
包阅导读总结
1. 关键词:Cloud Storage、Hierarchical Namespace、Folder Operations、Performance、Key Use Cases
2. 总结:本文介绍了 Cloud Storage 分层命名空间,对比传统方式说明了其优势,包括快速和原子性的文件夹操作、提升性能等,列举了关键优势、使用场景、其他考虑因素,并介绍了如何开始使用,还期待用户反馈。
3. 主要内容:
– Cloud Storage 分层命名空间
– 传统与现有方式的对比
– 传统文件系统文件夹重命名快速且原子
– 现有云存储桶操作慢且非原子,可能导致不一致状态
– 分层命名空间的特点
– 有支持的 API,新的‘Rename Folder’操作是元数据操作,快速且原子
– 关键优势
– 提升性能,初始桶请求速率更高
– 文件导向增强,支持新 API 和资源
– 平台支持,与多种服务集成
– 主要使用场景
– Hadoop 处理等依赖文件系统结构的应用
– 文件导向的批处理分析等工作负载
– AI 和 ML 处理工具
– 其他考虑
– 创建时启用,不支持某些特性
– 预览阶段的限制和支持方式
– 预览无额外收费,GA 后有收费
– 开始使用
– 创建启用分层命名空间的桶并测试,反馈
思维导图: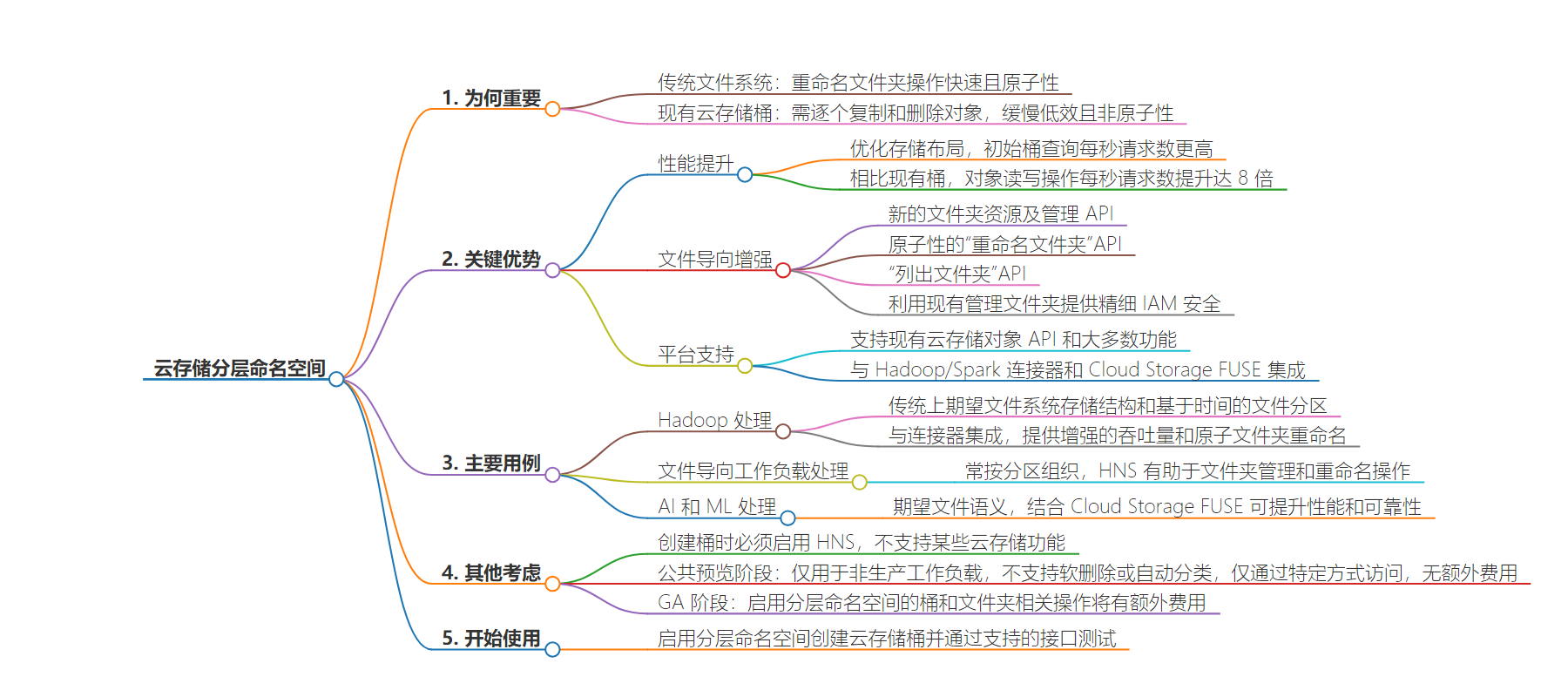
文章来源:cloud.google.com
作者:Vivek Saraswat,Zhihong Yao
发布时间:2024/6/19 0:00
语言:英文
总字数:1073字
预计阅读时间:5分钟
评分:91分
标签:云存储,分层命名空间,谷歌云,数据传输
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Why does this matter? Let’s say you want to “move” a folder by renaming its path. In a traditional file system, that operation is usually fast and atomic, meaning that either the rename succeeds and all the folder contents also have their paths renamed, or the operation fails and all the contents keep the original path name.
In contrast, in an existing Cloud Storage bucket, each of the objects underneath the simulated folder needs to be individually copied and deleted. If your folder contains hundreds or thousands of objects, this is slow and inefficient. It is also non-atomic — if the process fails midway through, your bucket could be left in an incomplete state where the folder is in two places and only some of the objects have moved. This can be very painful for data-intensive workloads that programmatically rename hundreds or thousands of large folders on a regular basis.
A bucket with hierarchical namespace has storage folder resources backed by an API, and the new ‘Rename Folder’ operation recursively renames a folder and its contents as a metadata-only operation. This ensures the process is fast and atomic, providing improved performance and consistency for folder-related operations when compared to existing buckets.
Key benefits
Improved performance: HNS buckets have an optimized storage layout that delivers higher initial bucket queries per second (QPS). For existing buckets, the Cloud Storage request rate guidelines specify 1000 object write QPS and 5000 object read QPS. HNS buckets deliver up to 8x higher initial bucket requests per second for object read/write operations, making it easier to scale your data-intensive workloads more quickly.
File-oriented enhancements: HNS supports a number of new APIs oriented towards applications optimized for file-oriented storage, such as Hadoop ecosystem tooling or AI/ML workloads. These changes improve performance, resiliency, and convenience for these workloads, and include:
-
A new resource (folder), which acts as a container for objects and other folders, with its own dedicated management API (‘CreateFolder‘/‘DeleteFolder‘/‘GetFolder‘)
-
A new ‘RenameFolder’ API that atomically renames the path of the folder and all of its underlying folders and objects
-
A new ‘ListFolders’ API that lists all folders in the bucket or underneath a specific folder. In a flat bucket, listing prefixes as folders is feasible only by listing all objects at each level of the hierarchy via multiple ‘ListObjects‘ API calls.
-
The ability to leverage existing managed folders capability to provide fine-grained IAM security by “attaching” them to a folder. When you rename a folder, the managed folder moves along with it, ensuring that the IAM permissions move as well.
Platform support: HNS buckets support existing Cloud Storage object APIs and most Cloud Storage features. HNS buckets are also integrated with the Cloud Storage connector for Hadoop/Spark (including Dataproc services) workloads and Cloud Storage FUSE for file system-like bucket access via clients. Since HNS is enabled only during bucket creation, you can transfer data to an HNS bucket using Storage Transfer Service to take advantage of these benefits with objects that are already provisioned in Cloud Storage.
Key use cases
You should consider enabling hierarchical namespaces for your bucket when using applications that expect file system-like hierarchy and semantics. Examples include:
-
Hadoop-based processing (e.g. Hadoop, Spark, and Hive workloads) traditionally expects a file system storage structure and time-based file partitioning. HNS integrates with the Cloud Storage connector for Hadoop workloads to provide enhanced throughput and atomic folder renames for many data processing pipelines.
-
File-oriented workload processing like batch analytics or high performance computing are often structured into partitions with folders containing many files. HNS can help with folder management, as well as facilitate fast and convenient folder renaming operations.
-
AI and ML processing tools like TensorFlow, Pandas, JAX, and PyTorch often expect file-like semantics. Using HNS (combined with Cloud Storage FUSE for client-level file system access) can enhance performance and reliability for use cases like ML model iteration.
Other considerations
While Cloud Storage hierarchical namespace can provide many benefits for certain types of workloads, you should consider the trade-offs for your environment. HNS must be enabled when you create the bucket, and it does not support certain Cloud Storage features, including object versioning, bucket lock, object retention lock, and object ACLs.
Specifically during the HNS public preview, there are some key considerations to keep in mind. At this stage, the capability is intended for non-production workloads (until it’s GA), and does not yet support soft delete or autoclass features. To understand the benefits of soft delete and options for disabling it on your buckets, you can read more here. HNS is currently accessible only via CLI, supported client libraries, the Cloud Storage Connector for Hadoop/Spark workloads, and Cloud Storage FUSE. UI support is planned later during the preview.
During the public preview, there are no additional charges for HNS. At GA, there will be additional charges for buckets with hierarchical namespace enabled as well as for folder-related operations.
Getting started
You can get started today by creating a Cloud Storage bucket with hierarchical namespace enabled, and test out the capabilities via the supported interfaces listed above. Please see more on the HNS documentation page.
We are eager to hear your feedback about HNS. Please reach out via the “Send Feedback” button on the Cloud Storage HNS documentation page, or directly via cloud-storage-hns-contact@google.com.