
包阅导读总结
1. 关键词:IR-QLoRA、大语言模型、信息论、模型量化、字节跳动
2. 总结:豆包大模型团队实习生提出 IR-QLoRA 方法,将信息论引入大模型量化,该成果中选 ICML 2024 Oral,显著提升模型准确性,团队合作及支持力度大,字节跳动在 ICML 有多篇中选论文及现场展示。
3.
– 成果介绍
– 提出新颖的 IR-QLoRA 方法,通过信息保留推动 LoRA 微调量化下大语言模型保持高准确性。
– 引入信息论视角,审视和衡量大模型量化。
– 在低比特宽度下显著提升 LLaMA 和 LLaMA2 系列模型准确性。
– 研究背景与过程
– 2023 年立项,旨在解决大模型时代降低部署成本问题。
– 提出信息校准量化技术(ICQ)和信息弹性连接(IEC)。
– 实验结果与优势
– 对比此前成果,精度提升,额外开销小。
– 可与各种框架兼容,适用多种场景。
– 团队合作与氛围
– 字节跳动与北航校企合作。
– 团队支持力度大,氛围自由开放。
– 未来展望与相关成果
– 探讨未来发展,需高效架构与部署方式。
– 字节跳动在 ICML 2024 还有多篇中选论文及现场展示。
思维导图: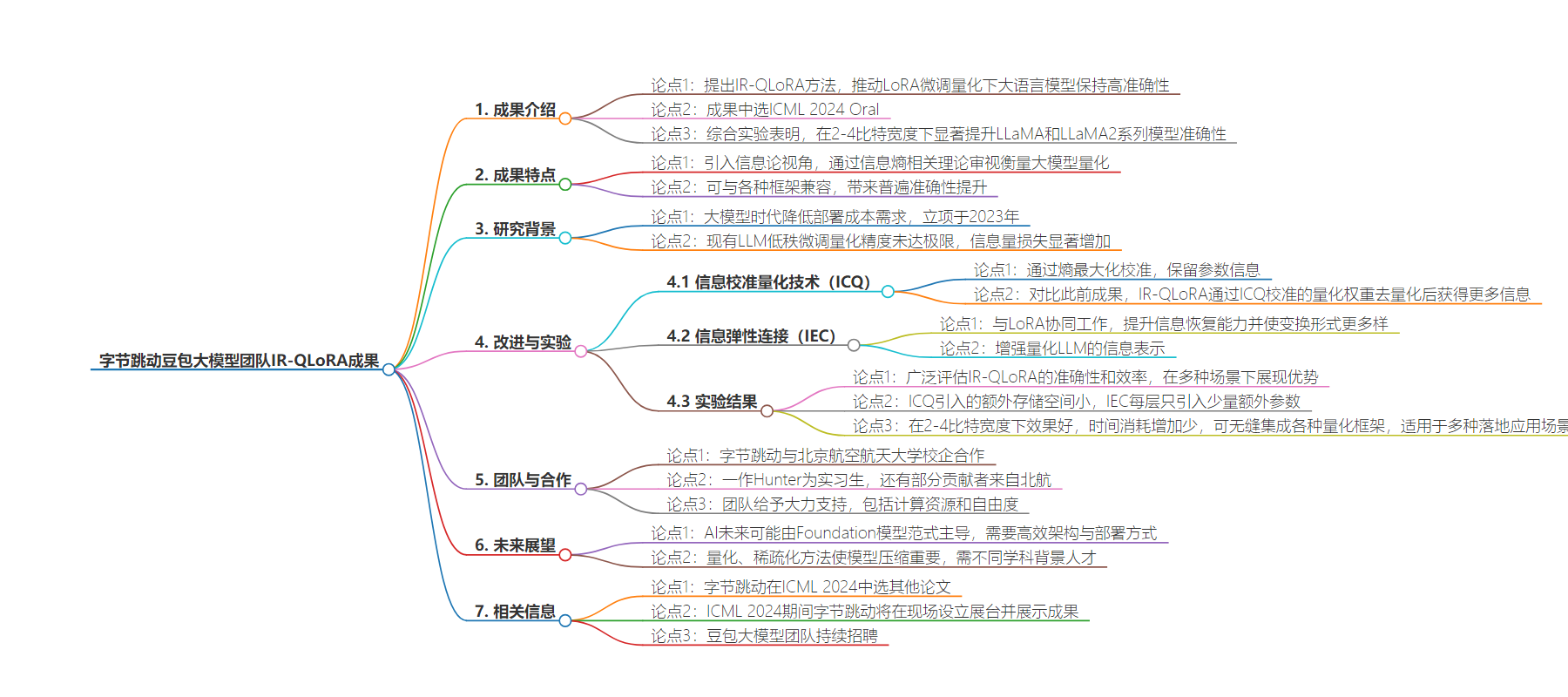
文章地址:https://mp.weixin.qq.com/s/E78-wuBuPP9NXh3pjxeZVQ
文章来源:mp.weixin.qq.com
作者:豆包大模型团队
发布时间:2024/7/22 5:45
语言:中文
总字数:3492字
预计阅读时间:14分钟
评分:86分
标签:大模型,模型压缩,性能提升,LoRA 微调量化,信息论
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
本文提出一种新颖的 IR-QLoRA 方法,通过信息保留,推动 LoRA 微调量化下大语言模型保持高度准确性。该成果第一次明确引入信息论视角,透过信息熵相关理论,对大模型量化进行审视与衡量,目前已中选 ICML 2024Oral 。
成果一作为豆包大模型团队语音组实习生,也是字节跳动奖学金计划入选者之一。北京航空航天大学复杂关键软件环境全国重点实验室的老师同学,同样对成果作出贡献。
机器学习界三大顶会之一的 ICML 于 7 月 21 日- 7 月 27 日在维也纳举办,在中选成果中,字节跳动豆包大模型团队语音组校企合作论文 Accurate LoRA-Finetuning Quantization of LLMs via Information Retention 入选 Oral 。
本次 ICML 共接收论文 9653 篇,中选 2609 篇, Oral 仅为 144 篇,占总投稿量 1.5% 。该入选论文提出一种名为 IR-QLoRA 的新颖结构,依靠信息保留方法,推动 LoRA 微调方法下的大模型量化技术达到高精确度。
综合实验表明, IR-QLoRA 可以在 2-4 比特宽度下,显著提升 LLaMA 和 LLaMA2 系列模型的准确性。相比此前 SOTA 方法,该成果面向 4 比特 LLaMA-7B 模型在 MMLU (大规模多任务语言理解) 指标上实现 1.4% 提升,相应额外花费推理时间仅为 0.31% 。在几乎不增加计算量情况下,较大幅度改善了推理效果。
另一方面, IR-QLoRA 可与各种框架兼容(比如:NormalFloat 和 Integer Quantization ),并能带来普遍的准确性提升。
关于此番入选原因,主要参与者 Hunter 认为,该成果第一次明确引入信息论视角,透过信息熵相关理论,对大模型量化进行了审视与衡量。研究深度上,之前许多压缩方案相对更为工程化, IR-QLoRA 的理论基础和分析更扎实,且团队基于成果对不同结构模型都进行了分析,研究工作也较完整。
该成果由字节跳动与北京航空航天大学通过校企合作形式,共同产出。论文一作 Hunter 为豆包大模型团队语音组实习生,还有部分贡献者来自北航复杂关键软件环境全国重点实验室,此前,他们也多次深度参与字节跳动机器学习项目研究。
Accurate LoRA-Finetuning Quantization of LLMs via Information Retention
链接:https://arxiv.org/abs/2402.05445
1. 大模型时代如何降低部署成本?
IR-QLoRA 的立项,是在 2023 年。彼时 LLM 兴起,字节跳动相关同学也保持了密切关注,尤其针对落地问题,大家希望能有更好的模型压缩方案,能使得模型稀疏化、节约内存和访存消耗,降低部署门槛。
带着上述问题,团队与以量化相关课题见长的北航团队合作,共同开启了此次研究工作。
LoRA(Low-Rank Adaptation of Large Language Models)作为一种主流方法,自提出以来被不断研究并尝试应用于广泛领域。然而,此前各种方法会导致量化的 LLM 出现严重退化,甚至无法从 LoRA 微调中获益。
团队认为,现有的 LLM 低秩微调量化在精度上远未达到极限,量化过程中的信息量损失显著增加。为此,团队做了如下方面工作。
-
首先,提出一种信息校准量化技术( ICQ ),通过熵最大化校准,使得量化过程中能保留参数信息; -
然后,依靠信息弹性连接( IEC )与 LoRA 协同工作,提升信息恢复能力并使得 LoRA 变换形式更为多样;
2. 具体改进与实验结果
3.“没团队帮忙,差点就赶不上投稿了”
Outlier-aware Slicing for Post-Training Quantization in Vision Transformer
video-SALMONN: Speech-Enhanced Audio-Visual Large Language Models
Two Stones Hit One Bird: Bilevel Positional Encoding for Better Length Extrapolation
Self-Infilling Code Generation
Diffusion Language Models Are Versatile Protein Learners
Protein Conformation Generation via Force-Guided SE(3) Diffusion Models
Boximator: Generating Rich and Controllable Motions for Video Synthesis
MagicPose: Realistic Human Pose and Facial Expression Retargeting with Identity-aware Diffusion
GroupCover: A Secure, Efficient and Scalable Inference Framework for On-device Model Protection based on TEES
InfiAgent-DABench: Evaluating Agents on Data Analysis Tasks
Training Large Language Models for Reasoning through Reverse Curriculum Reinforcement Learning
Bridging Model Heterogeneity in Federated Learning via Uncertainty-based Asymmetrical Reciprocity Learning


点击“阅读原文”,了解团队招聘信息 !