
包阅导读总结
1. `Apache Kafka`、`KIP-932`、`KMQ`、`Share Groups`、`Message Consumption`
2. 本文主要介绍了 Apache Kafka 在实现类似队列使用场景方面的工作,包括 KIP-932 引入的共享组和 SoftwareMill 开发的 KMQ 方案。指出 Kafka 高性能但灵活性不足,新方案旨在解决消息消费相关问题,KIP-932 预计在 Kafka 4.0 中实现,KMQ 则可用于当前及过往版本。
3.
– Apache Kafka 社区在 KIP-932 中为实现队列使用场景引入共享组抽象,用于合作消息消费。
– 共享组采用不同分区分配方式,无独占限制,简化再平衡过程,支持更细粒度消息跟踪。
– 计划在 Kafka 4.0 中包含此功能。
– SoftwareMill 开发的 KMQ 是另一种方案,可用于当前和过去的 Kafka 版本。
– 它利用 Kafka 消费者组功能实现个体消息确认,有额外组件负责标记消息。
– 引入一些延迟,但性能类似常规消费者组,未解决行首阻塞问题,并行仍受分区数限制。
思维导图: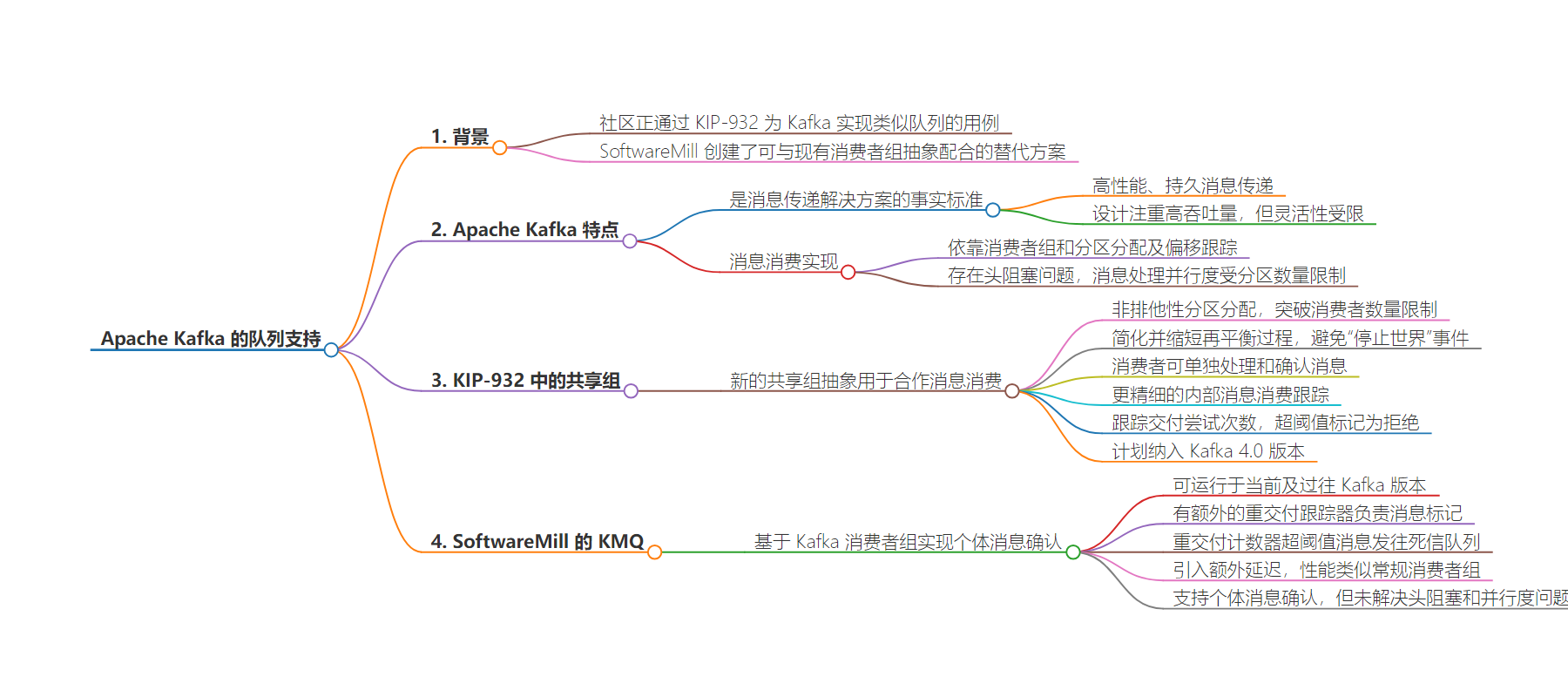
文章来源:infoq.com
作者:Rafal Gancarz
发布时间:2024/7/16 0:00
语言:英文
总字数:705字
预计阅读时间:3分钟
评分:90分
标签:Apache Kafka,KIP-932,KMQ,SoftwareMill,消息系统
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
The Apache Kafka community is actively working on enabling queue-like use cases for a popular messaging platform as part of the ongoing KIP-932 (Kafka Improvement Proposal). The proposal introduces a share group abstraction for cooperative message consumption. Meanwhile, SoftwareMill created an alternative solution that can work with the existing consumer group abstraction.
Apache Kafka has been a de facto standard for messaging solutions for many years, primarily because of its high-performance, durable message delivery. Kafka’s design is geared towards supporting high throughput by limiting communication overheads and data transformations. High performance comes at the cost of flexibility, so some processing use cases, such as individual message delivery acknowledgments, are not supported.
Apache Kafka implements message consumption using consumer groups and relies on the exclusive assignment of topic partitions to consumers in the consumer group and partition offset tracking. This design introduces a head-of-line blocking problem, where slow or blocked processing of a single message can impact or even stall the consumer application. Additionally, the parallelism of message processing is limited by the number of partitions, so this number has to be carefully determined upfront, considering the desired throughput.
/filters:no_upscale()/news/2024/07/apache-kafka-queues/en/resources/1softwaremill-kafka-queues-1721115833833.jpeg)
Share Groups in Apache Kafka (Source: SoftwareMill Blog)
KIP-932: Queues For Kafka proposal outlines a new approach toward cooperative message consumption by introducing a new abstraction of share groups. Share groups use a different partition assignment approach where the assignment is not exclusive, which removes the limitation for the number of consumers compared to the number of partitions. It also simplifies and shortens the rebalancing process and avoids the “stop the world”fencing events.
Additionally, with share groups, consumers can individually process and acknowledge messages, and Kafka can internally track message consumption at a much more granular level. When asked for available messages, Kafka share-partition returns a batch of messages marked as acquired, and these remain in that state until the consumer acknowledges them or the processing time limit is hit. If the latter happens, messages will be marked as available again.
Kafka also tracks the number of delivery attempts and marks the message as rejected if the number of delivery attempts exceeds the threshold. For now, the Dead Letter Queue (DLQ) functionality is not available to capture undelivered messages, but it may be added in the future. Kafka brokers maintain and persist all the internal state required to track message delivery at the individual level in a dedicated internal topic. Share groups functionality is planned to be included in the Kafka 4.0 release.
For the impatient who do not want to wait for KIP-932 to be shipped in Kafka 4.0, there is an alternative option that works with current and past Kafka versions. Adam Warski, chief R&D officer at SoftwareMill, introduces the solution:
KMQ is a pattern for implementing individual message acknowledgements, using the functionality provided by Kafka’s consumer groups. Hence, it might be run using any Kafka version. You might notice some similarities in KMQ’s and share groups’ designs. However, KMQ is significantly simpler to implement and deploy, which also means it addresses only some of the shortcomings of consumer groups. KMQ is entirely a consumer-side mechanism, as opposed to significant logic being run as part of share group brokers.
KMQ uses an additional component, the Redelivery Tracker, that is responsible for marking the messages as delivered and acknowledged, similar to share groups but happening on the application side. The tracker relies on a dedicated “markers”topic and a separate consumer group and takes care of republishing messages back to the topic it’s tracking in case of processing timeouts. If the redelivery counter, which is a part of the internal state maintained for each message, exceeds the configured threshold, the message is published into the configured Dead Letter Queue (DLQ) topic.
/filters:no_upscale()/news/2024/07/apache-kafka-queues/en/resources/1softwaremill-kmq-1721115833833.jpeg)
KMQ Pattern Design (Source: SoftwareMill Blog)
Since the KMQ solution needs to publish markers into the dedicated topic, it introduces some additional latency but can achieve throughput similar to that of regular consumer groups in performance benchmarks conducted by the project team. The KMQ pattern’s main benefit is that it supports individual message acknowledgment with currently available Kafka client versions while offering high performance. However, the pattern doesn’t address the head-of-line blocking issue, and the parallelism is still limited by the number of partitions.