复杂度为O(logN)。
行程长度编码即的原理是对连续出现的数字进行压缩,只记录初始数字和后续连续数量。
例如:[1,2,3,4,5,8,9,10]使用编码后的数据为[1,4,8,2]。
Java 里可以使用runOptinize()方法来对比RunContainer和其他两个Container存储空间大小,如果使用RunContainer存储空间更佳则会进行转化。
根据上面三个Container类型我们可以得知如何进行选择:
-
Container默认使用ArrayContainer,当元素数量超过4096时,会由ArrayContainer转换BitMapContainer。
-
当元素数量小于等于4096时,BitMapContainer会逆向转换回ArrayContainer。
-
正常增删元素不会使Container直接变成RunContainer,而需要用户进行优化方法调用才会转换为最节省空间的Container。
3.3 Roaring BitMap 相关源码
介绍完Roaring BitMap的三种container类型以后,让我们了解一下,Roaring BitMap的相关源码。这里介绍一下Java中增加元素的源码实现。
public void add(final int x) {final short hb = Util.highbits(x);final int i = highLowContainer.getIndex(hb);if (i >= 0) {highLowContainer.setContainerAtIndex(i,highLowContainer.getContainerAtIndex(i).add(Util.lowbits(x)));} else {final ArrayContainer newac = new ArrayContainer();highLowContainer.insertNewKeyValueAt(-i - 1, hb, newac.add(Util.lowbits(x)));}}
Roaring BitMap首先获取添加元素的高16位,然后再调用getIndex获取高16位对应的索引,如果索引大于0,表示已经创建该索引对应的container,故直接添加相应的元素低16位即可;否则的话,说明该索引对应的container还没有被创建,先创建对应的ArrayContainer,再进行元素添加。值得一提的是,在getIndex方法中,使用了二分查找来获取索引值,所以时间复杂度为O(logn)。
protected int getIndex(short x) {if ((size == 0) || (keys[size - 1] == x)) {return size - 1;}return this.binarySearch(0, size, x);}
对于元素添加,三种Container提供了不同的实现方式,下面将分别介绍。
1.ArrayContainer
if (cardinality == 0 || (cardinality > 0&& toIntUnsigned(x) > toIntUnsigned(content[cardinality - 1]))) {if (cardinality >= DEFAULT_MAX_SIZE) {return toBitMapContainer().add(x);}if (cardinality >= this.content.length) {increaseCapacity();}content[cardinality++] = x;} else {int loc = Util.unsignedBinarySearch(content, 0, cardinality, x);if (loc < 0) {if (cardinality >= DEFAULT_MAX_SIZE) {return toBitMapContainer().add(x);}if (cardinality >= this.content.length) {increaseCapacity();}System.arraycopy(content, -loc - 1, content, -loc, cardinality + loc + 1);content[-loc - 1] = x;++cardinality;}}return this;}
ArrayContainer把添加元素分成两种场景,一种走二分查找,另外一种不走二分查找。
当基数为0或者值大于container中的最大值,可以直接添加,因为content数组是有序的,最后一个是最大值。
当基数大于等于默认最大值4096时,ArrayContainer将转换为BitMapContainer。如果基数大于content的数组长度的话,需要将content进行扩容。最后进行赋值即可。
先通过二分查找找到对应的插入位置,如果返回loc大于等于0,说明存在,直接返回即可,如果小于0才进行后续插入。后续操作同上,当基数大于等于默认最大值4096时,ArrayContainer将转换为BitMapContainer。如果基数大于content的数组长度的话,需要将content进行扩容。最后通过拷贝数组将元素插入到content数组中。
2.BitMapContainer
public Container add(final short i) {final int x = Util.toIntUnsigned(i);final long previous = BitMap[x / 64];long newval = previous | (1L << x); BitMap[x / 64] = newval;if (USE_BRANCHLESS) {cardinality += (previous ^ newval) >>> x;} else if (previous != newval) {++cardinality;}return this;}
BitMap数组为BitMapContainer的存储容器存放数据的内容,数据类型为long,在这里我们只需要找到x在BitMap中的位置,并且把相应的bit位置1即可。x/64就是找到对应long的旧值,1L<<x 就是把对应的bit位置为1,再跟旧值进行或操作,就可以得到新值,再将这个新值存回到bitmap数组即可。<=”” span=””>
3. RunContainer
public Container add(short k) {int index = unsignedInterleavedBinarySearch(valueslength, 0, nbrruns, k);if (index >= 0) {return this;}index = -index - 2;if (index >= 0) {int offset = toIntUnsigned(k) - toIntUnsigned(getValue(index));int le = toIntUnsigned(getLength(index));if (offset <= le) {return this;}if (offset == le + 1) {if (index + 1 < nbrruns) {if (toIntUnsigned(getValue(index + 1)) == toIntUnsigned(k) + 1) {setLength(index,(short) (getValue(index + 1) + getLength(index + 1) - getValue(index)));recoverRoomAtIndex(index + 1);return this;}}incrementLength(index);return this;}if (index + 1 < nbrruns) {if (toIntUnsigned(getValue(index + 1)) == toIntUnsigned(k) + 1) {setValue(index + 1, k);setLength(index + 1, (short) (getLength(index + 1) + 1));return this;}}}if (index == -1) {if (0 < nbrruns) {if (getValue(0) == k + 1) {incrementLength(0);decrementValue(0);return this;}}}makeRoomAtIndex(index + 1);setValue(index + 1, k);setLength(index + 1, (short) 0);return this;}
RunContainer中的两个数据结构,nbrruns表示有多少段行程,数据类型为int,valueslength数组表示所有的行程,数据类型为short。
-
首先,使用二分查找+顺序查找在valueslength数组中查找元素k的插入位置index。如果查找到的index结果大于等于0那就说明k是某个行程起始值,已经存在,直接返回。
-
-index-2是为了指向前一个行程起始值的索引。
-
接下来是一些偏移量和索引值的判断,主要是为了确认k是否落在上一个行程里,或者外面,如果落在上一个行程里,则直接返回,否则需要新建一个行程或者就近与一个行程混合并且将行程长度加1。
3.4 BitMap 和 Roaring BitMap 存储情况对比
public static void count(Integer inputSize) { RoaringBitMap BitMap = new RoaringBitMap(); BitMap.add(0L, inputSize);int cardinality = BitMap.getCardinality();int compressSizeIntBytes = BitMap.getSizeInBytes();int uncompressSizeIntBytes = BitMap.getSizeInBytes();System.out.println("Roaring BitMap个数:" + cardinality);System.out.println("最好情况,BitMap压缩大小:" + compressSizeIntBytes / 1024 + "KB");System.out.println("最坏情况,BitMap不压缩大小:" + uncompressSizeIntBytes / 1024 / 1024 + "MB");BitSet bitSet = new BitSet();for (int i = 0; i < inputSize; i++) {bitSet.set(i);}int size = bitSet.size();System.out.println("BitMap个数:" + bitSet.length());System.out.println("BitMap大小:" + size / 8 / 1024 / 1024 + "MB");}
上述代码使用了Java内置的BitMap(BitSet) 和 Roaring BitMap进行存储大小对比,输出结果如下所示。
可以发现,Roaring BitMap的压缩性能效果非常好,同等情况下,是BitMap占用内存的近一千分之一。在退化成BitMapContainer/arrayContainer之后也仍然比使用基本的BitMap存储效果好一些。
4.1 Java 中相关 API 使用
在Java中,Roaring BitMap提供了交并补差集等操作,如下代码所示,列举了Java中roaing BitMap的相关API使用方式。
public void add(final int x)public void add(final long rangeStart, final long rangeEnd)public void remove(final int x)public void forEach(IntConsumer ic)public boolean contains(final int x)public int getCardinality()public void and(final RoaringBitMap x2)public static RoaringBitMap and(final RoaringBitMap x1, final RoaringBitMap x2)public void or(final RoaringBitMap x2)public static RoaringBitMap or(final RoaringBitMap x1, final RoaringBitMap x2)public void xor(final RoaringBitMap x2)public static RoaringBitMap xor(final RoaringBitMap x1, final RoaringBitMap x2)public void andNot(final RoaringBitMap x2)public static RoaringBitMap andNot(final RoaringBitMap x1, final RoaringBitMap x2)public void serialize(DataOutput out) throws IOExceptionpublic void serialize(ByteBuffer buffer)public void deserialize(DataInput in) throws IOExceptionpublic void deserialize(ByteBuffer bbf) throws IOException
对于序列化来说,Roaring BitMap官方定义了一套序列化规则,用来保证不同语言实现的兼容性。
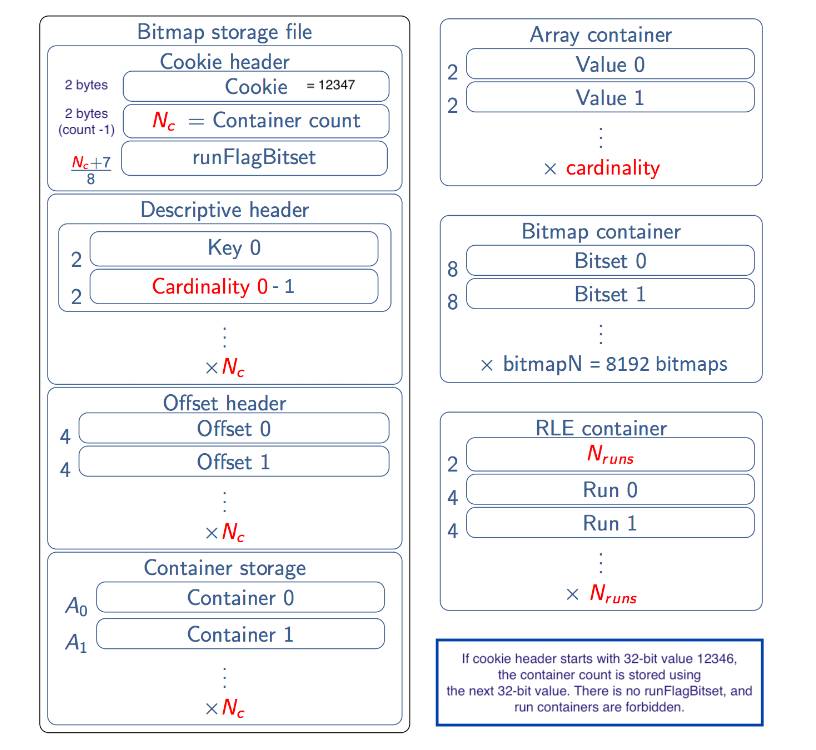
Java中可以使用serialize方法进行序列化,deserialize方法进行反序列化。
4.2 业务实际场景应用
Roaring BitMap可以用来构建大数据标签,针对类型特征来创建对应的标签。
在我们的业务场景中,有很多需要基于人群标签进行交并补集运算的场景,下面以一个场景为例,我们需要计算每天某个设备接口 在设备标签A上的查询成功率,因为设备标签A中的设备不是所有都活跃在网的,所以我们需要将设备标签A与每日日活人群标签取交集,得到的交集大小才能用作成功率计算的分母,另外拿查询成功的标签人群做分子来进行计算即可,查询时长耗时为1s。
假如没有使用标签保存集合之前,我们需要在hive表中查询出同时满足当天在网的活跃用户和设备A的用户数量,查询时长耗时在几分钟以上。两种方式相比之下,使用Roaring BitMap查询的效率更高。

本文结合个人理解梳理了BitMap及Roaring BitMap的原理及使用,分别主要介绍了Roaring BitMap的存储方式及三种container类型及Java中Roaring BitMap相关API使用,如有不足和优化建议,也欢迎大家批评指正。
参考资料: