
包阅导读总结
1. `Kotlin 协程`、`线程`、`任务流转`、`异步编程`、`事件循环`
2. 作者指出现存 Kotlin 协程资料的问题,总结协程难以描述清楚的原因,提出理解协程难点的化解方法。以线程为例,通过代码示例探讨线程切换的相关问题,澄清概念,指出应使用任务流转代替切线程,最后提到线程池是协程的关键基础之一。
3.
– 现存 Kotlin 协程资料的问题
– 官方文档侧重用法,原理少
– 部分博客文章质量参差不齐
– 部分涉及源码但线索难理解
– 协程难以描述清楚的原因
– 结构化并发写法颠覆
– 引入新概念
– 存在魔法如 suspend
– 恢复概念关键但易被忽略
– 新概念多,技术实现隐蔽
– 理解协程难点的化解方法
– 从基础线程澄清易错概念
– 以异步编程脉络为主线
– 通过模拟实现降低学习曲线
– 引入独特理解和日常场景
– 加入练习
– 线程相关探讨
– 初始线程切换不符合预期
– 加入 join 保证顺序但阻塞主线程无意义
– 通过向任务列表添加任务实现非阻塞式“切”线程
– 解释“切”线程的概念混淆和真实线程工作方式
– 总结应以任务流转代替“切”线程
思维导图: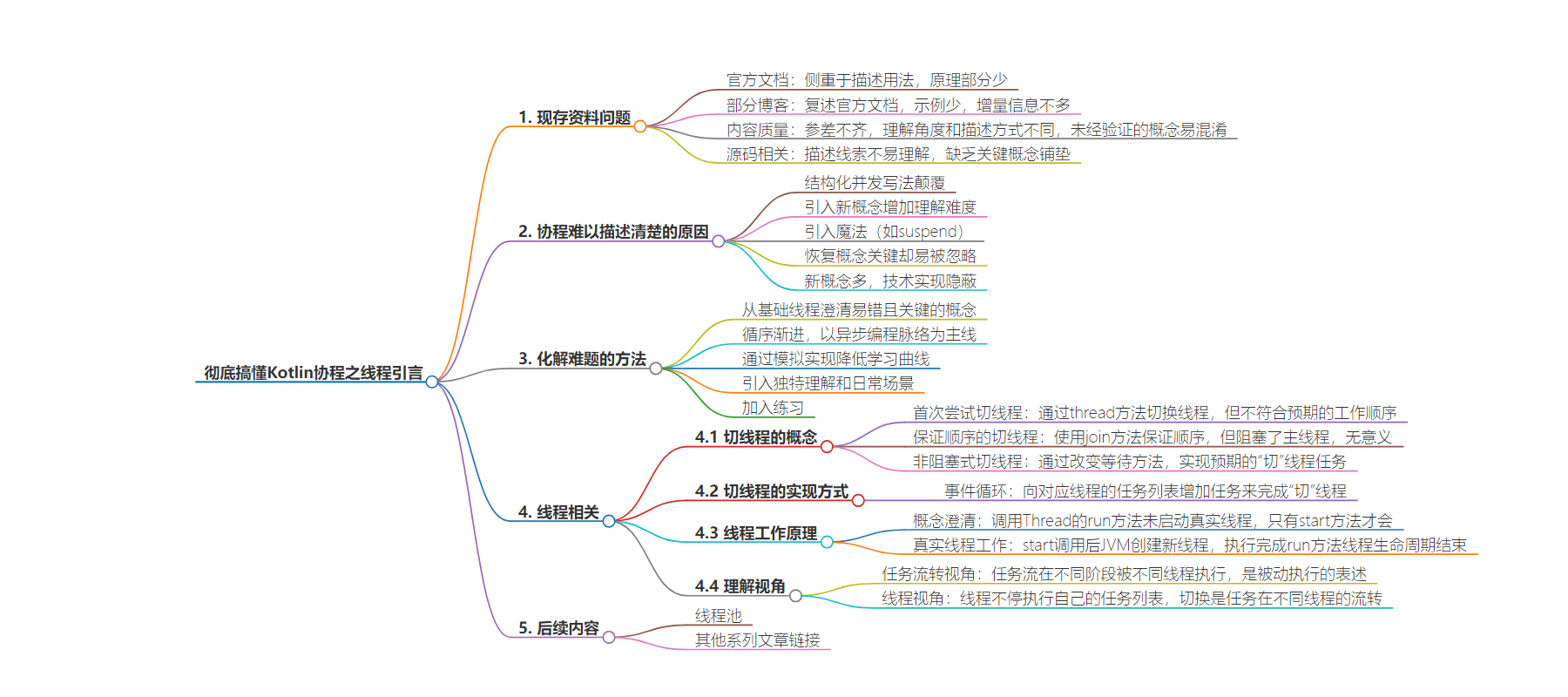
文章地址:https://mp.weixin.qq.com/s/xjqeLaDLbM8JFdzG93anYw
文章来源:mp.weixin.qq.com
作者:hunterXYZ
发布时间:2024/7/22 2:56
语言:中文
总字数:4152字
预计阅读时间:17分钟
评分:88分
标签:Kotlin,协程,线程,异步编程,编程技术
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

引言
当我发现我不停的看到关于Kotlin协程的文章的时候,我突然意识到:可能现有的文章并没有很好的解决大家的一些问题。在看了一些比较热门的协程文章之后,我确认了这个想法。此时我想起了一个古老的笑话:当一个程序员看到市面上有50种框可用架的时候,决心开发一种框架把这个框架统一起来,于是市面上有了51种框架我最终还是决定:干,因为异步编程实在是一个过于重要的部分。
我总结了现存资料所存在的一些问题:
-
官方文档侧重于描述用法,涉及原理部分较少。如果不掌握原理,很难融会贯通,使用时容易 踩坑 -
部分博客文章基本是把官方文档复述一遍,再辅之少量的示例, 增量信息不多 -
不同的博客文章之间内容质量参差不齐,理解角度和描述方式各不相同,部分 未经验证的概念反而混淆了认知,导致更加难以理解 -
部分博客文章涉及大量源码相关内容,但描述 线索不太容易理解,缺乏循序渐进的讲述和一些关键概念的铺垫和澄清
而为什么 coroutine 如此难以描述清楚呢?我总结了几个原因:
-
协程的结构化并发写法(异步变同步的写法)很爽,但与之前的经验相比会过于颠覆,难以理解 -
协程引入了不少之前少见的概念,CoroutineScope,CoroutineContext… 新概念增加了理解的难度 -
协程引入了一些 魔法,比如 suspend,不仅是一个关键字,更在编译时加了料,而这个料恰好又是搞懂协程的关键 -
协程的恢复也是非常核心的概念,是协程之所以为协程而不单单只是另一个线程框架的关键,而其很容易被一笔带过 -
因为协程的“新”概念较多,技术实现也较为 隐蔽,所以其主线也轻易的被掩埋在了魔法之中
那么在意识到了理解协程的一些难点之后,本文又将如何努力化解这些难题呢?我打算尝试以下一些方法:
-
从基础的线程开始, 澄清一些易错而又对理解协程至关重要的概念,尽量不引入对于理解协程核心无关的细节 -
循序渐进,以异步编程的发展脉络为主线,梳理引入协程后解决了哪些问题,也破除协程的高效率迷信 -
物理学家费曼有句话:“What I cannot create, I do not understand”,我会通过一些简陋的 模拟实现,来降低协程陡峭的学习曲线 -
介绍一些我自己的 独特理解,并引入一些日常场景来加强对于协程理解 -
加入一些 练习。如看不练理解会很浅,浅显的理解会随着时间被你的大脑垃圾回收掉,陷入重复学习的陷阱(这也是本系列标题夸口「最后一次」的原因之一)
希望通过上面的方式可以让大家更好的理解 Kotlin Coroutine。那么下面我们进入第一个正题
线程
❝
什么叫做切线程?
为什么要切线程?
如何切线程?
❞
上来就是灵魂三问,我们先看看第一个问题,什么叫切线程。切线程那还不简单吗,直接上代码:
//Thread1.kt
funmain(){
printlnWithThread("dowork1")
switchThread()
printlnWithThread("dowork3")
}
funswitchThread()=thread{
printlnWithThread("dowork2")
}
funprintlnWithThread(message:String){
println("${Thread.currentThread().name}:$message")
}
//log
main:dowork1
main:dowork3
Thread-0:dowork2
switchThread 中使用的 thread 方法为 kotlin 对 new Thread and start 的封装,从 log 可以看到 work2 的确在是新线程上运行的,所以我们切换线程成功。
那这符合我们的很多时候“切”线程的预期吗?好像并没有。当我们“切”线程的时候,预期往往是:先在 main 线程上 do work1,然后在 new thread 上 do work2,再在 main 上 do work3,日志应该像下面这样:
//log
main:dowork1
Thread-0:dowork2
main:dowork3
因为工作之间往往有顺序依赖性,并不是完全孤立的,比如我想先设置一个loading的状态,再从后台获取一个数据,最后再根据获取的数据在界面上展示出来,明显这个顺序是不能颠倒的。所以我们希望在“切”线程的时候依然能保证 sub work 之间的顺序性。
如果我们想要完成上面的这个任务,可以做如下修改:
//Thread2.kt
funmain(){
printlnWithThread("dowork1")
valnewThread=switchThread2()
newThread.join()
printlnWithThread("dowork3")
}
funswitchThread2()=thread{
printlnWithThread("dowork2")
}
//log
main:dowork1
Thread-0:dowork2
main:dowork3
现在工作流程符合我们的要求了,“切”线程成功。不过似乎还是有哪里不太对?我们想要“切”线程的时候,往往是因为 work2 是一个耗时任务,我们不想阻塞 main 线程。那么上面这种“切”线程就完全没有意义了,通过 join 等待其他线程完成还不如就在同一个线程干完就行了。
那如果要实现我们“非阻塞式”的要求,又要怎么办呢?耗时是不得不接受的客观条件,而上面的等待是用于保证顺序性的方法。很明显,我们只能改变等待这个方法。main 线程完成 work1 之后先不急着做 work3,main 线程也不要 “干等” work3,而是先去做点其他的工作,(我们只需要在一个 work流 内的 work1,work2,work3 之间保持顺序,如果其他工作也需要跟这些 work 保持顺序,说明他们也应该在这个工作流内),等 newThread 完成 work2 之后“通知” main 线程,main 线程再在合适的时机继续完成 work3,我们再次修改示例:
//Thread3.kt
valwork=Runnable{
printlnWithThread("dowork1")
switchThread3()
}
valotherWork1=Runnable{
Thread.sleep(100)//模拟耗时,避免main方法中work结束太早,newThread添加work3失败
printlnWithThread("doworka")
}
valotherWork2=Runnable{
printlnWithThread("doworkX")
}
//preventConcurrentModificationException
valworks=ConcurrentLinkedQueue<Runnable>()
funmain(){
works.addAll(listOf(work,otherWork1,otherWork2))
works.forEach{it.run()}
}
funswitchThread3()=thread{
printlnWithThread("dowork2")
works.add(Runnable{printlnWithThread("dowork3")})
}
//log
main:dowork1
Thread-0:dowork2
main:doworka
main:doworkX
main:dowork3
在 main方法中,main 线程依次执行完成 work里的 work1, otherWork1, otherWork2,在 work 里启动了一个 newThread 执行 work2,完成 work2 之后 newThread 通过向 main 线程的任务列表添加任务的方式又”切“了一次线程,「同时」 main 线程正在执行 otherWork1,然后是 otherWork2,最后是 newThread 向 main 线程添加的 work3。从log 可以看出,我们最终完成了我们预期的“切”线程的任务。work 保持了 work1,work2,work3 的顺序工作流,而且也没有通过 main 线程“干等”的方式来保证 subwork 之间的同步性,参考下图:
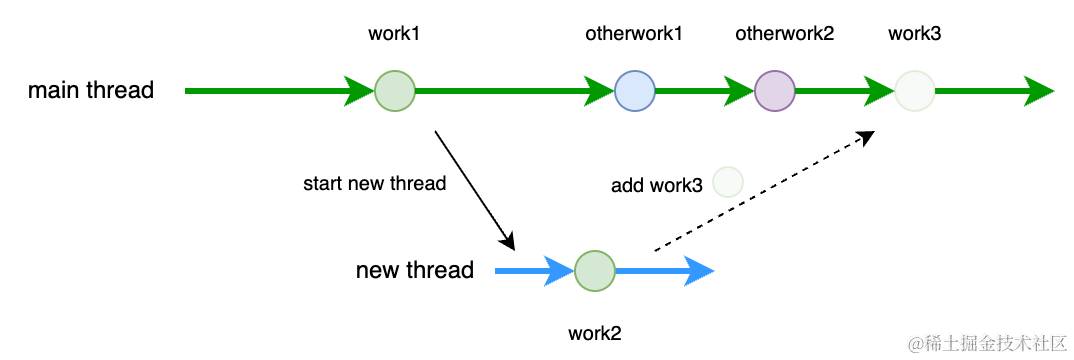
切线程模型
很多同学可能已经发现了,这不就和 android 的 Handler 类似嘛,就像下面的例子:
//Thread4.kt
funmain(){
printlnWithThread("dowork1")
switchThread4()
}
funswitchThread4()=thread{
printlnWithThread("dowork2")
Handler(Looper.getMainLooper()).post{
printlnWithThread("dowork3")
}
}
//log
//注意上面代码无法通过main方法直接正常运行,因为JVM的Runtime不包含android相关的环境,所以会抛异常
main:dowork1
Thread-0:dowork2
Exceptioninthread"Thread-0"java.lang.RuntimeException:Stub!
Handler通过 Looper 来循环执行任务,只不过 Looper 是无限循环,不需要通过 Thread3.kt 示例里面加一个 sleep 来模拟耗时任务以防止添加任务失败,我们将任务 post 过去后就会被执行。看来我们可以通过向对应线程的任务列表增加任务的方式来完成“切”线程,其实这种方式有一个专门的术语,叫做「事件循环」(event loop),我们在线程池以及 Kotlin Coroutine 中都会看到他的身影。
我们看看上面 Thread3.kt 是如何实现“切”线程的:
-
在 main 线程里通过 new Thread 的方式先“切”了一次线程 -
然后 new Thread 在完成了 work2 之后又通过向 main 线程添加任务的方式把线程”切”了回来
这里我们看到了两种不同的“切”线程的方式。但无论是 main 线程或者 newThread 都在兢兢业业的完成自己的工作,没有感觉到自己被“切”了。其实我们无法实现直觉中的“切”线程,像下面的例子这样:
//Thread5.kt
funmain(){
printlnWithThread("dowork1")
valwork2=Runnable{
printlnWithThread("dowork2")
}
valnewThread=Thread(work2)
newThread.run()//编译器警告:Calls to 'run()' should probably be replaced with 'start()'
printlnWithThread("dowork3")
}
//log
main:dowork1
main:dowork2
main:dowork3
即使 work2 是通过 newThread.run 执行的,work2 也是由 main 线程执行的。为什么会这样呢?这里其实有一个微妙的概念混淆:在 Java 里,当我们谈到 Thread 时,既可能说的是我们熟悉的那个分配 CPU 资源最小单位的真实线程,又可能说的是一个普通的 Java Thread 类,在这里我们只是调用了 Thread 类的一个 run 方法,从始至终没有启动一个真实线程,只有一个叫做 newThread 的普通 Java 对象。
概念澄清之后,我们再看看“真实线程”是如何工作的。下面这句话只是帮助理解,请谨慎参考:
❝
当调用了 Thread 的 start 方法之后,JVM 才会去分配资源创建一个新的线程, 这个 newThread 对象只是作为连接被创建出来的线程的对象,通过这个对象可以部分地操作创建出来的线程,这个新创建的线程自己以 newThread 对象作为起点开始运行。
❞
当我们通过 start 调用了启动线程之后,work并不会被马上执行,剩下由 JVM 来控制,当这个新线程执行完成了 newThread 对象的 run 方法后, 这个线程的生命周期也就走到了尽头。上面的 newThread 并没有 start,所以上面的 work2 是在 main 线程执行的。其实两者完全可以同时存在,我们看看结合这两者的示例:
//Thread6.kt
funmain(){
printlnWithThread("dowork1")
valwork2=Runnable{
printlnWithThread("dowork2")
}
valnewThread=Thread(work2)
newThread.run()//编译器警告:Calls to 'run()' should probably be replaced with 'start()'
printlnWithThread("dowork3")
//startandjoin
newThread.start()
newThread.join()
}
//log
main:dowork1
main:dowork2
main:dowork3
Thread-0:dowork2
与上一个例子对比,我们通过 newThread.start() 启动新线程来执行的 work2 就不是在main 线程执行的。
总结
线程执行到哪个任务,这个任务的上下文(Context)就会被染色为这个线程,线程就是一个“无情”的执行机器,我们无法“切”线程,只能通过改变任务被执行的Context(在这里就是线程)来完成我们的任务,也就是通过流转任务(Kotlin Coroutine 里是由 CoroutineDispatcher 负责)到不同的线程上来“切”线程,我们不能对线程执行某种类似于“切”的动作。
相信讲到这里关于“切线程”的灵魂三问的答案就已经清晰了。我们再审视一下上面 Thread3.kt 中的示例,可以看到线程没有被“切换”,反倒是本来完整的 work 被”切分” 到了不同的 Runnable 上,并通过在不同的线程上来执行达成所谓的“切线程”。所谓“切换”线程其实是站在任务流的视角,同一个任务流在不同的阶段被不同的线程执行,这是一种把实际被动的执行方式强行表述为主动的切换,这也是用“切”线程这个概念去理解 kotlin coroutine 的会感觉别扭的原因之一。而如果我们站在线程的视角来理解,整个系统就会更加简洁:线程只是不停的执行自己的任务列表,所谓的切换,不过是任务流在不同线程的任务列表里的流转而已。
关于参照系引起的理解差异,一个很好的例子是地心说与日心说的模型差别下图可以看到通过日心说来解释太阳系的星体运行轨迹会比地心说看起来简洁、和谐许多。所以之后我将不再使用“切线程”这个术语,而使用任务流转来代替。到这里我们关于线程以及“切”线程这个概念的澄清也就结束了。

地心说与日心说天体轨迹
前面我们提到了线程池,可以解决本文实例中的一些问题。线程池是异步框架的一个里程碑,也是 kotlin coroutine 的关键基础之一,我们下一节线程池见。
「示例源码」:https://github.com/chdhy/kotlin-coroutine-learn
「练习」:实现上面几个例子,可以体会到思考方式从“切”线程到“任务流转”的转变
「点赞👍」文章,「关注❤️」 笔者,获取其他文章更新
-
「最后一次,彻底搞懂kotlin协程」(一) | 先回到线程
-
「最后一次,彻底搞懂kotlin协程」(二) | 线程池,Handler,Coroutine
-
「最后一次,彻底搞懂kotlin协程」(三) | CoroutineScope,CoroutineContext,Job: 结构化并发
-
「最后一次,彻底搞懂kotlin协程」(四) | suspend挂起,EventLoop恢复:异步变同步的秘密
-
「最后一次,彻底搞懂kotlin协程」(五) | Dispatcher 与 Kotlin 协程中的线程池
-
「最后一次,彻底搞懂kotlin协程」(六) | 全网唯一,手撸协程!
-
「最后一次,彻底搞懂kotlin协程」(七) | 五项全能 🤺 🏊 🔫 🏃🏇:Flow
-
「最后一次,彻底搞懂kotlin协程」(八) | 深入理解 Flow