
包阅导读总结
1.
关键词:PySpark、大数据、Python、数据处理、Apache Spark
2.
总结:本文介绍了 PySpark 这一用于大数据处理的工具,包括其定义、优势(速度快、易用、可扩展、集成性好),还讲解了如何开始使用 PySpark 以及通过简单示例展示了数据处理操作,最后总结其对大数据工作者的价值。
3.
主要内容:
– PySpark 简介
– 是 Python 版的 Apache Spark API,用于处理大数据
– PySpark 的优势
– 处理数据速度快
– 易于使用,对熟悉 Python 的人友好
– 具有良好的可扩展性
– 与其他大数据工具集成性好
– 如何使用 PySpark
– 安装 Python、Java 和 Apache Spark
– 使用 pip 安装 PySpark
– 创建 Spark 会话,加载数据到 DataFrame 进行操作
– 举例展示数据过滤、分组和聚合等操作
– 结论
– PySpark 是处理大数据的出色工具,值得尝试学习
思维导图: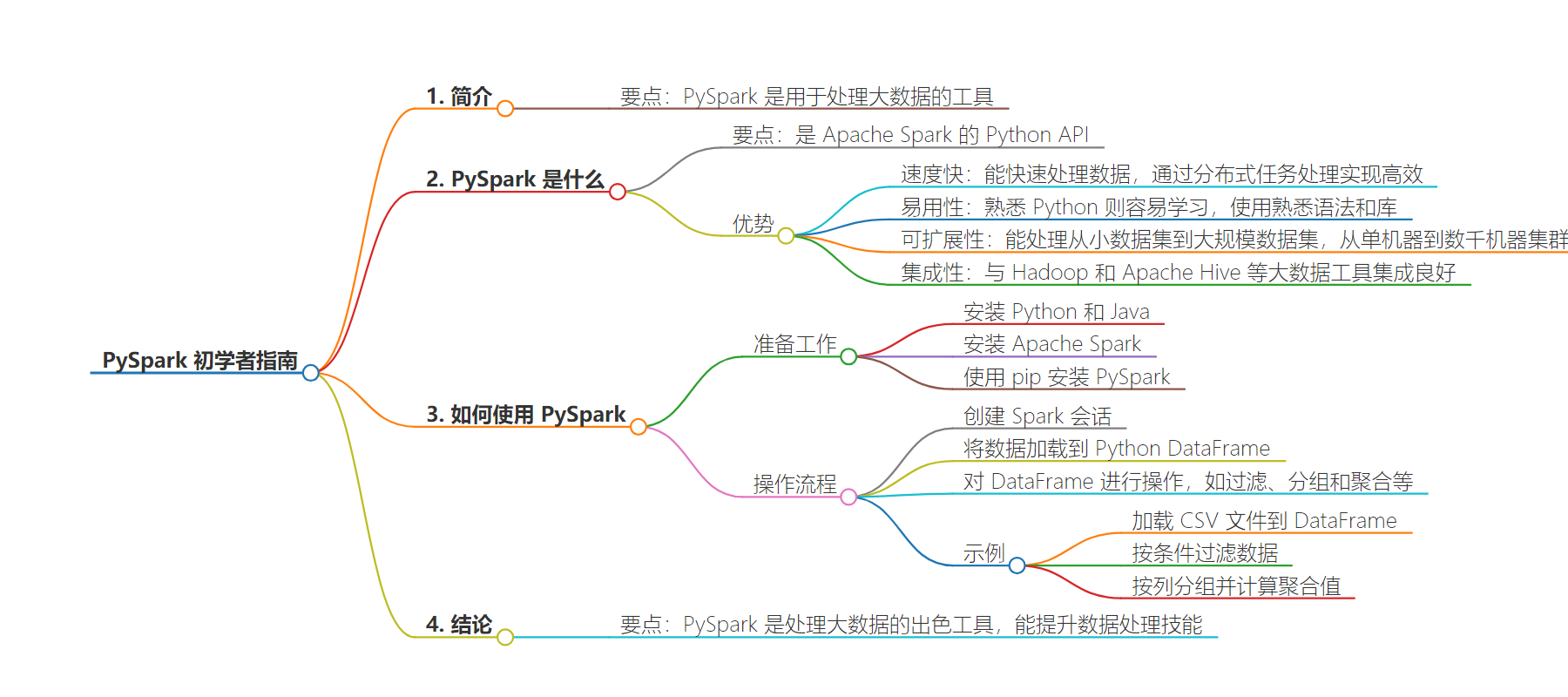
文章地址:https://www.freecodecamp.org/news/pyspark-for-beginners/
文章来源:freecodecamp.org
作者:Manish Shivanandhan
发布时间:2024/6/26 8:25
语言:英文
总字数:593字
预计阅读时间:3分钟
评分:87分
标签:Python,大数据,Apache Spark
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
If you’re diving into the world of big data, you’ve probably come across the term PySpark.
PySpark is a tool that makes managing and analyzing large datasets easier. In this article, we will see the basics of PySpark, its benefits, and how you can get started with it.
What is Pyspark?
PySpark is the Python API for Apache Spark, a big data processing framework.
Spark is designed to handle large-scale data processing and machine learning tasks. With PySpark, you can write Spark applications using Python.
One of the main reasons to use PySpark is its speed. PySpark can process data much faster than traditional data processing frameworks.
This is because Pyspark distributes tasks across multiple machines, making it incredibly efficient.
Another advantage is ease of use. If you’re familiar with Python, you’ll find PySpark easy to learn. It uses familiar Python syntax and libraries, so you can get up to speed quickly.
Scalability is another key benefit of PySpark. Whether you’re working with a small dataset or a massive one, PySpark can handle it all.
Pyspark scales from a single machine to a cluster of thousands of machines. This means you can start small and expand as your data grows.
PySpark also integrates well with other big data tools like Hadoop and Apache Hive. This makes it a versatile choice for data engineering tasks.
How to Work with Pyspark
Now, let’s talk about getting started with PySpark.
Before you begin, you should have Python and Java installed on your system. You’ll also need to install Apache Spark.You can download it from the official Spark website.
Once you have these prerequisites in place, you can install PySpark using pip, Python’s package installer.
pip install pysparkAfter installing PySpark, you can start using it to process data.
You can create a Spark session, which is the entry point for any Spark application. From there, you can load your data into a Python DataFrame.
A DataFrame is a distributed collection of data organized into named columns. DataFrames are similar to tables in a database and make it easy to manipulate your data.
You can perform various operations on DataFrames, such as filtering, grouping, and aggregating data. PySpark provides a wide range of functions to help you with these tasks.
To give you a taste of PySpark, let’s look at a simple example.
Suppose you have a CSV file with some data. You can load this data into a DataFrame and perform basic operations on it.
First, create a Spark session:
from pyspark.sql import SparkSessionspark = SparkSession.builder.appName(“example”).getOrCreate()Next, load your CSV file into a DataFrame:
df = spark.read.csv(“path/to/your/file.csv”, header=True, inferSchema=True)You can now perform operations on this DataFrame. For instance, to filter the data where a specific column has a certain value, you can use:
filtered_df = df.filter(df[“column_name”] == “value”)You can also group the data by a column and calculate aggregates, such as the average value of another column:
grouped_df = df.groupBy(“column_name”).agg({“another_column”: “avg”})These are just a few examples of what you can do with PySpark. The library is very powerful and offers many functions to help you process and analyze your data.
Conclusion
In conclusion, PySpark is a fantastic tool for anyone working with big data. It’s fast, easy to use, scalable, and integrates well with other big data tools.
By learning PySpark, you can unlock the full potential of Apache Spark and take your data processing skills to the next level.
So, go ahead and give PySpark a try. You’ll be amazed at how much it can do.
Hope you enjoyed this article. For more AI articles, visit turingtalks.ai.