包阅导读总结
1. 关键词:Stream 原理、执行流程、惰性执行、中间操作、终结操作
2. 总结:
本文以一段简单的 stream 操作代码为例,讲解了 Stream 的原理与执行流程。Stream 不存储元素,操作不修改原数据而是生成新流,且操作尽可能惰性执行。通过对代码中各阶段操作的分析,揭示了其流水线式工作模式的特点。
3. 主要内容:
– Stream 原理与执行流程探析
– 介绍以一段常见的 stream 操作代码为例来探究原理
– 指出流不存储元素,操作不修改数据且惰性执行
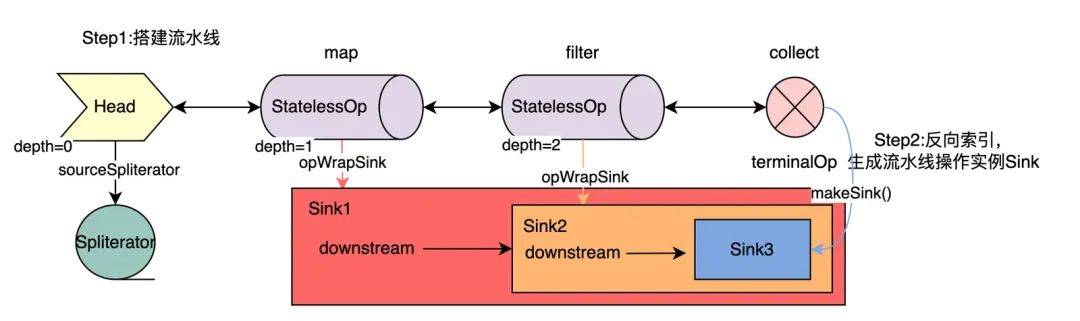
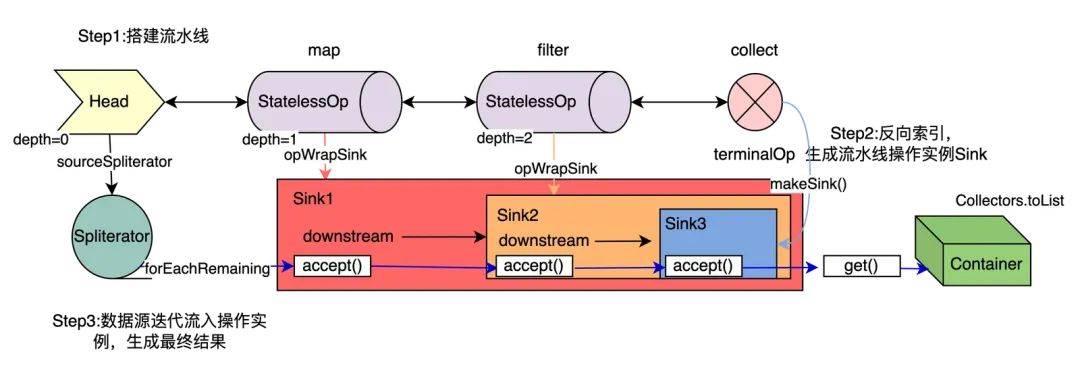
– 讲解流水线包括数据源送入、各阶段处理和生成结果三个阶段
– Stream 整体类图
– Stream 是定义操作的接口,分为中间操作与终结操作
– AbstractPipline 是抽象类,定义流水线节点常用属性
– ReferencePipline 实现 Stream 接口,继承 AbstractPipline 类,并定义三个内部类
– Stream 流水线搭建阶段
– 创建流,如通过 stream()产生 Head
– 进行初始流到其他流的中间操作
– 进行终止操作产生结果
– 举例说明各阶段操作的运行结果及源码分析,如 map、filter、collect 等
– 揭示惰性执行的特点及终结操作的作用
思维导图: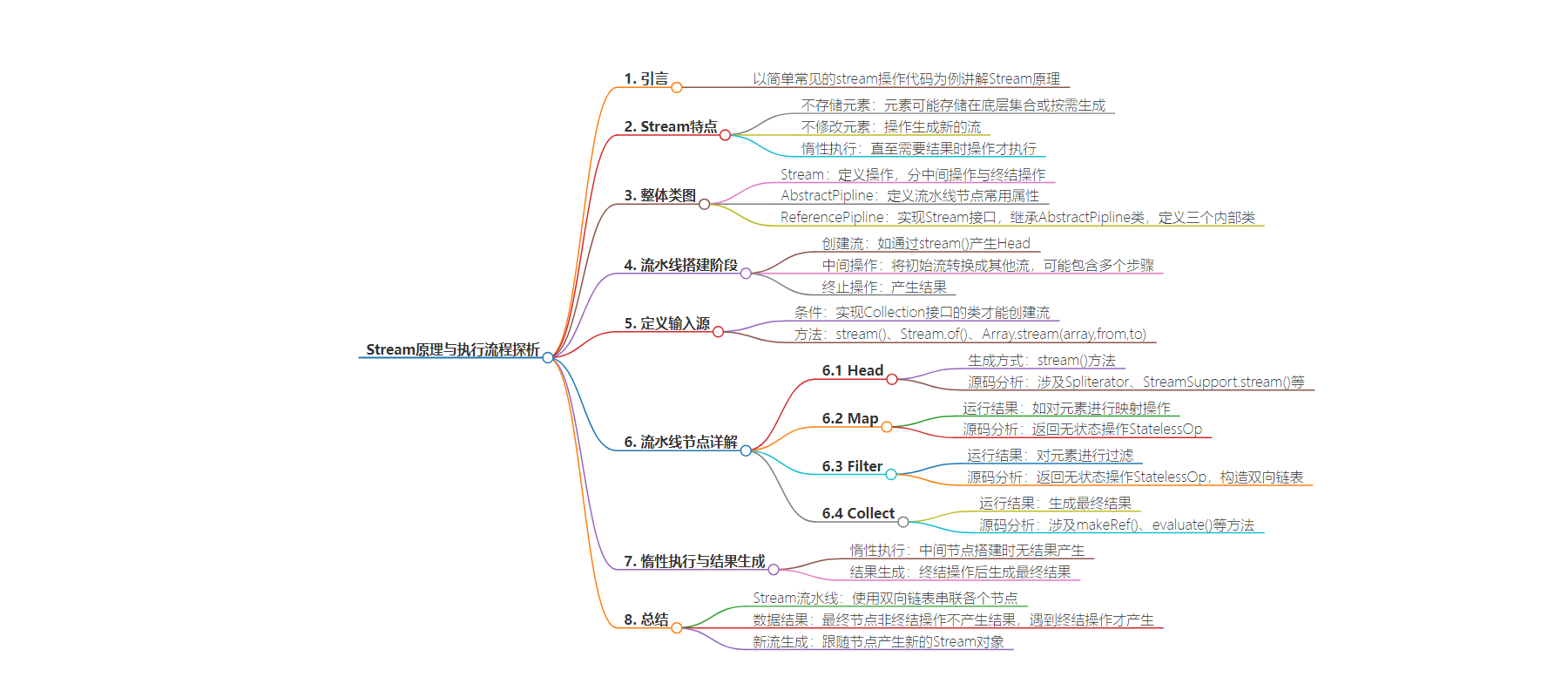
文章地址:https://mp.weixin.qq.com/s/UGWoRO5-pFB0p01mc73wLA
文章来源:mp.weixin.qq.com
作者:始信
发布时间:2024/7/28 9:21
语言:中文
总字数:4083字
预计阅读时间:17分钟
评分:85分
标签:Java,Stream,数据处理,性能优化,惰性执行
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

List<String> startlist = Lists.newArrayList("a","b","c");List<String> endList = startlist.stream().map(r->r+"b").filter(r->r.startsWith("a")).collect(Collectors.toList());
1.流并不存储元素。这些元素可能存储在底层的集合中,或者是按需生成。
2.流的操作不会修改其数据元素,而是生成一个新的流。
3.流的操作是尽可能惰性执行的。这意味着直至需要其结果时,操作才会执行。
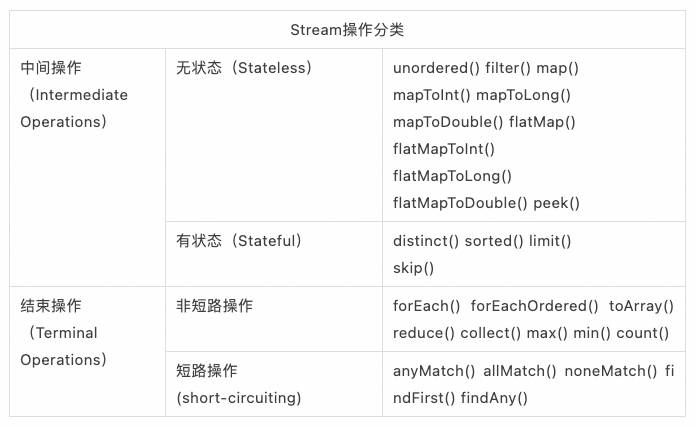
表1:Stream操作分类
1.创建一个流,如通过stream()产生Head,Head就是初始流,数据存储在Spliterator。
2.将初始流转换成其他流的中间操作,可能包含多个步骤,比如上面map与filter操作。
定义输入源HEAD
stream()运行结果
Stream<String> headStream =startlist.stream();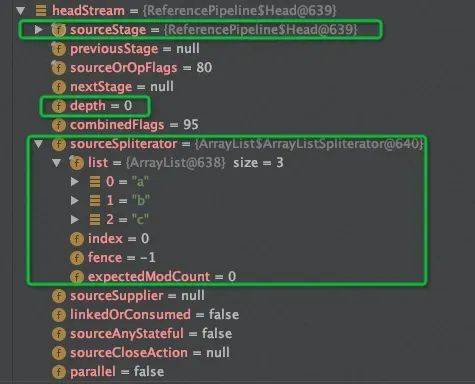
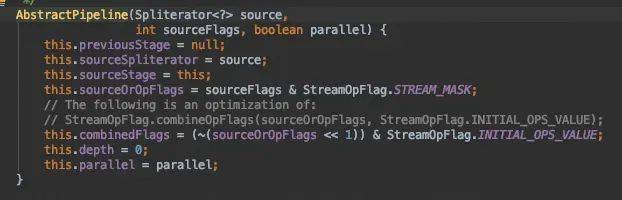
stream()源码分析


StreamSupport.stream()返回了ReferencPipeline$Head类。

定义流水线中间节点
Map
map()运行结果
Stream<String> mapStream =startlist.stream().map(r->r+"b");
map()源码分析
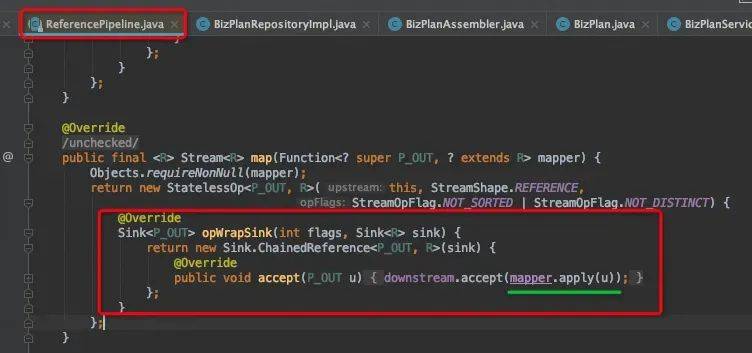
Filter
filter()运行结果
Stream<String> filterStream =startlist.stream().map(r->r+"b").filter(r->r.startsWith("a"));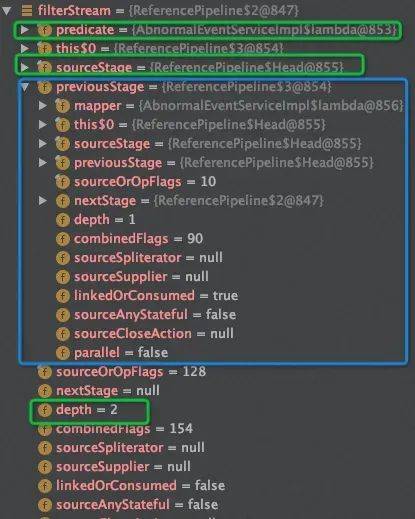
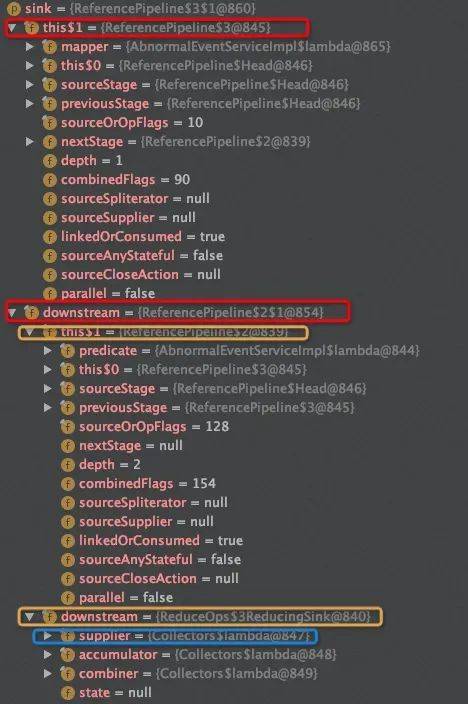
Filter阶段的depth再次+1,sourceStage指向Head,predict指向代码块:
filter()源码分析
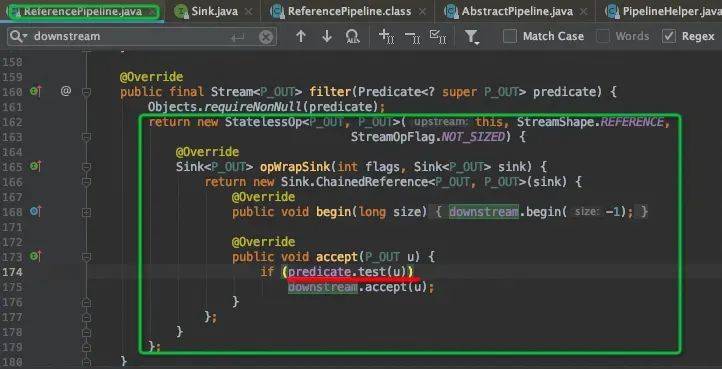

定义终结操作
collect()运行结果
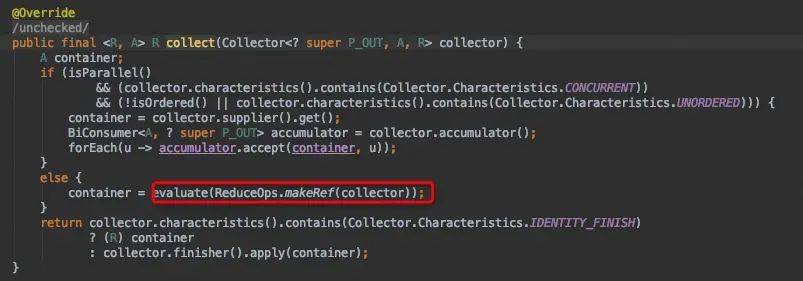
List<String> endList = startlist.stream().map(r->r+"b").filter(r->r.startsWith("a")).collect(Collectors.toList());
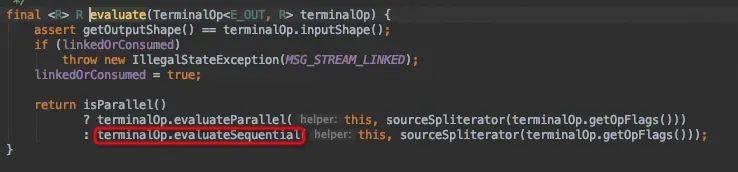
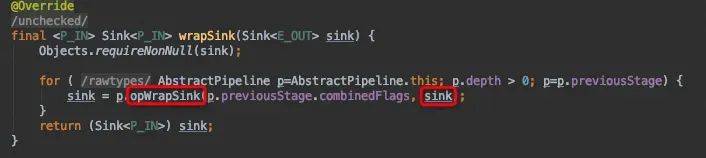
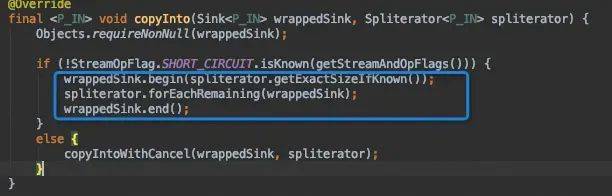
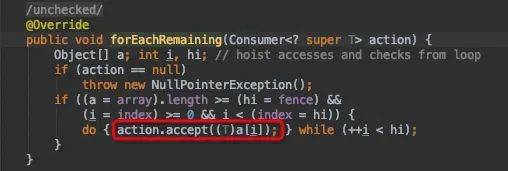
collect()源码分析