
包阅导读总结
1.
关键词:DuckDB、Python、数据分析、单服务器、开源
2.
总结:DuckDB 是开源的内进程分析数据库系统,能在单服务器上高效处理大规模数据,结合 Python,无需分布式系统,性能出色,挑战了大数据解决方案的必要性。
3.
主要内容:
– DuckDB 介绍
– 是开源内进程分析数据库系统,2018 年创建
– 旨在单服务器运行,消除分布式系统的复杂
– 由 Hannes Mühleisen 和 Mark Raasveldt 创立,有商业支持
– 以 C++编写,结合 SQL 与 Python
– 性能表现
– 2021 年测试处理速度表现出色
– 2023 年优化后进一步提升
– 能处理大规模数据,挑战分布式系统适用场景
– 特点与优势
– 与 Python 结合,支持多种语言和文件格式
– 可直接在应用进程中执行查询
– 利用服务器资源,不受内存限制,直接读写数据
– 适合数据科学社区,能嵌入数据操作到代码
– 对大数据的影响
– 质疑大数据解决方案的必要性,多数应用无需处理海量数据
思维导图: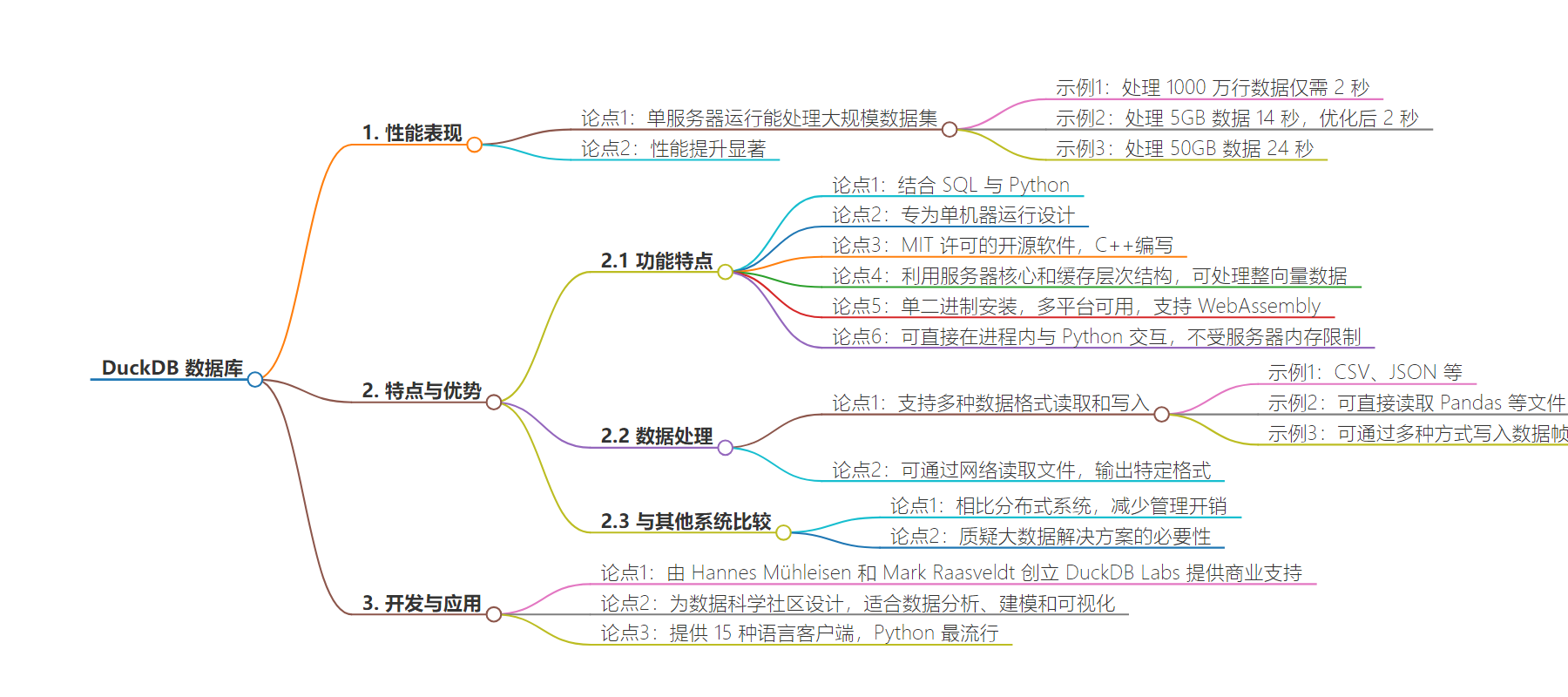
文章地址:https://thenewstack.io/duckdb-in-process-python-analytics-for-not-quite-big-data/
文章来源:thenewstack.io
作者:Joab Jackson
发布时间:2024/6/23 21:49
语言:英文
总字数:1153字
预计阅读时间:5分钟
评分:87分
标签:DuckDB,Python,数据分析,数据库,进程内
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
PITTSBURGH — You don’t always need a cluster to analyze even a very large data set. There is a lot you can pack into a single server running the open source DuckDB in-process analytical database system.
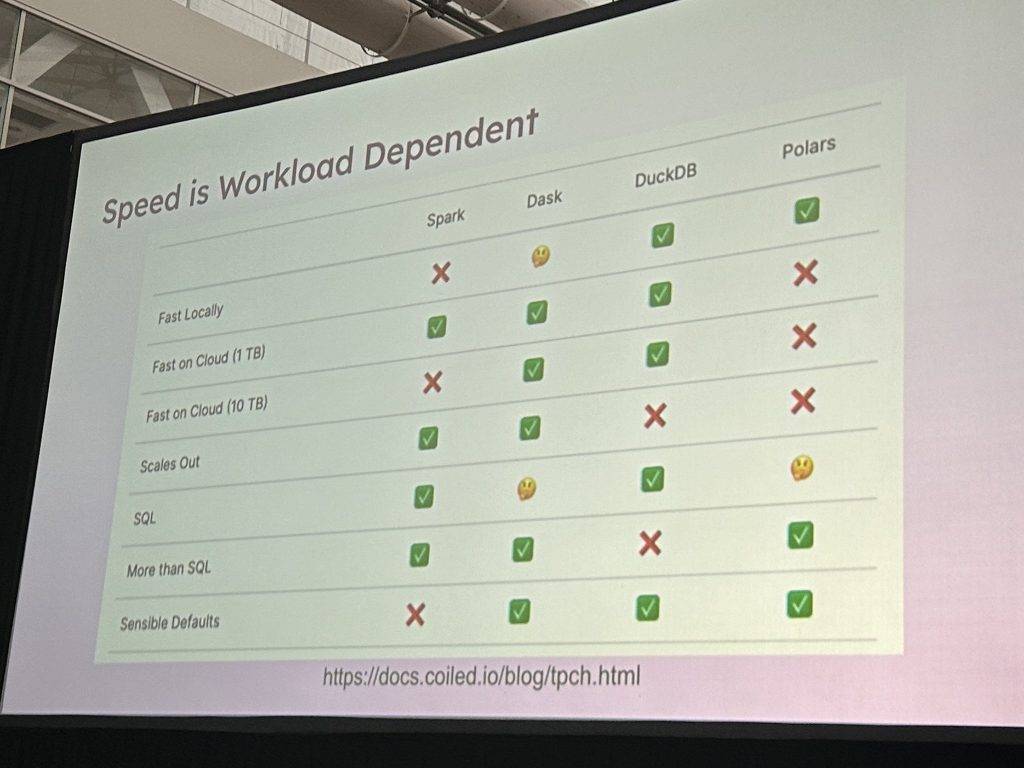
This was one takeaway from a number of presentations comparing the performance of analytics solutions that were given at PyCon, a Python programmer’s conference held last week in Pittsburgh. There, they compared systems and asked, for instance, if a Dask system was faster at analytics than Apache Spark.
But if you can avoid setting up a distributed system altogether, you can avoid a lot of headaches around upkeep.
As explained in a presentation given by Kevin Kho and Han Wang, you can get a lot of mileage from a single machine, if it is optimized correctly. And this is the mission of DuckDB.
In 2021, H20.ai tested DuckDB in a set of benchmarks comparing the processing speed for various database-like tools popular in open source data science.
The testers ran five queries across 10 million rows and nine columns (about 0.5GB). Duck completed the task in a mere two seconds. That was surprising for a database running on a single computer. Even more surprising, it chewed through 100 million rows (5GB) in 14 seconds.
These numbers were impressive, and in 2023, the DuckDB folks went back and tweaked the configuration settings and upgraded the hardware and got the 5GB workload down to two seconds and the 0.5GB in less than a second.
It even tackled the 50GB workload — normally reserved for distributed systems such as Spark — in 24 seconds.
“This is a mind-blowing number. The improvements are amazing,” said Wang, who is the tech lead of Lyft Machine Learning Platform, in the presentation.
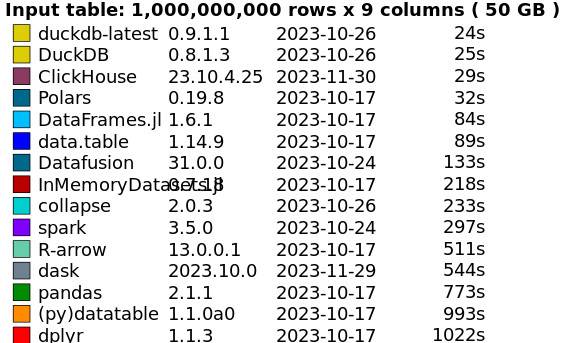
DuckDB’s benchmark of Big Data systems, 2003.
The takeaway? A surprising number of self-styled “big data”-styled projects don’t need Spark or some other distributed solution: They can fit nicely onto a single server, Wang noted. Taking this approach eliminates the considerable overhead of managing a distributed system, and keeps all the data and code on the local machine.
Introducing DuckDB
There’s a lot happening with DuckDB, an analytical, relational in-process SQL database system created in 2018. Two things that immediately set it apart from the other data platforms.
1: It combines SQL with Python, giving developers/analysts an expressive query language that executes against data in the application process itself.
2: It is meant to run only on a single machine. This is a feature, not a bug, as it eliminates all the complexity of running a data platform on a distributed platform.
“As soon as a problem gets a little bit too big for Pandas, you have to throw a giant distributed system at it. It’s like cracking a nut with a sledgehammer. It’s not ergonomic,” saidsaid Alex Monahan, in another Pycon presentation. Monham is a forward-deployed software engineer for MotherDuck, which offers a serverless analytics service based on Duck.
The two creators of DuckDB — Hannes Mühleisen (CEO) and Mark Raasveldt (CTO) — have founded DuckDB Labs, which provides commercial support for the database system, which was designed to offer a fast, easy-to-deploy mid-sized data analysis.
They took considerable inspiration from the little database that could, considering DuckDB to be the SQLite of columns, rather than rows.
With a Python-esque interface, Duck was also built specifically for the data science community. Data will be analyzed, modeled, and visualized. Data scientists tend not to use databases, instead relying on CSV files and other un- or semi-structured data sources. Duck allows them to embed data operations directly into their code itself.
The MIT-licensed open source software is written in C++, so it is fast.
DuckDB is made to go fast, taking advantage of all the server’s cores and cache hierarchies. And whereas SQLite is a row-based database engine that processes one row at a time, Duck can process a whole vector, of 2,048 rows, at one time.
It is a single binary install from the Python Installer It is available for multiple platforms, all pre-compiled so they can be downloaded and run through a command line, or through the client libraries. There’s even a version that runs in a browser via WebAssembly.
It is an in-process application, and writes to disk, meaning it is not limited a server’s RAM, it can use the whole hard drive, opening the path to working with data sizes that are terabytes in size. Unlike a client-server database, it does not rely on a third-party transport mechanism to ship the data from the server to the client. Instead, just like SQLite, the application can pull the data as part of a Python call, in an in-process communication within the same memory space.
“You read it right where it sits,” Monahan said.
You can write data frames natively to the database in a number of different ways, including user-defined functions, a full relational API, the Ibis library to simultaneously write data frames simultaneously across multiple back end data sources, and PySpark but with a different import statement.
How DuckDB and Python Work Together
In addition to the command line, it comes with clients for 15 languages. Python is the most popular, but there is also Node, JBDC, and OBDC. It can read CSV, JSON files, Apache Iceberg files. DuckDB can natively read Pandas, Polaris and Arrow files, without copying the data into another format. Unlike most SQL-only database systems, it keeps the original of the data as it is ingested.
“So this could fit into a lot of workflows,” Monahan said.
It can also read files over the Internet, including those from GitHub (via FTP), Amazon S3, Azure Blob storage and Google Cloud Storage. It can output TensorFlow and Pytorch Tensors.
DuckDB uses a SQL variant that is very Python-esque, one that can ingest data frames natively.
Monahan produced a sample “Hello World” app to illustrate:
will produce the output:
The database uses PostgreSQL as the base, though some modifications were made to the SQL, both for simplifying the language and for extending its capabilities.

The ways DuckDB extends and simplifies SQL (Alex Monahan presentation at Pycon)
Is Big Data Dead?
In summary, DuckDB is a fast database with a revolutionary intent, that of making single computer analytics possible for even very large datasets. It questions the need for Big Data-based solutions.
In a widely-circulated 2023 MotherDuck blog post, provocatively entitled “Big Data Is Dead,” Jordan Tigani noted that “most applications do not need to process massive amounts of data.”
“The amount of data processed for analytics workloads is almost certainly smaller than you think,” he wrote. So it makes sense to look at a simple single computer-based analytics software before jumping into a more expensive data warehouse or distributed analytics system.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.